 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient MDI Adaptation for n-gram Language Models
Aug 05, 2020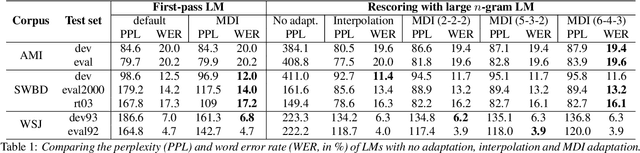
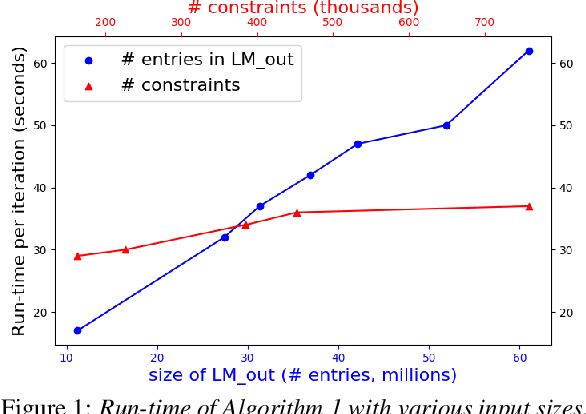
This paper presents an efficient algorithm for n-gram language model adaptation under the minimum discrimination information (MDI) principle, where an out-of-domain language model is adapted to satisfy the constraints of marginal probabilities of the in-domain data. The challenge for MDI language model adaptation is its computational complexity. By taking advantage of the backoff structure of n-gram model and the idea of hierarchical training method, originally proposed for maximum entropy (ME) language models, we show that MDI adaptation can be computed in linear-time complexity to the inputs in each iteration. The complexity remains the same as ME models, although MDI is more general than ME. This makes MDI adaptation practical for large corpus and vocabulary. Experimental results confirm the scalability of our algorithm on very large datasets, while MDI adaptation gets slightly worse perplexity but better word error rate results compared to simple linear interpolation.
CHiME-6 Challenge:Tackling Multispeaker Speech Recognition for Unsegmented Recordings
May 02, 2020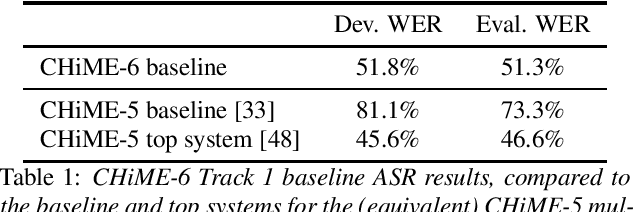

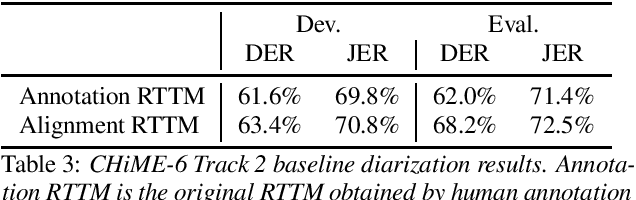

Following the success of the 1st, 2nd, 3rd, 4th and 5th CHiME challenges we organize the 6th CHiME Speech Separation and Recognition Challenge (CHiME-6). The new challenge revisits the previous CHiME-5 challenge and further considers the problem of distant multi-microphone conversational speech diarization and recognition in everyday home environments. Speech material is the same as the previous CHiME-5 recordings except for accurate array synchronization. The material was elicited using a dinner party scenario with efforts taken to capture data that is representative of natural conversational speech. This paper provides a baseline description of the CHiME-6 challenge for both segmented multispeaker speech recognition (Track 1) and unsegmented multispeaker speech recognition (Track 2). Of note, Track 2 is the first challenge activity in the community to tackle an unsegmented multispeaker speech recognition scenario with a complete set of reproducible open source baselines providing speech enhancement, speaker diarization, and speech recognition modules.
