 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Lexical and Contextual Coreference Resolution Systems Degrade Differently under Mention Noise? An Empirical Study on Scientific Software Mentions
Apr 02, 2026We present our participation in the SOMD 2026 shared task on cross-document software mention coreference resolution, where our systems ranked second across all three subtasks. We compare two fine-tuning-free approaches: Fuzzy Matching (FM), a lexical string-similarity method, and Context Aware Representations (CAR), which combines mention-level and document-level embeddings. Both achieve competitive performance across all subtasks (CoNLL F1 of 0.94-0.96), with CAR consistently outperforming FM by 1 point on the official test set, consistent with the high surface regularity of software names, which reduces the need for complex semantic reasoning. A controlled noise-injection study reveals complementary failure modes: as boundary noise increases, CAR loses only 0.07 F1 points from clean to fully corrupted input, compared to 0.20 for FM, whereas under mention substitution, FM degrades more gracefully (0.52 vs. 0.63). Our inference-time analysis shows that FM scales superlinearly with corpus size, whereas CAR scales approximately linearly, making CAR the more efficient choice at large scale. These findings suggest that system selection should be informed by both the noise profile of the upstream mention detector and the scale of the target corpus. We release our code to support future work on this underexplored task.
AstroConcepts: A Large-Scale Multi-Label Classification Corpus for Astrophysics
Apr 02, 2026Scientific multi-label text classification suffers from extreme class imbalance, where specialized terminology exhibits severe power-law distributions that challenge standard classification approaches. Existing scientific corpora lack comprehensive controlled vocabularies, focusing instead on broad categories and limiting systematic study of extreme imbalance. We introduce AstroConcepts, a corpus of English abstracts from 21,702 published astrophysics papers, labeled with 2,367 concepts from the Unified Astronomy Thesaurus. The corpus exhibits severe label imbalance, with 76% of concepts having fewer than 50 training examples. By releasing this resource, we enable systematic study of extreme class imbalance in scientific domains and establish strong baselines across traditional, neural, and vocabulary-constrained LLM methods. Our evaluation reveals three key patterns that provide new insights into scientific text classification. First, vocabulary-constrained LLMs achieve competitive performance relative to domain-adapted models in astrophysics classification, suggesting a potential for parameter-efficient approaches. Second, domain adaptation yields relatively larger improvements for rare, specialized terminology, although absolute performance remains limited across all methods. Third, we propose frequency-stratified evaluation to reveal performance patterns that are hidden by aggregate scores, thereby making robustness assessment central to scientific multi-label evaluation. These results offer actionable insights for scientific NLP and establish benchmarks for research on extreme imbalance.
Reservoir Computing: A New Paradigm for Neural Networks
Apr 03, 2025A Literature Review of Reservoir Computing. Even before Artificial Intelligence was its own field of computational science, humanity has tried to mimic the activity of the human brain. In the early 1940s the first artificial neuron models were created as purely mathematical concepts. Over the years, ideas from neuroscience and computer science were used to develop the modern Neural Network. The interest in these models rose quickly but fell when they failed to be successfully applied to practical applications, and rose again in the late 2000s with the drastic increase in computing power, notably in the field of natural language processing, for example with the state-of-the-art speech recognizer making heavy use of deep neural networks. Recurrent Neural Networks (RNNs), a class of neural networks with cycles in the network, exacerbates the difficulties of traditional neural nets. Slow convergence limiting the use to small networks, and difficulty to train through gradient-descent methods because of the recurrent dynamics have hindered research on RNNs, yet their biological plausibility and their capability to model dynamical systems over simple functions makes then interesting for computational researchers. Reservoir Computing emerges as a solution to these problems that RNNs traditionally face. Promising to be both theoretically sound and computationally fast, Reservoir Computing has already been applied successfully to numerous fields: natural language processing, computational biology and neuroscience, robotics, even physics. This survey will explore the history and appeal of both traditional feed-forward and recurrent neural networks, before describing the theory and models of this new reservoir computing paradigm. Finally recent papers using reservoir computing in a variety of scientific fields will be reviewed.
