 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Reinforcement Learning Policies through Counterfactual Trajectories
Jan 29, 2022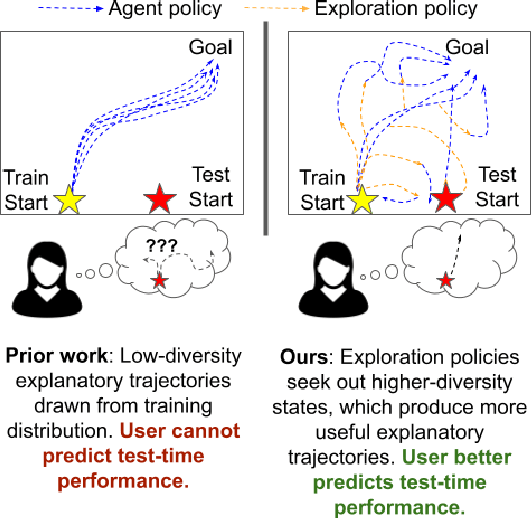
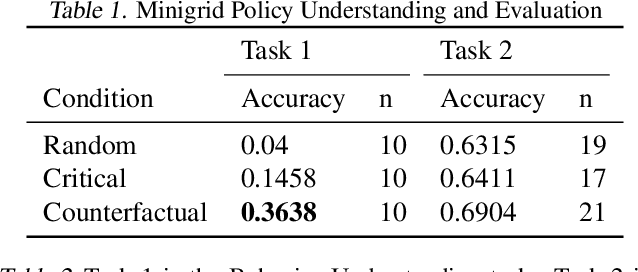
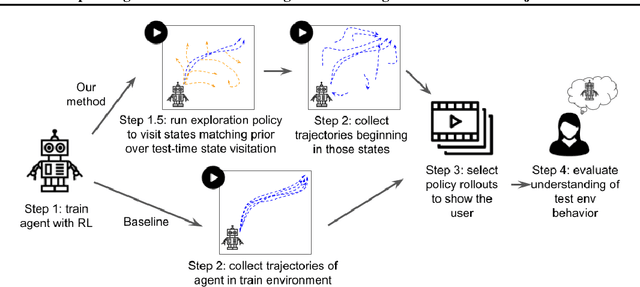

In order for humans to confidently decide where to employ RL agents for real-world tasks, a human developer must validate that the agent will perform well at test-time. Some policy interpretability methods facilitate this by capturing the policy's decision making in a set of agent rollouts. However, even the most informative trajectories of training time behavior may give little insight into the agent's behavior out of distribution. In contrast, our method conveys how the agent performs under distribution shifts by showing the agent's behavior across a wider trajectory distribution. We generate these trajectories by guiding the agent to more diverse unseen states and showing the agent's behavior there. In a user study, we demonstrate that our method enables users to score better than baseline methods on one of two agent validation tasks.
Effectively Leveraging Attributes for Visual Similarity
May 04, 2021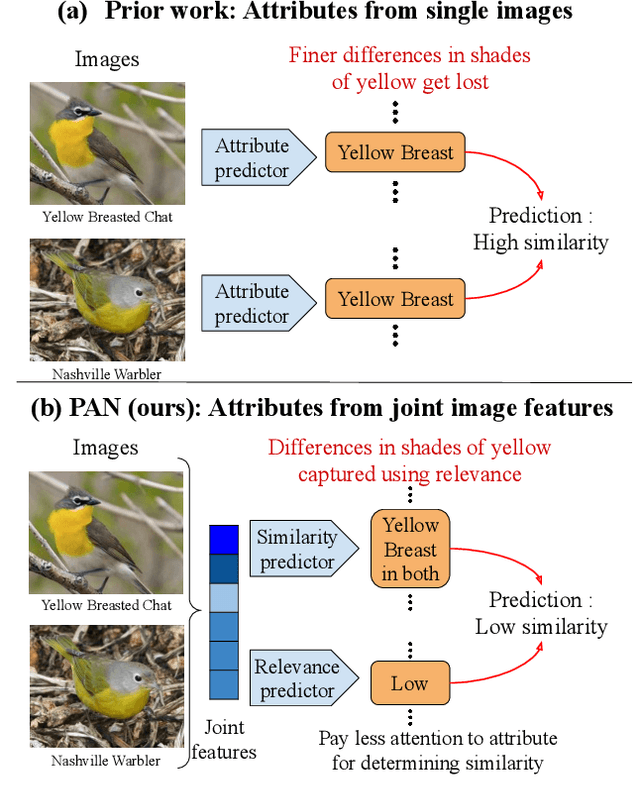
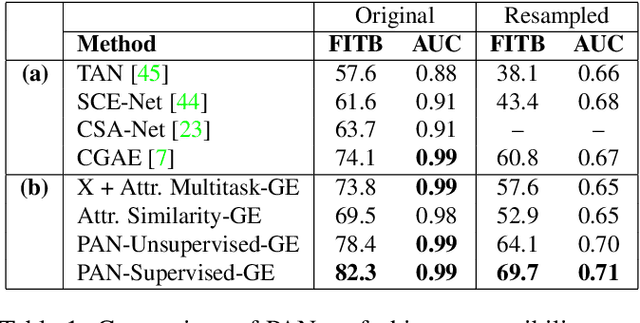