FDFNet : A Secure Cancelable Deep Finger Dorsal Template Generation Network Secured via. Bio-Hashing
Dec 13, 2018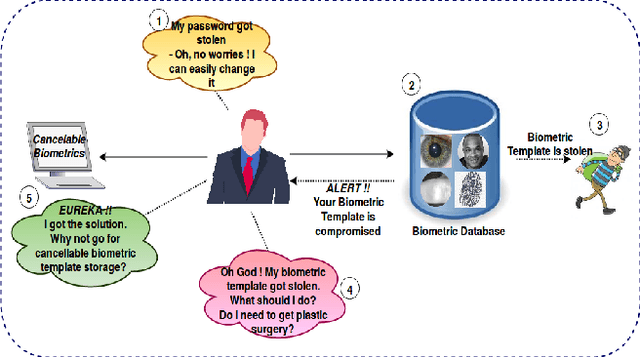
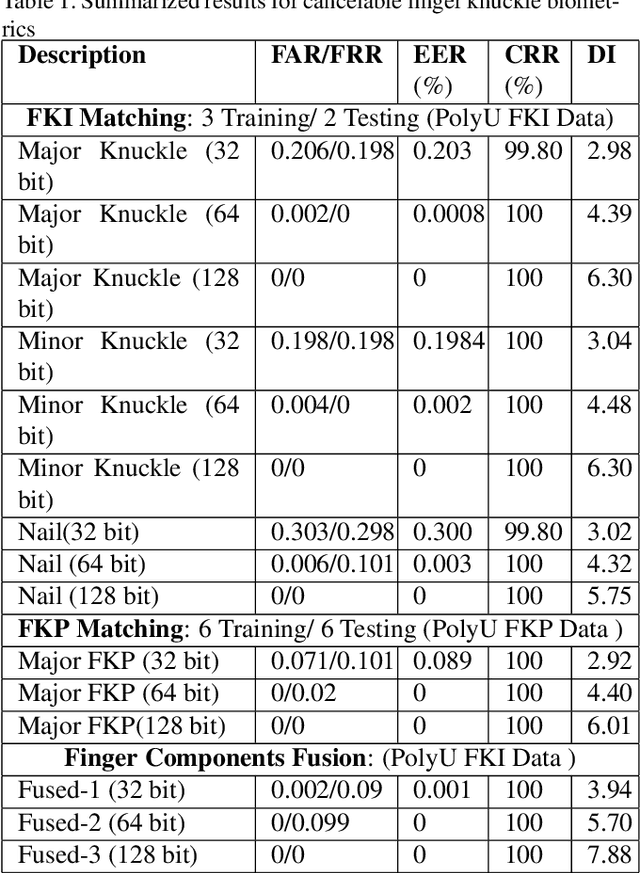
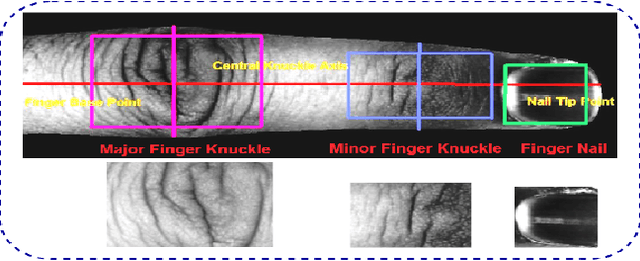
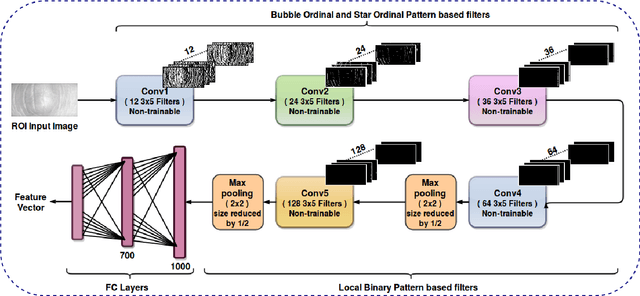
Present world has already been consistently exploring the fine edges of online and digital world by imposing multiple challenging problems/scenarios. Similar to physical world, personal identity management is very crucial in-order to provide any secure online system. Last decade has seen a lot of work in this area using biometrics such as face, fingerprint, iris etc. Still there exist several vulnerabilities and one should have to address the problem of compromised biometrics much more seriously, since they cannot be modified easily once compromised. In this work, we have proposed a secure cancelable finger dorsal template generation network (learning domain specific features) secured via. Bio-Hashing. Proposed system effectively protects the original finger dorsal images by withdrawing compromised template and reassigning the new one. A novel Finger-Dorsal Feature Extraction Net (FDFNet) has been proposed for extracting the discriminative features. This network is exclusively trained on trait specific features without using any kind of pre-trained architecture. Later Bio-Hashing, a technique based on assigning a tokenized random number to each user, has been used to hash the features extracted from FDFNet. To test the performance of the proposed architecture, we have tested it over two benchmark public finger knuckle datasets: PolyU FKP and PolyU Contactless FKI. The experimental results shows the effectiveness of the proposed system in terms of security and accuracy.
Sparse Coding and Autoencoders
Oct 20, 2017
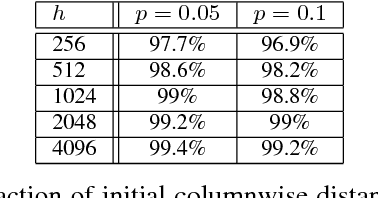
In "Dictionary Learning" one tries to recover incoherent matrices $A^* \in \mathbb{R}^{n \times h}$ (typically overcomplete and whose columns are assumed to be normalized) and sparse vectors $x^* \in \mathbb{R}^h$ with a small support of size $h^p$ for some $0 <p < 1$ while having access to observations $y \in \mathbb{R}^n$ where $y = A^*x^*$. In this work we undertake a rigorous analysis of whether gradient descent on the squared loss of an autoencoder can solve the dictionary learning problem. The "Autoencoder" architecture we consider is a $\mathbb{R}^n \rightarrow \mathbb{R}^n$ mapping with a single ReLU activation layer of size $h$. Under very mild distributional assumptions on $x^*$, we prove that the norm of the expected gradient of the standard squared loss function is asymptotically (in sparse code dimension) negligible for all points in a small neighborhood of $A^*$. This is supported with experimental evidence using synthetic data. We also conduct experiments to suggest that $A^*$ is a local minimum. Along the way we prove that a layer of ReLU gates can be set up to automatically recover the support of the sparse codes. This property holds independent of the loss function. We believe that it could be of independent interest.