Experimenting with Large Language Models and vector embeddings in NASA SciX
Dec 21, 2023Open-source Large Language Models enable projects such as NASA SciX (i.e., NASA ADS) to think out of the box and try alternative approaches for information retrieval and data augmentation, while respecting data copyright and users' privacy. However, when large language models are directly prompted with questions without any context, they are prone to hallucination. At NASA SciX we have developed an experiment where we created semantic vectors for our large collection of abstracts and full-text content, and we designed a prompt system to ask questions using contextual chunks from our system. Based on a non-systematic human evaluation, the experiment shows a lower degree of hallucination and better responses when using Retrieval Augmented Generation. Further exploration is required to design new features and data augmentation processes at NASA SciX that leverages this technology while respecting the high level of trust and quality that the project holds.
Finite Gaussian Neurons: Defending against adversarial attacks by making neural networks say "I don't know"
Jun 13, 2023Since 2014, artificial neural networks have been known to be vulnerable to adversarial attacks, which can fool the network into producing wrong or nonsensical outputs by making humanly imperceptible alterations to inputs. While defenses against adversarial attacks have been proposed, they usually involve retraining a new neural network from scratch, a costly task. In this work, I introduce the Finite Gaussian Neuron (FGN), a novel neuron architecture for artificial neural networks. My works aims to: - easily convert existing models to Finite Gaussian Neuron architecture, - while preserving the existing model's behavior on real data, - and offering resistance against adversarial attacks. I show that converted and retrained Finite Gaussian Neural Networks (FGNN) always have lower confidence (i.e., are not overconfident) in their predictions over randomized and Fast Gradient Sign Method adversarial images when compared to classical neural networks, while maintaining high accuracy and confidence over real MNIST images. To further validate the capacity of Finite Gaussian Neurons to protect from adversarial attacks, I compare the behavior of FGNs to that of Bayesian Neural Networks against both randomized and adversarial images, and show how the behavior of the two architectures differs. Finally I show some limitations of the FGN models by testing them on the more complex SPEECHCOMMANDS task, against the stronger Carlini-Wagner and Projected Gradient Descent adversarial attacks.
Improving astroBERT using Semantic Textual Similarity
Nov 29, 2022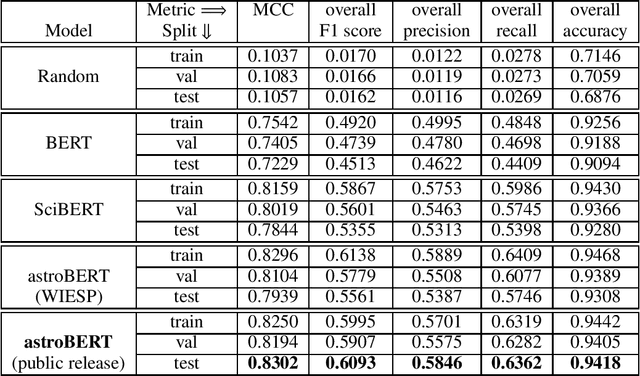
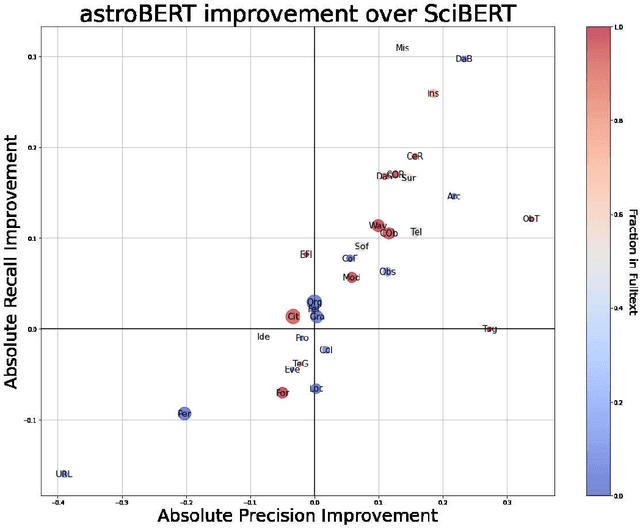
The NASA Astrophysics Data System (ADS) is an essential tool for researchers that allows them to explore the astronomy and astrophysics scientific literature, but it has yet to exploit recent advances in natural language processing. At ADASS 2021, we introduced astroBERT, a machine learning language model tailored to the text used in astronomy papers in ADS. In this work we: - announce the first public release of the astroBERT language model; - show how astroBERT improves over existing public language models on astrophysics specific tasks; - and detail how ADS plans to harness the unique structure of scientific papers, the citation graph and citation context, to further improve astroBERT.
