 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Image Manipulation with Background-guided Internal Learning
Paper and Code
Mar 24, 2022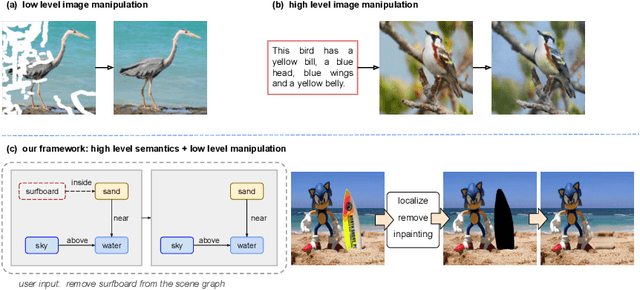



Image manipulation has attracted a lot of interest due to its wide range of applications. Prior work modifies images either from low-level manipulation, such as image inpainting or through manual edits via paintbrushes and scribbles, or from high-level manipulation, employing deep generative networks to output an image conditioned on high-level semantic input. In this study, we propose Semantic Image Manipulation with Background-guided Internal Learning (SIMBIL), which combines high-level and low-level manipulation. Specifically, users can edit an image at the semantic level by applying changes on a scene graph. Then our model manipulates the image at the pixel level according to the modified scene graph. There are two major advantages of our approach. First, high-level manipulation of scene graphs requires less manual effort from the user compared to manipulating raw image pixels. Second, our low-level internal learning approach is scalable to images of various sizes without reliance on external visual datasets for training. We outperform the state-of-the-art in a quantitative and qualitative evaluation on the CLEVR and Visual Genome datasets. Experiments show 8 points improvement on FID scores (CLEVR) and 27% improvement on user evaluation (Visual Genome), demonstrating the effectiveness of our approach.