 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree-Transformer: A Transformer-Based Method for Correction of Tree-Structured Data
Paper and Code
Aug 01, 2019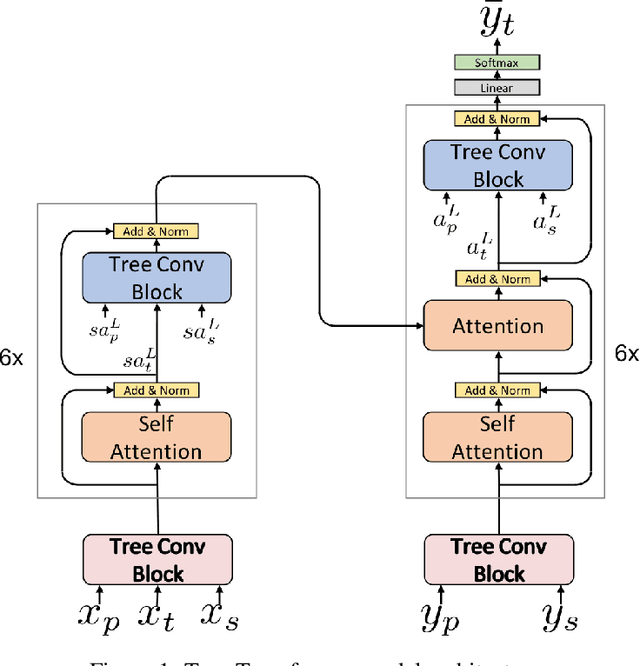
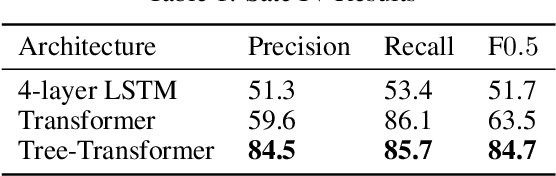
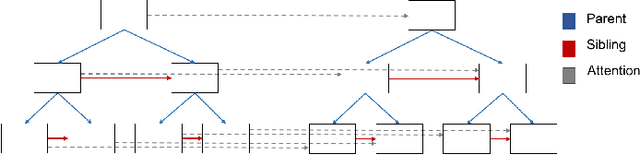
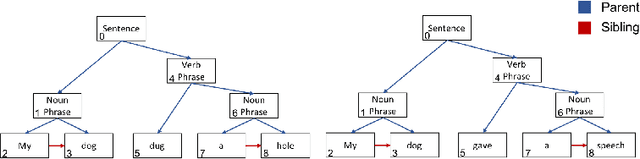
Many common sequential data sources, such as source code and natural language, have a natural tree-structured representation. These trees can be generated by fitting a sequence to a grammar, yielding a hierarchical ordering of the tokens in the sequence. This structure encodes a high degree of syntactic information, making it ideal for problems such as grammar correction. However, little work has been done to develop neural networks that can operate on and exploit tree-structured data. In this paper we present the Tree-Transformer \textemdash{} a novel neural network architecture designed to translate between arbitrary input and output trees. We applied this architecture to correction tasks in both the source code and natural language domains. On source code, our model achieved an improvement of $25\%$ $\text{F}0.5$ over the best sequential method. On natural language, we achieved comparable results to the most complex state of the art systems, obtaining a $10\%$ improvement in recall on the CoNLL 2014 benchmark and the highest to date $\text{F}0.5$ score on the AESW benchmark of $50.43$.