 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree-Transformer: A Transformer-Based Method for Correction of Tree-Structured Data
Aug 01, 2019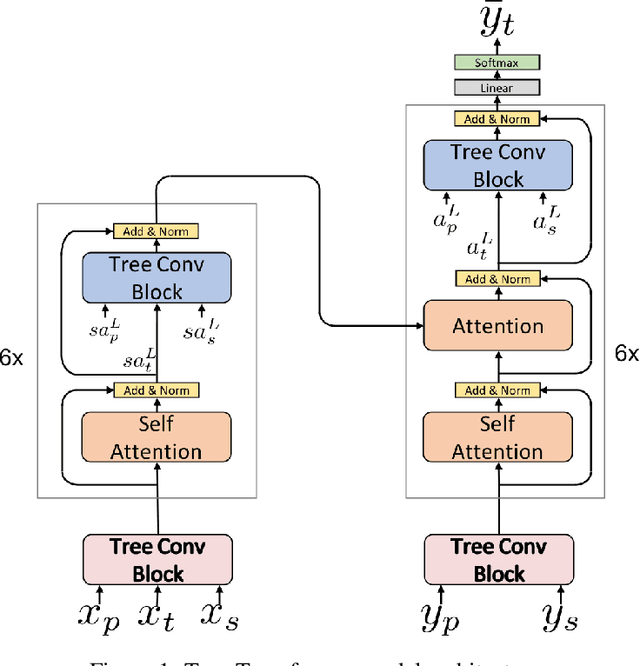
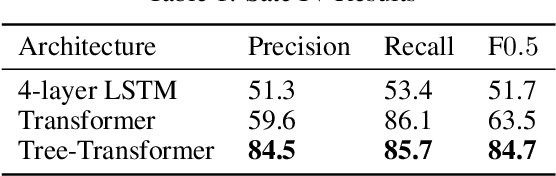
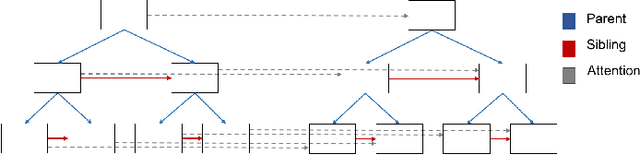
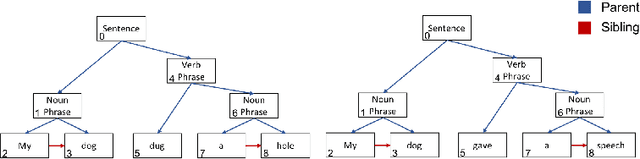
Many common sequential data sources, such as source code and natural language, have a natural tree-structured representation. These trees can be generated by fitting a sequence to a grammar, yielding a hierarchical ordering of the tokens in the sequence. This structure encodes a high degree of syntactic information, making it ideal for problems such as grammar correction. However, little work has been done to develop neural networks that can operate on and exploit tree-structured data. In this paper we present the Tree-Transformer \textemdash{} a novel neural network architecture designed to translate between arbitrary input and output trees. We applied this architecture to correction tasks in both the source code and natural language domains. On source code, our model achieved an improvement of $25\%$ $\text{F}0.5$ over the best sequential method. On natural language, we achieved comparable results to the most complex state of the art systems, obtaining a $10\%$ improvement in recall on the CoNLL 2014 benchmark and the highest to date $\text{F}0.5$ score on the AESW benchmark of $50.43$.
NodeDrop: A Condition for Reducing Network Size without Effect on Output
Jun 12, 2019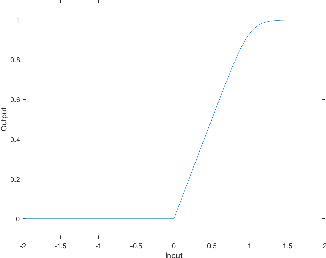
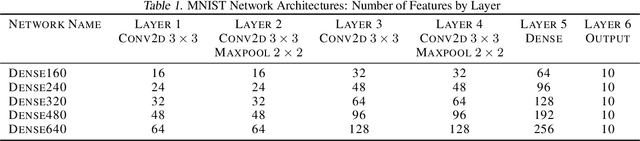
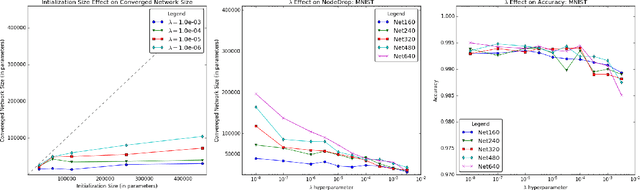
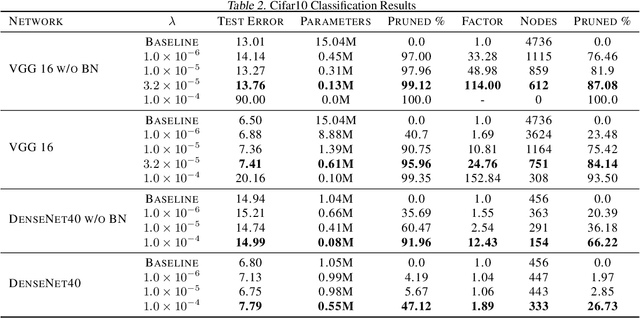
Determining an appropriate number of features for each layer in a neural network is an important and difficult task. This task is especially important in applications on systems with limited memory or processing power. Many current approaches to reduce network size either utilize iterative procedures, which can extend training time significantly, or require very careful tuning of algorithm parameters to achieve reasonable results. In this paper we propose NodeDrop, a new method for eliminating features in a network. With NodeDrop, we define a condition to identify and guarantee which nodes carry no information, and then use regularization to encourage nodes to meet this condition. We find that NodeDrop drastically reduces the number of features in a network while maintaining high performance, reducing the number of parameters by a factor of 114x for a VGG like network on CIFAR10 without a drop in accuracy.
Learning to Repair Software Vulnerabilities with Generative Adversarial Networks
Oct 28, 2018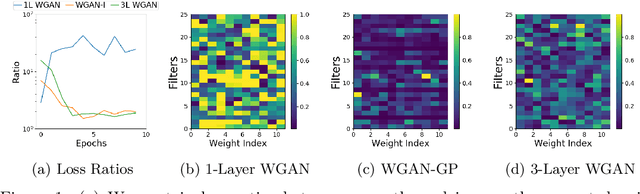
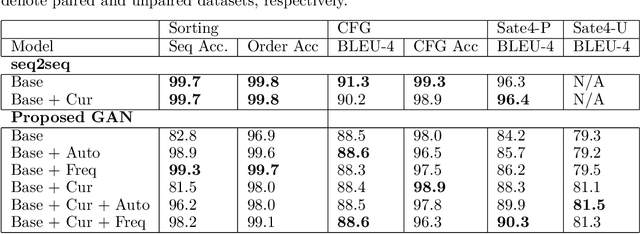

Motivated by the problem of automated repair of software vulnerabilities, we propose an adversarial learning approach that maps from one discrete source domain to another target domain without requiring paired labeled examples or source and target domains to be bijections. We demonstrate that the proposed adversarial learning approach is an effective technique for repairing software vulnerabilities, performing close to seq2seq approaches that require labeled pairs. The proposed Generative Adversarial Network approach is application-agnostic in that it can be applied to other problems similar to code repair, such as grammar correction or sentiment translation.