 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalk and Read Less: Improving the Efficiency of Vision-and-Language Navigation via Tuning-Free Multimodal Token Pruning
Sep 18, 2025Large models achieve strong performance on Vision-and-Language Navigation (VLN) tasks, but are costly to run in resource-limited environments. Token pruning offers appealing tradeoffs for efficiency with minimal performance loss by reducing model input size, but prior work overlooks VLN-specific challenges. For example, information loss from pruning can effectively increase computational cost due to longer walks. Thus, the inability to identify uninformative tokens undermines the supposed efficiency gains from pruning. To address this, we propose Navigation-Aware Pruning (NAP), which uses navigation-specific traits to simplify the pruning process by pre-filtering tokens into foreground and background. For example, image views are filtered based on whether the agent can navigate in that direction. We also extract navigation-relevant instructions using a Large Language Model. After filtering, we focus pruning on background tokens, minimizing information loss. To further help avoid increases in navigation length, we discourage backtracking by removing low-importance navigation nodes. Experiments on standard VLN benchmarks show NAP significantly outperforms prior work, preserving higher success rates while saving more than 50% FLOPS.
LoRA-Loop: Closing the Synthetic Replay Cycle for Continual VLM Learning
Jul 17, 2025Continual learning for vision-language models has achieved remarkable performance through synthetic replay, where samples are generated using Stable Diffusion to regularize during finetuning and retain knowledge. However, real-world downstream applications often exhibit domain-specific nuances and fine-grained semantics not captured by generators, causing synthetic-replay methods to produce misaligned samples that misguide finetuning and undermine retention of prior knowledge. In this work, we propose a LoRA-enhanced synthetic-replay framework that injects task-specific low-rank adapters into a frozen Stable Diffusion model, efficiently capturing each new task's unique visual and semantic patterns. Specifically, we introduce a two-stage, confidence-based sample selection: we first rank real task data by post-finetuning VLM confidence to focus LoRA finetuning on the most representative examples, then generate synthetic samples and again select them by confidence for distillation. Our approach integrates seamlessly with existing replay pipelines-simply swap in the adapted generator to boost replay fidelity. Extensive experiments on the Multi-domain Task Incremental Learning (MTIL) benchmark show that our method outperforms previous synthetic-replay techniques, achieving an optimal balance among plasticity, stability, and zero-shot capability. These results demonstrate the effectiveness of generator adaptation via LoRA for robust continual learning in VLMs.
GenEAva: Generating Cartoon Avatars with Fine-Grained Facial Expressions from Realistic Diffusion-based Faces
Apr 10, 2025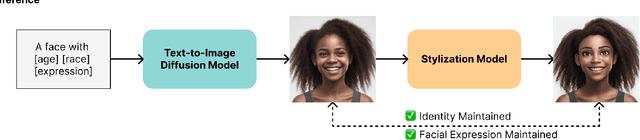


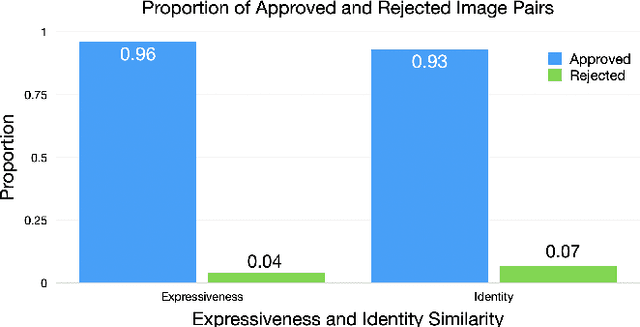
Cartoon avatars have been widely used in various applications, including social media, online tutoring, and gaming. However, existing cartoon avatar datasets and generation methods struggle to present highly expressive avatars with fine-grained facial expressions and are often inspired from real-world identities, raising privacy concerns. To address these challenges, we propose a novel framework, GenEAva, for generating high-quality cartoon avatars with fine-grained facial expressions. Our approach fine-tunes a state-of-the-art text-to-image diffusion model to synthesize highly detailed and expressive facial expressions. We then incorporate a stylization model that transforms these realistic faces into cartoon avatars while preserving both identity and expression. Leveraging this framework, we introduce the first expressive cartoon avatar dataset, GenEAva 1.0, specifically designed to capture 135 fine-grained facial expressions, featuring 13,230 expressive cartoon avatars with a balanced distribution across genders, racial groups, and age ranges. We demonstrate that our fine-tuned model generates more expressive faces than the state-of-the-art text-to-image diffusion model SDXL. We also verify that the cartoon avatars generated by our framework do not include memorized identities from fine-tuning data. The proposed framework and dataset provide a diverse and expressive benchmark for future research in cartoon avatar generation.