Building astroBERT, a language model for Astronomy & Astrophysics
Dec 01, 2021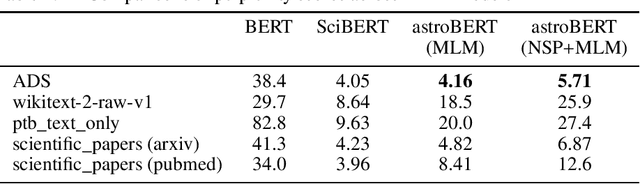
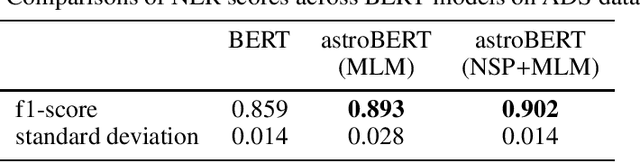
The existing search tools for exploring the NASA Astrophysics Data System (ADS) can be quite rich and empowering (e.g., similar and trending operators), but researchers are not yet allowed to fully leverage semantic search. For example, a query for "results from the Planck mission" should be able to distinguish between all the various meanings of Planck (person, mission, constant, institutions and more) without further clarification from the user. At ADS, we are applying modern machine learning and natural language processing techniques to our dataset of recent astronomy publications to train astroBERT, a deeply contextual language model based on research at Google. Using astroBERT, we aim to enrich the ADS dataset and improve its discoverability, and in particular we are developing our own named entity recognition tool. We present here our preliminary results and lessons learned.
Combining Spatial Clustering with LSTM Speech Models for Multichannel Speech Enhancement
Dec 02, 2020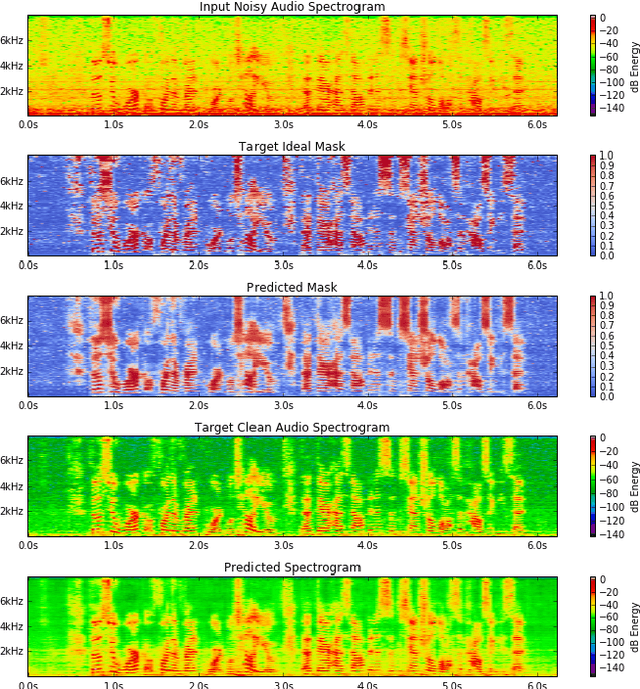
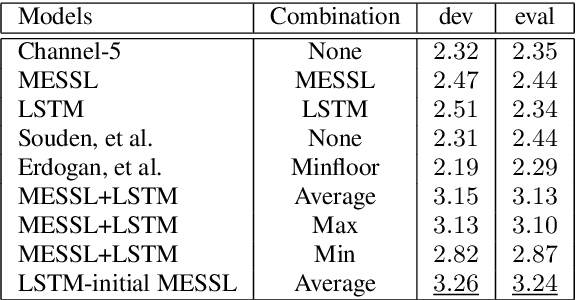
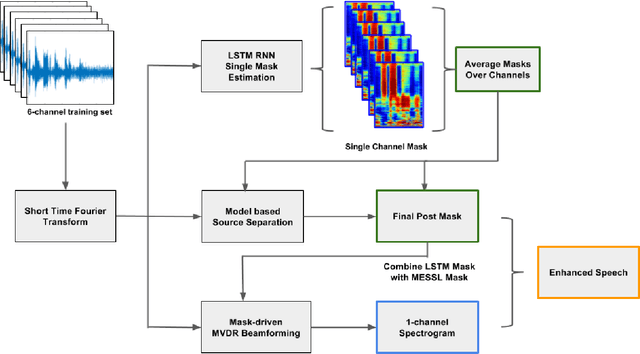
