 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalk and Read Less: Improving the Efficiency of Vision-and-Language Navigation via Tuning-Free Multimodal Token Pruning
Sep 18, 2025Large models achieve strong performance on Vision-and-Language Navigation (VLN) tasks, but are costly to run in resource-limited environments. Token pruning offers appealing tradeoffs for efficiency with minimal performance loss by reducing model input size, but prior work overlooks VLN-specific challenges. For example, information loss from pruning can effectively increase computational cost due to longer walks. Thus, the inability to identify uninformative tokens undermines the supposed efficiency gains from pruning. To address this, we propose Navigation-Aware Pruning (NAP), which uses navigation-specific traits to simplify the pruning process by pre-filtering tokens into foreground and background. For example, image views are filtered based on whether the agent can navigate in that direction. We also extract navigation-relevant instructions using a Large Language Model. After filtering, we focus pruning on background tokens, minimizing information loss. To further help avoid increases in navigation length, we discourage backtracking by removing low-importance navigation nodes. Experiments on standard VLN benchmarks show NAP significantly outperforms prior work, preserving higher success rates while saving more than 50% FLOPS.
Machine-generated Text Localization
Feb 19, 2024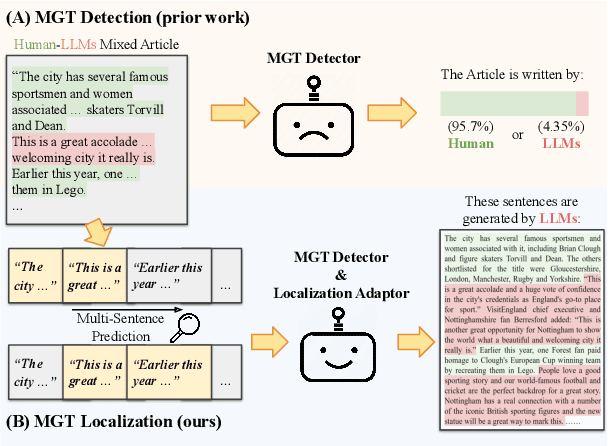
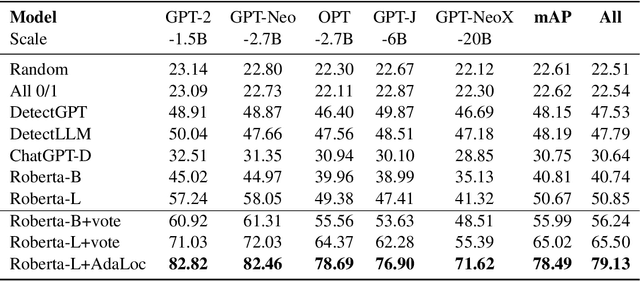
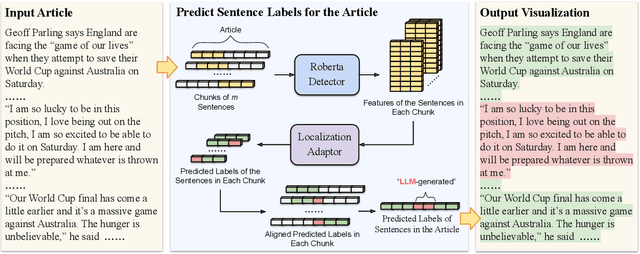
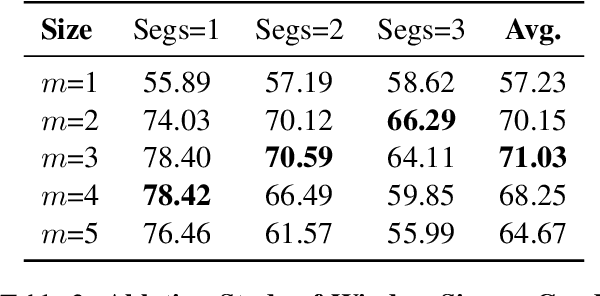
Machine-Generated Text (MGT) detection aims to identify a piece of text as machine or human written. Prior work has primarily formulated MGT as a binary classification task over an entire document, with limited work exploring cases where only part of a document is machine generated. This paper provides the first in-depth study of MGT that localizes the portions of a document that were machine generated. Thus, if a bad actor were to change a key portion of a news article to spread misinformation, whole document MGT detection may fail since the vast majority is human written, but our approach can succeed due to its granular approach. A key challenge in our MGT localization task is that short spans of text, e.g., a single sentence, provides little information indicating if it is machine generated due to its short length. To address this, we leverage contextual information, where we predict whether multiple sentences are machine or human written at once. This enables our approach to identify changes in style or content to boost performance. A gain of 4-13% mean Average Precision (mAP) over prior work demonstrates the effectiveness of approach on five diverse datasets: GoodNews, VisualNews, WikiText, Essay, and WP. We release our implementation at \href{https://github.com/Zhongping-Zhang/MGT_Localization}{this http URL}.
Explore the Potential Performance of Vision-and-Language Navigation Model: a Snapshot Ensemble Method
Nov 28, 2021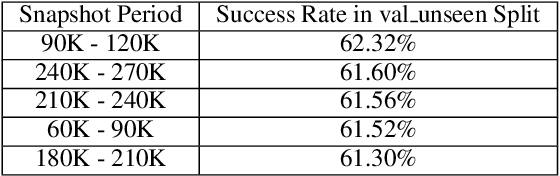
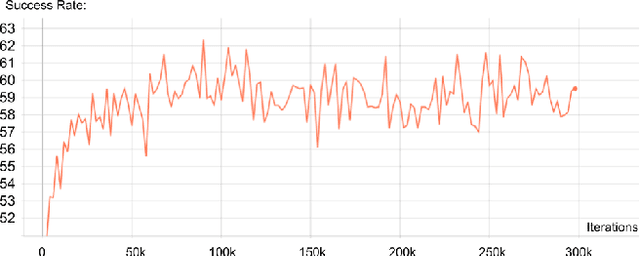
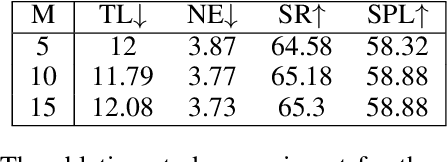
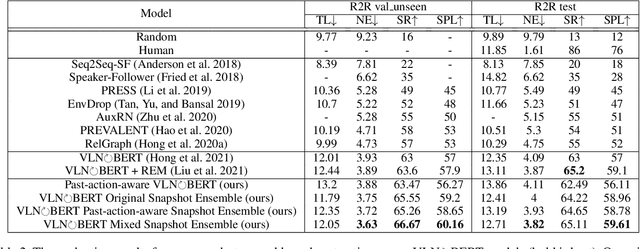
Vision-and-Language Navigation (VLN) is a challenging task in the field of artificial intelligence. Although massive progress has been made in this task over the past few years attributed to breakthroughs in deep vision and language models, it remains tough to build VLN models that can generalize as well as humans. In this paper, we provide a new perspective to improve VLN models. Based on our discovery that snapshots of the same VLN model behave significantly differently even when their success rates are relatively the same, we propose a snapshot-based ensemble solution that leverages predictions among multiple snapshots. Constructed on the snapshots of the existing state-of-the-art (SOTA) model $\circlearrowright$BERT and our past-action-aware modification, our proposed ensemble achieves the new SOTA performance in the R2R dataset challenge in Navigation Error (NE) and Success weighted by Path Length (SPL).