 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Spatial Clustering with LSTM Speech Models for Multichannel Speech Enhancement
Dec 02, 2020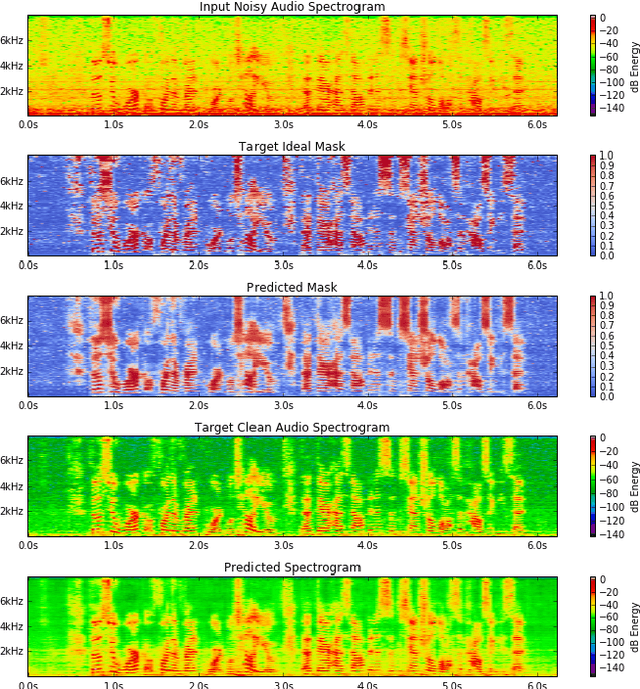
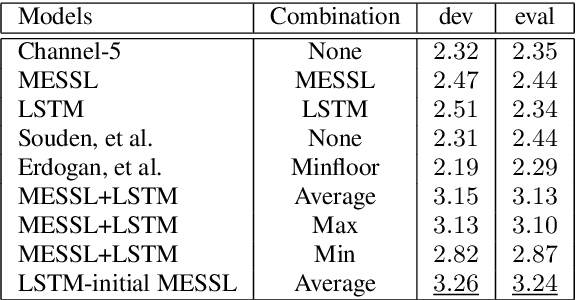
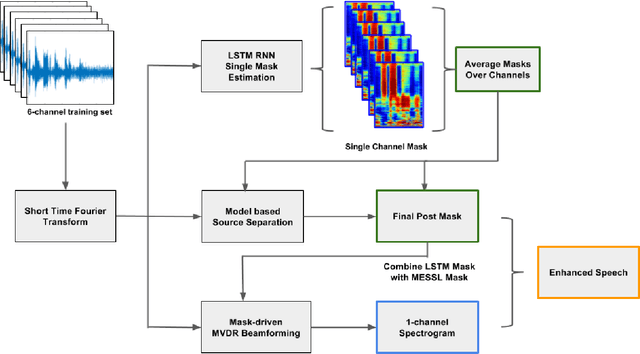
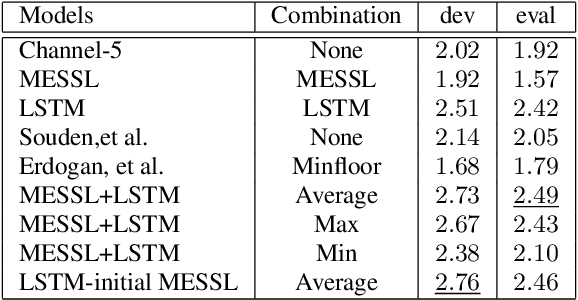
Recurrent neural networks using the LSTM architecture can achieve significant single-channel noise reduction. It is not obvious, however, how to apply them to multi-channel inputs in a way that can generalize to new microphone configurations. In contrast, spatial clustering techniques can achieve such generalization, but lack a strong signal model. This paper combines the two approaches to attain both the spatial separation performance and generality of multichannel spatial clustering and the signal modeling performance of multiple parallel single-channel LSTM speech enhancers. The system is compared to several baselines on the CHiME3 dataset in terms of speech quality predicted by the PESQ algorithm and word error rate of a recognizer trained on mis-matched conditions, in order to focus on generalization. Our experiments show that by combining the LSTM models with the spatial clustering, we reduce word error rate by 4.6\% absolute (17.2\% relative) on the development set and 11.2\% absolute (25.5\% relative) on test set compared with spatial clustering system, and reduce by 10.75\% (32.72\% relative) on development set and 6.12\% absolute (15.76\% relative) on test data compared with LSTM model.
