 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExeChecker: Where Did I Go Wrong?
Dec 13, 2024In this paper, we present a contrastive learning based framework, ExeChecker, for the interpretation of rehabilitation exercises. Our work builds upon state-of-the-art advances in the area of human pose estimation, graph-attention neural networks, and transformer interpretablity. The downstream task is to assist rehabilitation by providing informative feedback to users while they are performing prescribed exercises. We utilize a contrastive learning strategy during training. Given a tuple of correctly and incorrectly executed exercises, our model is able to identify and highlight those joints that are involved in an incorrect movement and thus require the user's attention. We collected an in-house dataset, ExeCheck, with paired recordings of both correct and incorrect execution of exercises. In our experiments, we tested our method on this dataset as well as the UI-PRMD dataset and found ExeCheck outperformed the baseline method using pairwise sequence alignment in identifying joints of physical relevance in rehabilitation exercises.
Stepwise Weighted Spike Coding for Deep Spiking Neural Networks
Aug 30, 2024Spiking Neural Networks (SNNs) seek to mimic the spiking behavior of biological neurons and are expected to play a key role in the advancement of neural computing and artificial intelligence. The efficiency of SNNs is often determined by the neural coding schemes. Existing coding schemes either cause huge delays and energy consumption or necessitate intricate neuron models and training techniques. To address these issues, we propose a novel Stepwise Weighted Spike (SWS) coding scheme to enhance the encoding of information in spikes. This approach compresses the spikes by weighting the significance of the spike in each step of neural computation, achieving high performance and low energy consumption. A Ternary Self-Amplifying (TSA) neuron model with a silent period is proposed for supporting SWS-based computing, aimed at minimizing the residual error resulting from stepwise weighting in neural computation. Our experimental results show that the SWS coding scheme outperforms the existing neural coding schemes in very deep SNNs, and significantly reduces operations and latency.
BU-CVKit: Extendable Computer Vision Framework for Species Independent Tracking and Analysis
Jun 07, 2023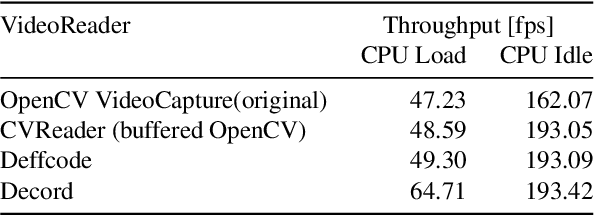
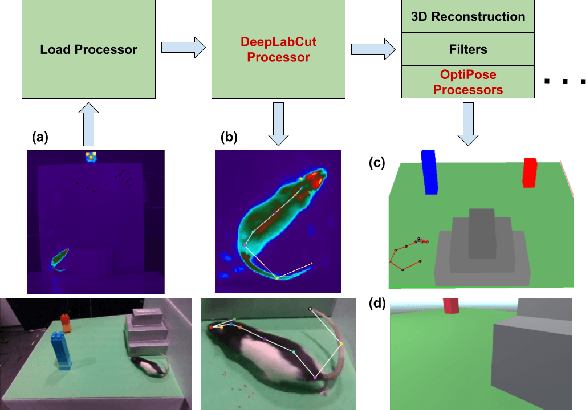
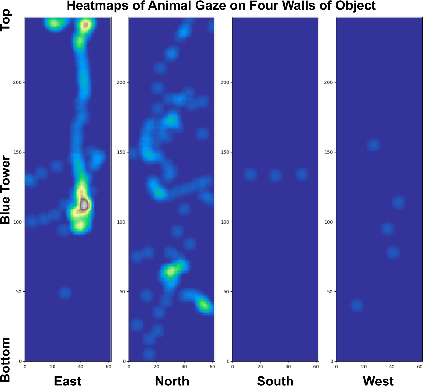
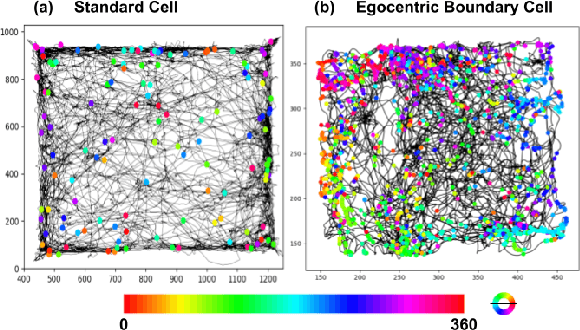
A major bottleneck of interdisciplinary computer vision (CV) research is the lack of a framework that eases the reuse and abstraction of state-of-the-art CV models by CV and non-CV researchers alike. We present here BU-CVKit, a computer vision framework that allows the creation of research pipelines with chainable Processors. The community can create plugins of their work for the framework, hence improving the re-usability, accessibility, and exposure of their work with minimal overhead. Furthermore, we provide MuSeqPose Kit, a user interface for the pose estimation package of BU-CVKit, which automatically scans for installed plugins and programmatically generates an interface for them based on the metadata provided by the user. It also provides software support for standard pose estimation features such as annotations, 3D reconstruction, reprojection, and camera calibration. Finally, we show examples of behavioral neuroscience pipelines created through the sample plugins created for our framework.