Measuring similarity between two images often requires performing complex reasoning along different axes (e.g., color, texture, or shape). Insights into what might be important for measuring similarity can can be provided by annotated attributes, but prior work tends to view these annotations as complete, resulting in them using a simplistic approach of predicting attributes on single images, which are, in turn, used to measure similarity. However, it is impractical for a dataset to fully annotate every attribute that may be important. Thus, only representing images based on these incomplete annotations may miss out on key information. To address this issue, we propose the Pairwise Attribute-informed similarity Network (PAN), which breaks similarity learning into capturing similarity conditions and relevance scores from a joint representation of two images. This enables our model to identify that two images contain the same attribute, but can have it deemed irrelevant (e.g., due to fine-grained differences between them) and ignored for measuring similarity between the two images. Notably, while prior methods of using attribute annotations are often unable to outperform prior art, PAN obtains a 4-9% improvement on compatibility prediction between clothing items on Polyvore Outfits, a 5\% gain on few shot classification of images using Caltech-UCSD Birds (CUB), and over 1% boost to Recall@1 on In-Shop Clothes Retrieval.
Combining Multiple Cues for Visual Madlibs Question Answering
Feb 07, 2018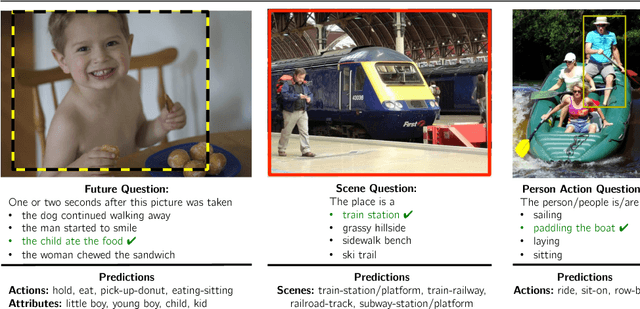
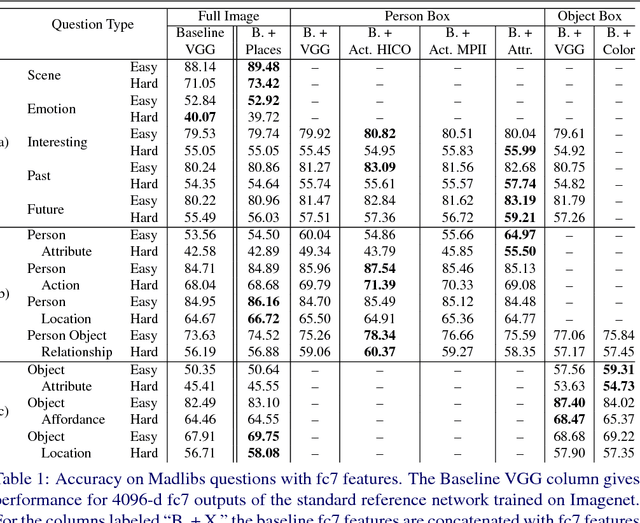

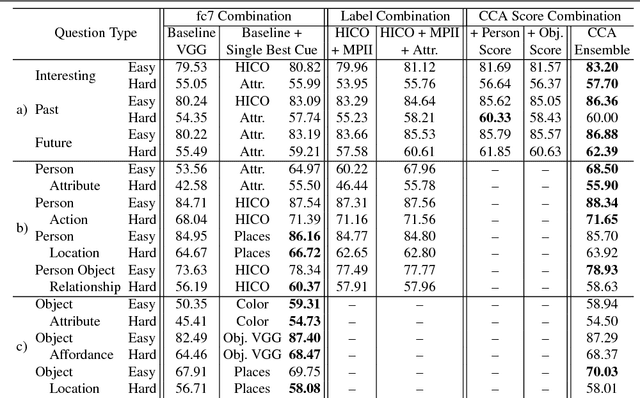
This paper presents an approach for answering fill-in-the-blank multiple choice questions from the Visual Madlibs dataset. Instead of generic and commonly used representations trained on the ImageNet classification task, our approach employs a combination of networks trained for specialized tasks such as scene recognition, person activity classification, and attribute prediction. We also present a method for localizing phrases from candidate answers in order to provide spatial support for feature extraction. We map each of these features, together with candidate answers, to a joint embedding space through normalized canonical correlation analysis (nCCA). Finally, we solve an optimization problem to learn to combine scores from nCCA models trained on multiple cues to select the best answer. Extensive experimental results show a significant improvement over the previous state of the art and confirm that answering questions from a wide range of types benefits from examining a variety of image cues and carefully choosing the spatial support for feature extraction.
Solving Visual Madlibs with Multiple Cues
Aug 11, 2016This paper focuses on answering fill-in-the-blank style multiple choice questions from the Visual Madlibs dataset. Previous approaches to Visual Question Answering (VQA) have mainly used generic image features from networks trained on the ImageNet dataset, despite the wide scope of questions. In contrast, our approach employs features derived from networks trained for specialized tasks of scene classification, person activity prediction, and person and object attribute prediction. We also present a method for selecting sub-regions of an image that are relevant for evaluating the appropriateness of a putative answer. Visual features are computed both from the whole image and from local regions, while sentences are mapped to a common space using a simple normalized canonical correlation analysis (CCA) model. Our results show a significant improvement over the previous state of the art, and indicate that answering different question types benefits from examining a variety of image cues and carefully choosing informative image sub-regions.