 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Visual Madlibs with Multiple Cues
Paper and Code
Aug 11, 2016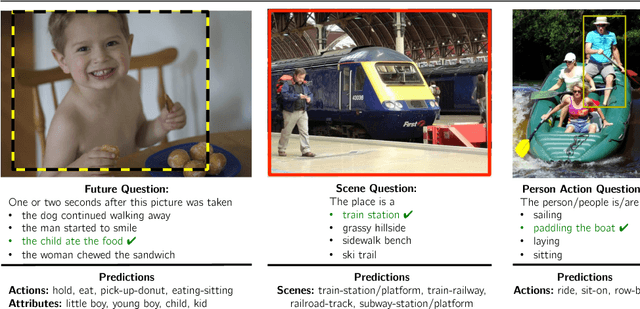
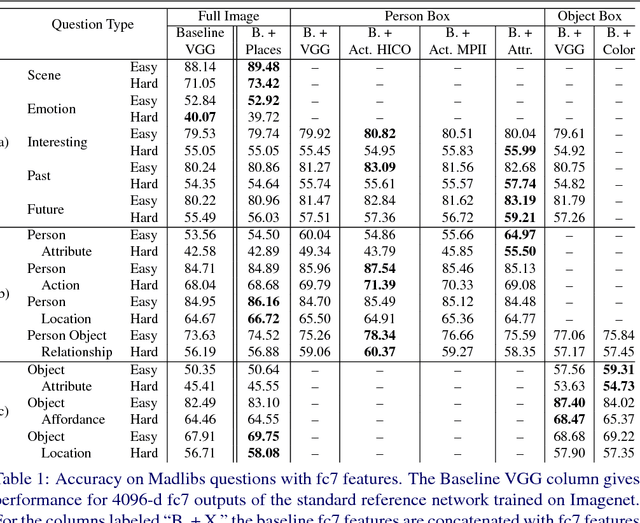

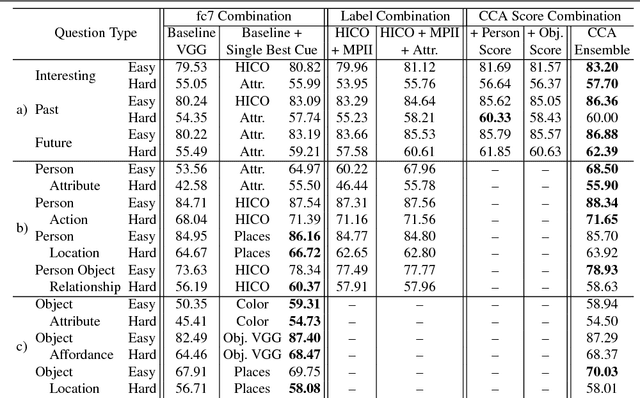
This paper focuses on answering fill-in-the-blank style multiple choice questions from the Visual Madlibs dataset. Previous approaches to Visual Question Answering (VQA) have mainly used generic image features from networks trained on the ImageNet dataset, despite the wide scope of questions. In contrast, our approach employs features derived from networks trained for specialized tasks of scene classification, person activity prediction, and person and object attribute prediction. We also present a method for selecting sub-regions of an image that are relevant for evaluating the appropriateness of a putative answer. Visual features are computed both from the whole image and from local regions, while sentences are mapped to a common space using a simple normalized canonical correlation analysis (CCA) model. Our results show a significant improvement over the previous state of the art, and indicate that answering different question types benefits from examining a variety of image cues and carefully choosing informative image sub-regions.