Enhancement of Spatial Clustering-Based Time-Frequency Masks using LSTM Neural Networks
Dec 02, 2020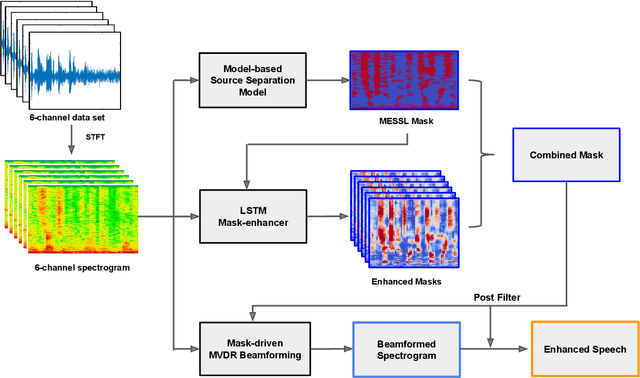

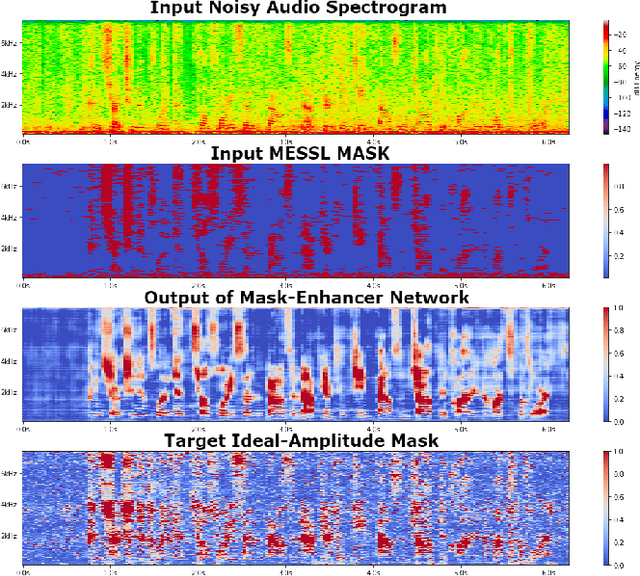
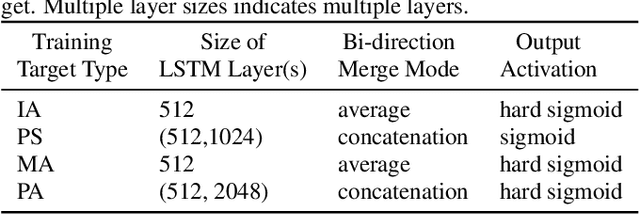
Recent works have shown that Deep Recurrent Neural Networks using the LSTM architecture can achieve strong single-channel speech enhancement by estimating time-frequency masks. However, these models do not naturally generalize to multi-channel inputs from varying microphone configurations. In contrast, spatial clustering techniques can achieve such generalization but lack a strong signal model. Our work proposes a combination of the two approaches. By using LSTMs to enhance spatial clustering based time-frequency masks, we achieve both the signal modeling performance of multiple single-channel LSTM-DNN speech enhancers and the signal separation performance and generality of multi-channel spatial clustering. We compare our proposed system to several baselines on the CHiME-3 dataset. We evaluate the quality of the audio from each system using SDR from the BSS\_eval toolkit and PESQ. We evaluate the intelligibility of the output of each system using word error rate from a Kaldi automatic speech recognizer.