DebiasPI: Inference-time Debiasing by Prompt Iteration of a Text-to-Image Generative Model
Jan 28, 2025



Ethical intervention prompting has emerged as a tool to counter demographic biases of text-to-image generative AI models. Existing solutions either require to retrain the model or struggle to generate images that reflect desired distributions on gender and race. We propose an inference-time process called DebiasPI for Debiasing-by-Prompt-Iteration that provides prompt intervention by enabling the user to control the distributions of individuals' demographic attributes in image generation. DebiasPI keeps track of which attributes have been generated either by probing the internal state of the model or by using external attribute classifiers. Its control loop guides the text-to-image model to select not yet sufficiently represented attributes, With DebiasPI, we were able to create images with equal representations of race and gender that visualize challenging concepts of news headlines. We also experimented with the attributes age, body type, profession, and skin tone, and measured how attributes change when our intervention prompt targets the distribution of an unrelated attribute type. We found, for example, if the text-to-image model is asked to balance racial representation, gender representation improves but the skin tone becomes less diverse. Attempts to cover a wide range of skin colors with various intervention prompts showed that the model struggles to generate the palest skin tones. We conducted various ablation studies, in which we removed DebiasPI's attribute control, that reveal the model's propensity to generate young, male characters. It sometimes visualized career success by generating two-panel images with a pre-success dark-skinned person becoming light-skinned with success, or switching gender from pre-success female to post-success male, thus further motivating ethical intervention prompting with DebiasPI.
ExeChecker: Where Did I Go Wrong?
Dec 13, 2024In this paper, we present a contrastive learning based framework, ExeChecker, for the interpretation of rehabilitation exercises. Our work builds upon state-of-the-art advances in the area of human pose estimation, graph-attention neural networks, and transformer interpretablity. The downstream task is to assist rehabilitation by providing informative feedback to users while they are performing prescribed exercises. We utilize a contrastive learning strategy during training. Given a tuple of correctly and incorrectly executed exercises, our model is able to identify and highlight those joints that are involved in an incorrect movement and thus require the user's attention. We collected an in-house dataset, ExeCheck, with paired recordings of both correct and incorrect execution of exercises. In our experiments, we tested our method on this dataset as well as the UI-PRMD dataset and found ExeCheck outperformed the baseline method using pairwise sequence alignment in identifying joints of physical relevance in rehabilitation exercises.
A Lesion-aware Edge-based Graph Neural Network for Predicting Language Ability in Patients with Post-stroke Aphasia
Sep 03, 2024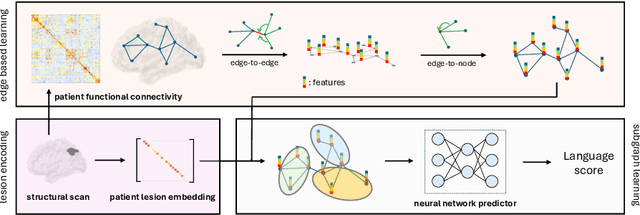



We propose a lesion-aware graph neural network (LEGNet) to predict language ability from resting-state fMRI (rs-fMRI) connectivity in patients with post-stroke aphasia. Our model integrates three components: an edge-based learning module that encodes functional connectivity between brain regions, a lesion encoding module, and a subgraph learning module that leverages functional similarities for prediction. We use synthetic data derived from the Human Connectome Project (HCP) for hyperparameter tuning and model pretraining. We then evaluate the performance using repeated 10-fold cross-validation on an in-house neuroimaging dataset of post-stroke aphasia. Our results demonstrate that LEGNet outperforms baseline deep learning methods in predicting language ability. LEGNet also exhibits superior generalization ability when tested on a second in-house dataset that was acquired under a slightly different neuroimaging protocol. Taken together, the results of this study highlight the potential of LEGNet in effectively learning the relationships between rs-fMRI connectivity and language ability in a patient cohort with brain lesions for improved post-stroke aphasia evaluation.
