 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Coding and Autoencoders
Paper and Code
Oct 20, 2017
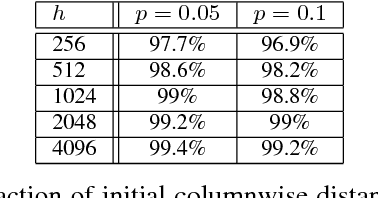
In "Dictionary Learning" one tries to recover incoherent matrices $A^* \in \mathbb{R}^{n \times h}$ (typically overcomplete and whose columns are assumed to be normalized) and sparse vectors $x^* \in \mathbb{R}^h$ with a small support of size $h^p$ for some $0 <p < 1$ while having access to observations $y \in \mathbb{R}^n$ where $y = A^*x^*$. In this work we undertake a rigorous analysis of whether gradient descent on the squared loss of an autoencoder can solve the dictionary learning problem. The "Autoencoder" architecture we consider is a $\mathbb{R}^n \rightarrow \mathbb{R}^n$ mapping with a single ReLU activation layer of size $h$. Under very mild distributional assumptions on $x^*$, we prove that the norm of the expected gradient of the standard squared loss function is asymptotically (in sparse code dimension) negligible for all points in a small neighborhood of $A^*$. This is supported with experimental evidence using synthetic data. We also conduct experiments to suggest that $A^*$ is a local minimum. Along the way we prove that a layer of ReLU gates can be set up to automatically recover the support of the sparse codes. This property holds independent of the loss function. We believe that it could be of independent interest.