Effectively leveraging Multi-modal Features for Movie Genre Classification
Mar 24, 2022



Movie genre classification has been widely studied in recent years due to its various applications in video editing, summarization, and recommendation. Prior work has typically addressed this task by predicting genres based solely on the visual content. As a result, predictions from these methods often perform poorly for genres such as documentary or musical, since non-visual modalities like audio or language play an important role in correctly classifying these genres. In addition, the analysis of long videos at frame level is always associated with high computational cost and makes the prediction less efficient. To address these two issues, we propose a Multi-Modal approach leveraging shot information, MMShot, to classify video genres in an efficient and effective way. We evaluate our method on MovieNet and Condensed Movies for genre classification, achieving 17% ~ 21% improvement on mean Average Precision (mAP) over the state-of-the-art. Extensive experiments are conducted to demonstrate the ability of MMShot for long video analysis and uncover the correlations between genres and multiple movie elements. We also demonstrate our approach's ability to generalize by evaluating the scene boundary detection task, achieving 1.1% improvement on Average Precision (AP) over the state-of-the-art.
Show and Write: Entity-aware News Generation with Image Information
Dec 11, 2021
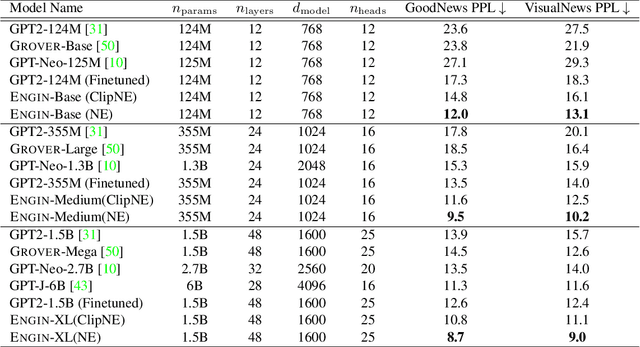
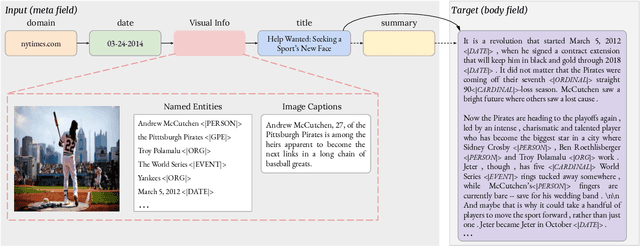

Automatically writing long articles is a complex and challenging language generation task. Prior work has primarily focused on generating these articles using human-written prompt to provide some topical context and some metadata about the article. That said, for many applications, such as generating news stories, these articles are often paired with images and their captions or alt-text, which in turn are based on real-world events and may reference many different named entities that are difficult to be correctly recognized and predicted by language models. To address these two problems, this paper introduces an Entity-aware News Generation method with Image iNformation, Engin, to incorporate news image information into language models. Engin produces news articles conditioned on both metadata and information such as captions and named entities extracted from images. We also propose an Entity-aware mechanism to help our model better recognize and predict the entity names in news. We perform experiments on two public large-scale news datasets, GoodNews and VisualNews. Quantitative results show that our approach improves article perplexity by 4-5 points over the base models. Qualitative results demonstrate the text generated by Engin is more consistent with news images. We also perform article quality annotation experiment on the generated articles to validate that our model produces higher-quality articles. Finally, we investigate the effect Engin has on methods that automatically detect machine-generated articles.