Enhancing Emotion Prediction in News Headlines: Insights from ChatGPT and Seq2Seq Models for Free-Text Generation
Jul 14, 2024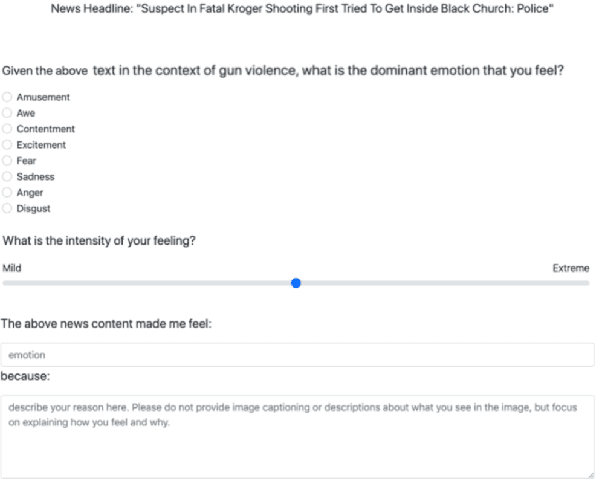
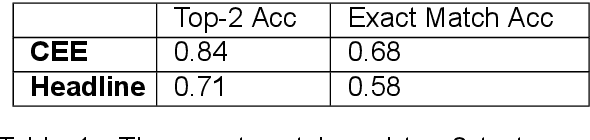
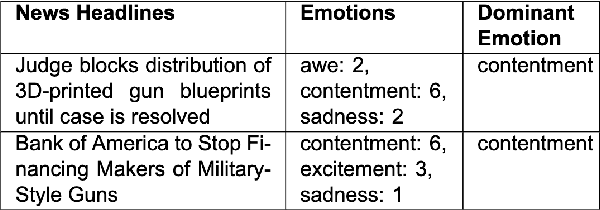

Predicting emotions elicited by news headlines can be challenging as the task is largely influenced by the varying nature of people's interpretations and backgrounds. Previous works have explored classifying discrete emotions directly from news headlines. We provide a different approach to tackling this problem by utilizing people's explanations of their emotion, written in free-text, on how they feel after reading a news headline. Using the dataset BU-NEmo+ (Gao et al., 2022), we found that for emotion classification, the free-text explanations have a strong correlation with the dominant emotion elicited by the headlines. The free-text explanations also contain more sentimental context than the news headlines alone and can serve as a better input to emotion classification models. Therefore, in this work we explored generating emotion explanations from headlines by training a sequence-to-sequence transformer model and by using pretrained large language model, ChatGPT (GPT-4). We then used the generated emotion explanations for emotion classification. In addition, we also experimented with training the pretrained T5 model for the intermediate task of explanation generation before fine-tuning it for emotion classification. Using McNemar's significance test, methods that incorporate GPT-generated free-text emotion explanations demonstrated significant improvement (P-value < 0.05) in emotion classification from headlines, compared to methods that only use headlines. This underscores the value of using intermediate free-text explanations for emotion prediction tasks with headlines.
* published at LREC-COLING 2024
Detecting Frames in News Headlines and Lead Images in U.S. Gun Violence Coverage
Jun 25, 2024
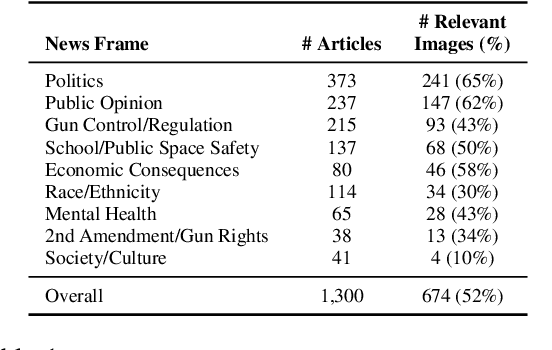

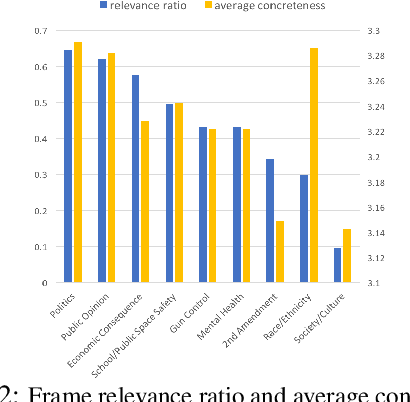
News media structure their reporting of events or issues using certain perspectives. When describing an incident involving gun violence, for example, some journalists may focus on mental health or gun regulation, while others may emphasize the discussion of gun rights. Such perspectives are called \say{frames} in communication research. We study, for the first time, the value of combining lead images and their contextual information with text to identify the frame of a given news article. We observe that using multiple modes of information(article- and image-derived features) improves prediction of news frames over any single mode of information when the images are relevant to the frames of the headlines. We also observe that frame image relevance is related to the ease of conveying frames via images, which we call frame concreteness. Additionally, we release the first multimodal news framing dataset related to gun violence in the U.S., curated and annotated by communication researchers. The dataset will allow researchers to further examine the use of multiple information modalities for studying media framing.
