 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Distance Sensitivity Oracles
Nov 02, 2022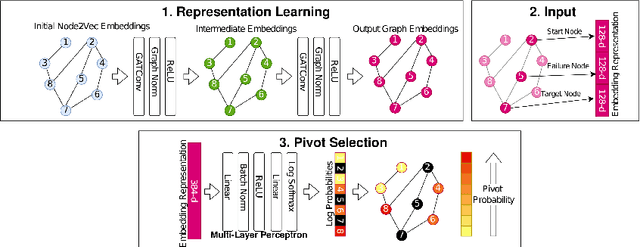
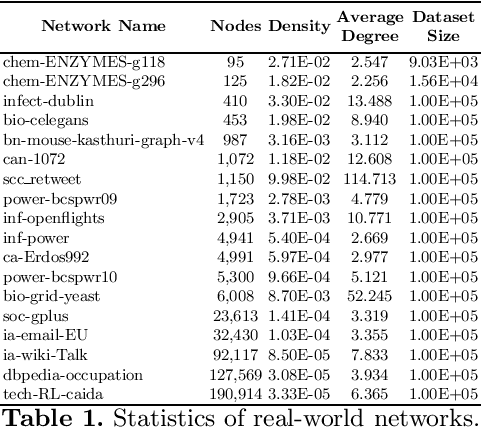
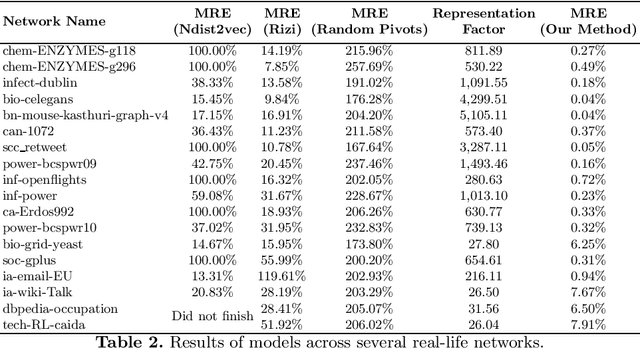
One of the most fundamental graph problems is finding a shortest path from a source to a target node. While in its basic forms the problem has been studied extensively and efficient algorithms are known, it becomes significantly harder as soon as parts of the graph are susceptible to failure. Although one can recompute a shortest replacement path after every outage, this is rather inefficient both in time and/or storage. One way to overcome this problem is to shift computational burden from the queries into a pre-processing step, where a data structure is computed that allows for fast querying of replacement paths, typically referred to as a Distance Sensitivity Oracle (DSO). While DSOs have been extensively studied in the theoretical computer science community, to the best of our knowledge this is the first work to construct DSOs using deep learning techniques. We show how to use deep learning to utilize a combinatorial structure of replacement paths. More specifically, we utilize the combinatorial structure of replacement paths as a concatenation of shortest paths and use deep learning to find the pivot nodes for stitching shortest paths into replacement paths.
Referring Expressions with Rational Speech Act Framework: A Probabilistic Approach
May 16, 2022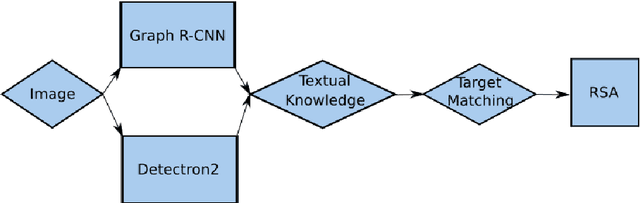

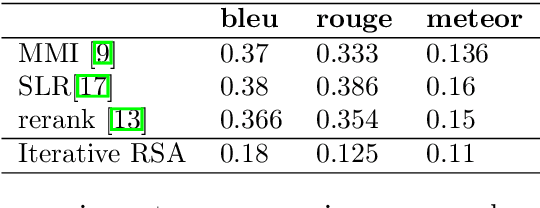
This paper focuses on a referring expression generation (REG) task in which the aim is to pick out an object in a complex visual scene. One common theoretical approach to this problem is to model the task as a two-agent cooperative scheme in which a `speaker' agent would generate the expression that best describes a targeted area and a `listener' agent would identify the target. Several recent REG systems have used deep learning approaches to represent the speaker/listener agents. The Rational Speech Act framework (RSA), a Bayesian approach to pragmatics that can predict human linguistic behavior quite accurately, has been shown to generate high quality and explainable expressions on toy datasets involving simple visual scenes. Its application to large scale problems, however, remains largely unexplored. This paper applies a combination of the probabilistic RSA framework and deep learning approaches to larger datasets involving complex visual scenes in a multi-step process with the aim of generating better-explained expressions. We carry out experiments on the RefCOCO and RefCOCO+ datasets and compare our approach with other end-to-end deep learning approaches as well as a variation of RSA to highlight our key contribution. Experimental results show that while achieving lower accuracy than SOTA deep learning methods, our approach outperforms similar RSA approach in human comprehension and has an advantage over end-to-end deep learning under limited data scenario. Lastly, we provide a detailed analysis on the expression generation process with concrete examples, thus providing a systematic view on error types and deficiencies in the generation process and identifying possible areas for future improvements.
