 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Multiple Cues for Visual Madlibs Question Answering
Paper and Code
Feb 07, 2018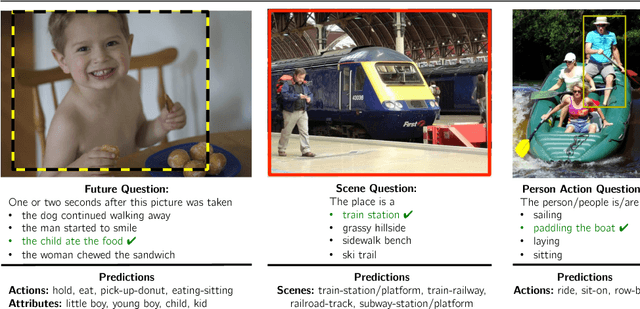
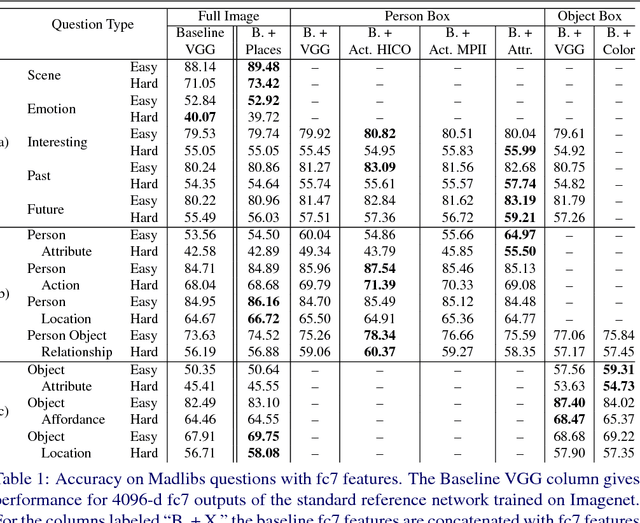

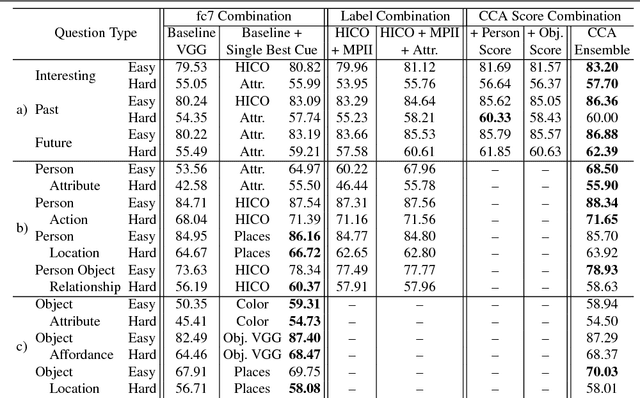
This paper presents an approach for answering fill-in-the-blank multiple choice questions from the Visual Madlibs dataset. Instead of generic and commonly used representations trained on the ImageNet classification task, our approach employs a combination of networks trained for specialized tasks such as scene recognition, person activity classification, and attribute prediction. We also present a method for localizing phrases from candidate answers in order to provide spatial support for feature extraction. We map each of these features, together with candidate answers, to a joint embedding space through normalized canonical correlation analysis (nCCA). Finally, we solve an optimization problem to learn to combine scores from nCCA models trained on multiple cues to select the best answer. Extensive experimental results show a significant improvement over the previous state of the art and confirm that answering questions from a wide range of types benefits from examining a variety of image cues and carefully choosing the spatial support for feature extraction.