BU-CVKit: Extendable Computer Vision Framework for Species Independent Tracking and Analysis
Jun 07, 2023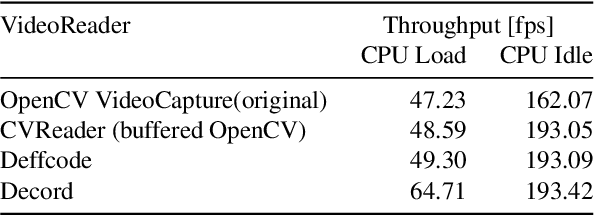
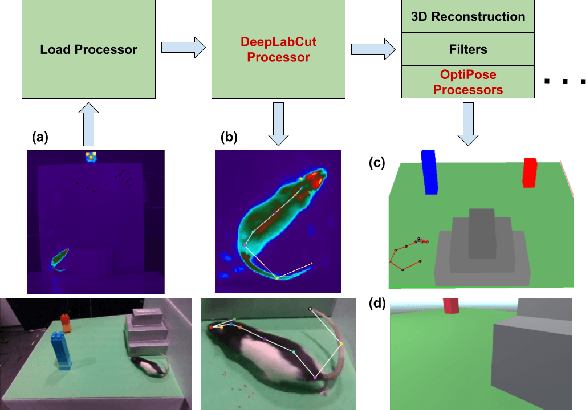
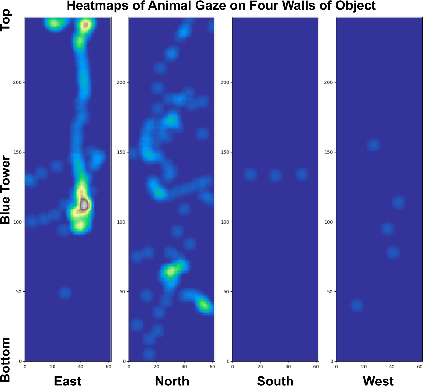
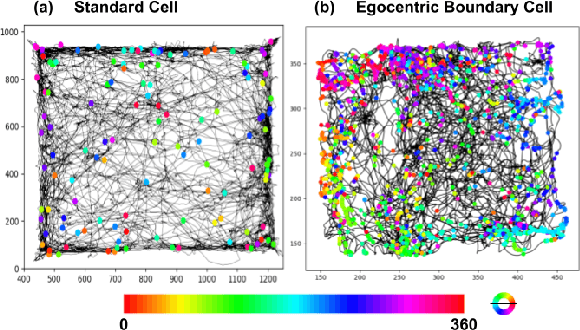
A major bottleneck of interdisciplinary computer vision (CV) research is the lack of a framework that eases the reuse and abstraction of state-of-the-art CV models by CV and non-CV researchers alike. We present here BU-CVKit, a computer vision framework that allows the creation of research pipelines with chainable Processors. The community can create plugins of their work for the framework, hence improving the re-usability, accessibility, and exposure of their work with minimal overhead. Furthermore, we provide MuSeqPose Kit, a user interface for the pose estimation package of BU-CVKit, which automatically scans for installed plugins and programmatically generates an interface for them based on the metadata provided by the user. It also provides software support for standard pose estimation features such as annotations, 3D reconstruction, reprojection, and camera calibration. Finally, we show examples of behavioral neuroscience pipelines created through the sample plugins created for our framework.
Exploring Consistency in Cross-Domain Transformer for Domain Adaptive Semantic Segmentation
Dec 21, 2022While transformers have greatly boosted performance in semantic segmentation, domain adaptive transformers are not yet well explored. We identify that the domain gap can cause discrepancies in self-attention. Due to this gap, the transformer attends to spurious regions or pixels, which deteriorates accuracy on the target domain. We propose to perform adaptation on attention maps with cross-domain attention layers that share features between the source and the target domains. Specifically, we impose consistency between predictions from cross-domain attention and self-attention modules to encourage similar distribution in the attention and output of the model across domains, i.e., attention-level and output-level alignment. We also enforce consistency in attention maps between different augmented views to further strengthen the attention-based alignment. Combining these two components, our method mitigates the discrepancy in attention maps across domains and further boosts the performance of the transformer under unsupervised domain adaptation settings. Our model outperforms the existing state-of-the-art baseline model on three widely used benchmarks, including GTAV-to-Cityscapes by 1.3 percent point (pp), Synthia-to-Cityscapes by 0.6 pp, and Cityscapes-to-ACDC by 1.1 pp, on average. Additionally, we verify the effectiveness and generalizability of our method through extensive experiments. Our code will be publicly available.