CHiME-6 Challenge:Tackling Multispeaker Speech Recognition for Unsegmented Recordings
May 02, 2020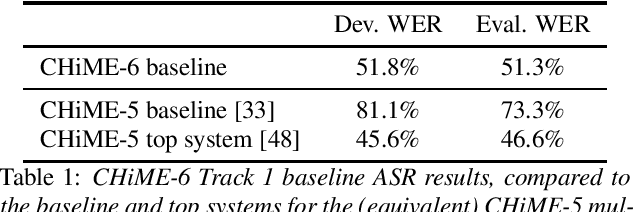

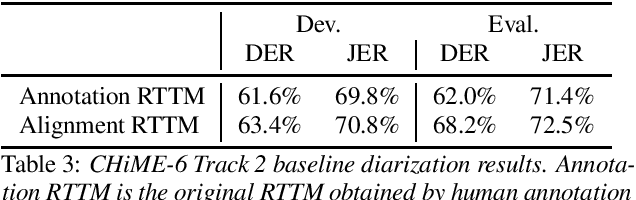

Following the success of the 1st, 2nd, 3rd, 4th and 5th CHiME challenges we organize the 6th CHiME Speech Separation and Recognition Challenge (CHiME-6). The new challenge revisits the previous CHiME-5 challenge and further considers the problem of distant multi-microphone conversational speech diarization and recognition in everyday home environments. Speech material is the same as the previous CHiME-5 recordings except for accurate array synchronization. The material was elicited using a dinner party scenario with efforts taken to capture data that is representative of natural conversational speech. This paper provides a baseline description of the CHiME-6 challenge for both segmented multispeaker speech recognition (Track 1) and unsegmented multispeaker speech recognition (Track 2). Of note, Track 2 is the first challenge activity in the community to tackle an unsegmented multispeaker speech recognition scenario with a complete set of reproducible open source baselines providing speech enhancement, speaker diarization, and speech recognition modules.
Autotagging music with conditional restricted Boltzmann machines
Mar 15, 2011
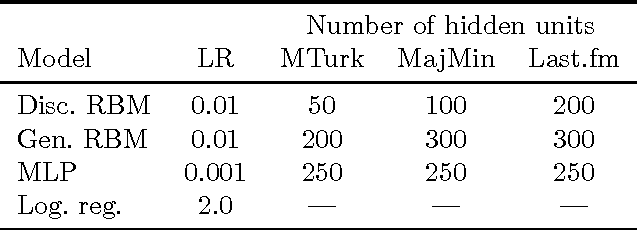
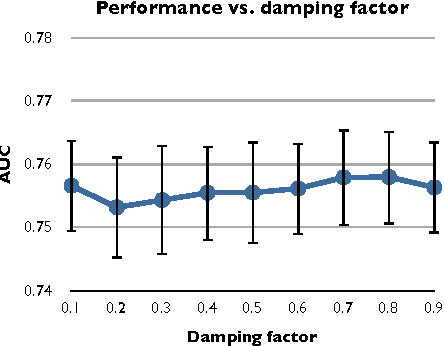
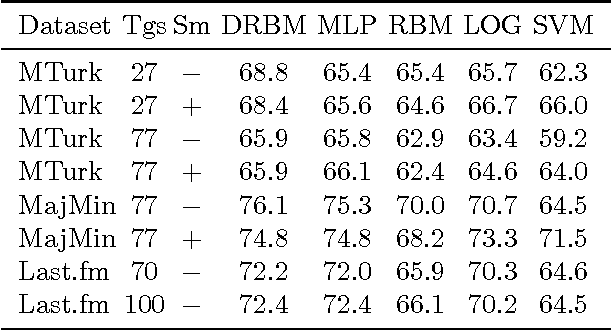
This paper describes two applications of conditional restricted Boltzmann machines (CRBMs) to the task of autotagging music. The first consists of training a CRBM to predict tags that a user would apply to a clip of a song based on tags already applied by other users. By learning the relationships between tags, this model is able to pre-process training data to significantly improve the performance of a support vector machine (SVM) autotagging. The second is the use of a discriminative RBM, a type of CRBM, to autotag music. By simultaneously exploiting the relationships among tags and between tags and audio-based features, this model is able to significantly outperform SVMs, logistic regression, and multi-layer perceptrons. In order to be applied to this problem, the discriminative RBM was generalized to the multi-label setting and four different learning algorithms for it were evaluated, the first such in-depth analysis of which we are aware.