 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Human-AI Triadic Programming: Uncovering the Role of AI Agent and the Value of Human Partner in Collaborative Learning
Jan 17, 2026As AI assistance becomes embedded in programming practice, researchers have increasingly examined how these systems help learners generate code and work more efficiently. However, these studies often position AI as a replacement for human collaboration and overlook the social and learning-oriented aspects that emerge in collaborative programming. Our work introduces human-human-AI (HHAI) triadic programming, where an AI agent serves as an additional collaborator rather than a substitute for a human partner. Through a within-subjects study with 20 participants, we show that triadic collaboration enhances collaborative learning and social presence compared to the dyadic human-AI (HAI) baseline. In the triadic HHAI conditions, participants relied significantly less on AI-generated code in their work. This effect was strongest in the HHAI-shared condition, where participants had an increased sense of responsibility to understand AI suggestions before applying them. These findings demonstrate how triadic settings activate socially shared regulation of learning by making AI use visible and accountable to a human peer, suggesting that AI systems that augment rather than automate peer collaboration can better preserve the learning processes that collaborative programming relies on.
CounterQuill: Investigating the Potential of Human-AI Collaboration in Online Counterspeech Writing
Oct 03, 2024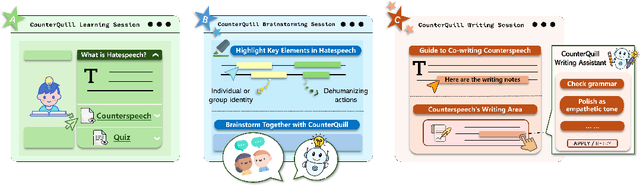



Online hate speech has become increasingly prevalent on social media platforms, causing harm to individuals and society. While efforts have been made to combat this issue through content moderation, the potential of user-driven counterspeech as an alternative solution remains underexplored. Existing counterspeech methods often face challenges such as fear of retaliation and skill-related barriers. To address these challenges, we introduce CounterQuill, an AI-mediated system that assists users in composing effective and empathetic counterspeech. CounterQuill provides a three-step process: (1) a learning session to help users understand hate speech and counterspeech; (2) a brainstorming session that guides users in identifying key elements of hate speech and exploring counterspeech strategies; and (3) a co-writing session that enables users to draft and refine their counterspeech with CounterQuill. We conducted a within-subjects user study with 20 participants to evaluate CounterQuill in comparison to ChatGPT. Results show that CounterQuill's guidance and collaborative writing process provided users a stronger sense of ownership over their co-authored counterspeech. Users perceived CounterQuill as a writing partner and thus were more willing to post the co-written counterspeech online compared to the one written with ChatGPT.
Detecting Frames in News Headlines and Lead Images in U.S. Gun Violence Coverage
Jun 25, 2024
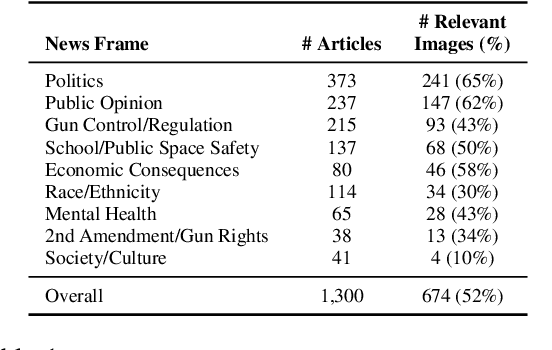

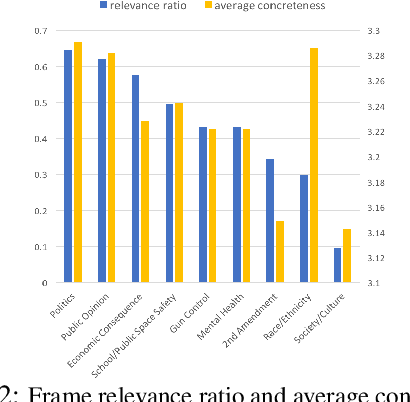
News media structure their reporting of events or issues using certain perspectives. When describing an incident involving gun violence, for example, some journalists may focus on mental health or gun regulation, while others may emphasize the discussion of gun rights. Such perspectives are called \say{frames} in communication research. We study, for the first time, the value of combining lead images and their contextual information with text to identify the frame of a given news article. We observe that using multiple modes of information(article- and image-derived features) improves prediction of news frames over any single mode of information when the images are relevant to the frames of the headlines. We also observe that frame image relevance is related to the ease of conveying frames via images, which we call frame concreteness. Additionally, we release the first multimodal news framing dataset related to gun violence in the U.S., curated and annotated by communication researchers. The dataset will allow researchers to further examine the use of multiple information modalities for studying media framing.
Referring Expressions with Rational Speech Act Framework: A Probabilistic Approach
May 16, 2022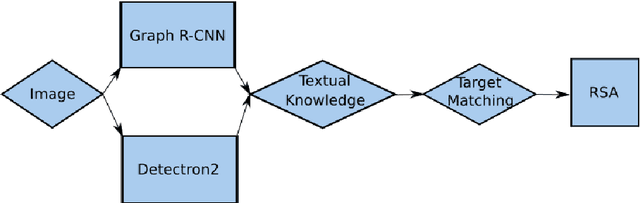

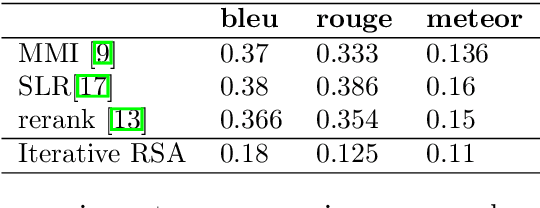
This paper focuses on a referring expression generation (REG) task in which the aim is to pick out an object in a complex visual scene. One common theoretical approach to this problem is to model the task as a two-agent cooperative scheme in which a `speaker' agent would generate the expression that best describes a targeted area and a `listener' agent would identify the target. Several recent REG systems have used deep learning approaches to represent the speaker/listener agents. The Rational Speech Act framework (RSA), a Bayesian approach to pragmatics that can predict human linguistic behavior quite accurately, has been shown to generate high quality and explainable expressions on toy datasets involving simple visual scenes. Its application to large scale problems, however, remains largely unexplored. This paper applies a combination of the probabilistic RSA framework and deep learning approaches to larger datasets involving complex visual scenes in a multi-step process with the aim of generating better-explained expressions. We carry out experiments on the RefCOCO and RefCOCO+ datasets and compare our approach with other end-to-end deep learning approaches as well as a variation of RSA to highlight our key contribution. Experimental results show that while achieving lower accuracy than SOTA deep learning methods, our approach outperforms similar RSA approach in human comprehension and has an advantage over end-to-end deep learning under limited data scenario. Lastly, we provide a detailed analysis on the expression generation process with concrete examples, thus providing a systematic view on error types and deficiencies in the generation process and identifying possible areas for future improvements.