Recurrent neural networks using the LSTM architecture can achieve significant single-channel noise reduction. It is not obvious, however, how to apply them to multi-channel inputs in a way that can generalize to new microphone configurations. In contrast, spatial clustering techniques can achieve such generalization, but lack a strong signal model. This paper combines the two approaches to attain both the spatial separation performance and generality of multichannel spatial clustering and the signal modeling performance of multiple parallel single-channel LSTM speech enhancers. The system is compared to several baselines on the CHiME3 dataset in terms of speech quality predicted by the PESQ algorithm and word error rate of a recognizer trained on mis-matched conditions, in order to focus on generalization. Our experiments show that by combining the LSTM models with the spatial clustering, we reduce word error rate by 4.6\% absolute (17.2\% relative) on the development set and 11.2\% absolute (25.5\% relative) on test set compared with spatial clustering system, and reduce by 10.75\% (32.72\% relative) on development set and 6.12\% absolute (15.76\% relative) on test data compared with LSTM model.
Improved MVDR Beamforming Using LSTM Speech Models to Clean Spatial Clustering Masks
Dec 02, 2020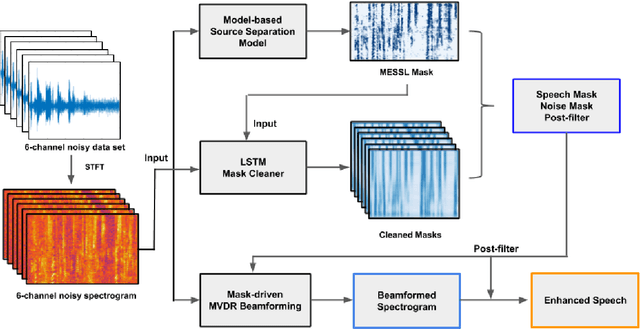
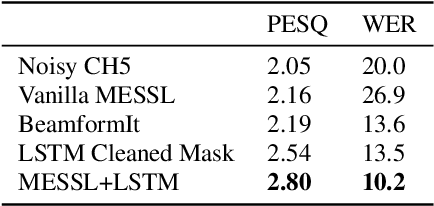
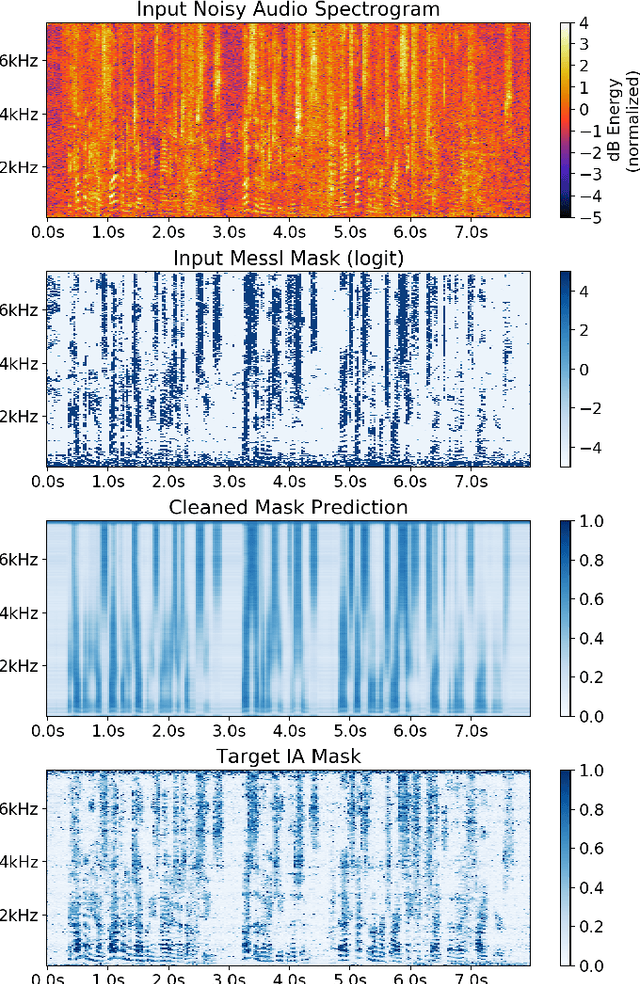