NodeDrop: A Condition for Reducing Network Size without Effect on Output
Jun 12, 2019
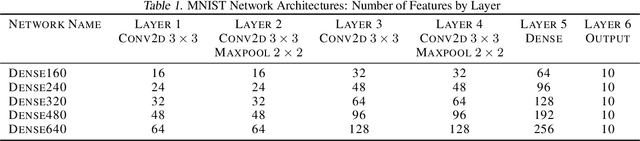
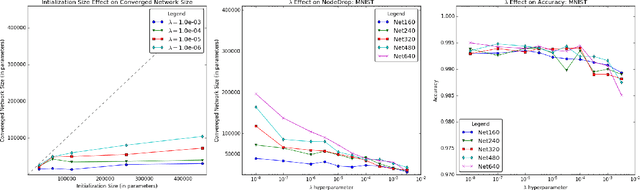
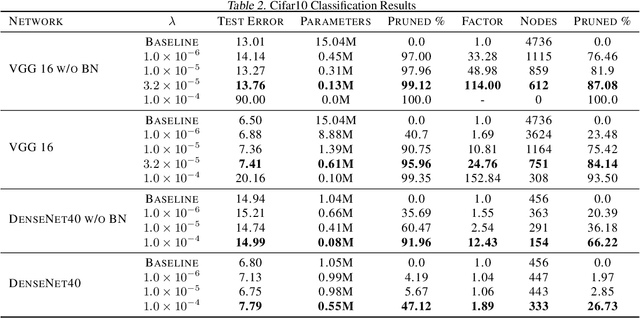
Determining an appropriate number of features for each layer in a neural network is an important and difficult task. This task is especially important in applications on systems with limited memory or processing power. Many current approaches to reduce network size either utilize iterative procedures, which can extend training time significantly, or require very careful tuning of algorithm parameters to achieve reasonable results. In this paper we propose NodeDrop, a new method for eliminating features in a network. With NodeDrop, we define a condition to identify and guarantee which nodes carry no information, and then use regularization to encourage nodes to meet this condition. We find that NodeDrop drastically reduces the number of features in a network while maintaining high performance, reducing the number of parameters by a factor of 114x for a VGG like network on CIFAR10 without a drop in accuracy.
Sparse Coding and Autoencoders
Oct 20, 2017
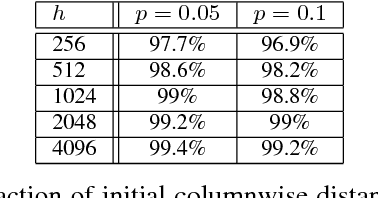
In "Dictionary Learning" one tries to recover incoherent matrices $A^* \in \mathbb{R}^{n \times h}$ (typically overcomplete and whose columns are assumed to be normalized) and sparse vectors $x^* \in \mathbb{R}^h$ with a small support of size $h^p$ for some $0 <p < 1$ while having access to observations $y \in \mathbb{R}^n$ where $y = A^*x^*$. In this work we undertake a rigorous analysis of whether gradient descent on the squared loss of an autoencoder can solve the dictionary learning problem. The "Autoencoder" architecture we consider is a $\mathbb{R}^n \rightarrow \mathbb{R}^n$ mapping with a single ReLU activation layer of size $h$. Under very mild distributional assumptions on $x^*$, we prove that the norm of the expected gradient of the standard squared loss function is asymptotically (in sparse code dimension) negligible for all points in a small neighborhood of $A^*$. This is supported with experimental evidence using synthetic data. We also conduct experiments to suggest that $A^*$ is a local minimum. Along the way we prove that a layer of ReLU gates can be set up to automatically recover the support of the sparse codes. This property holds independent of the loss function. We believe that it could be of independent interest.
Topological and Statistical Behavior Classifiers for Tracking Applications
Jun 01, 2014
We introduce the first unified theory for target tracking using Multiple Hypothesis Tracking, Topological Data Analysis, and machine learning. Our string of innovations are 1) robust topological features are used to encode behavioral information, 2) statistical models are fitted to distributions over these topological features, and 3) the target type classification methods of Wigren and Bar Shalom et al. are employed to exploit the resulting likelihoods for topological features inside of the tracking procedure. To demonstrate the efficacy of our approach, we test our procedure on synthetic vehicular data generated by the Simulation of Urban Mobility package.