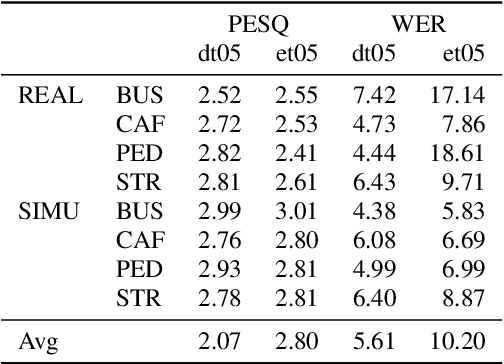
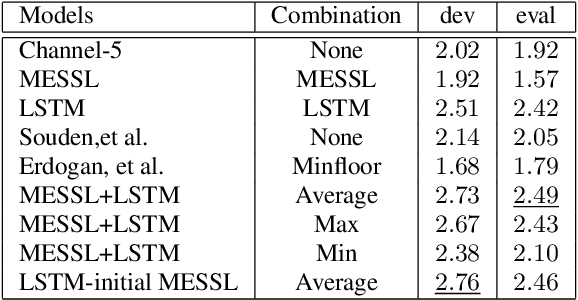
Spatial clustering techniques can achieve significant multi-channel noise reduction across relatively arbitrary microphone configurations, but have difficulty incorporating a detailed speech/noise model. In contrast, LSTM neural networks have successfully been trained to recognize speech from noise on single-channel inputs, but have difficulty taking full advantage of the information in multi-channel recordings. This paper integrates these two approaches, training LSTM speech models to clean the masks generated by the Model-based EM Source Separation and Localization (MESSL) spatial clustering method. By doing so, it attains both the spatial separation performance and generality of multi-channel spatial clustering and the signal modeling performance of multiple parallel single-channel LSTM speech enhancers. Our experiments show that when our system is applied to the CHiME-3 dataset of noisy tablet recordings, it increases speech quality as measured by the Perceptual Evaluation of Speech Quality (PESQ) algorithm and reduces the word error rate of the baseline CHiME-3 speech recognizer, as compared to the default BeamformIt beamformer.
Enhancement of Spatial Clustering-Based Time-Frequency Masks using LSTM Neural Networks
Dec 02, 2020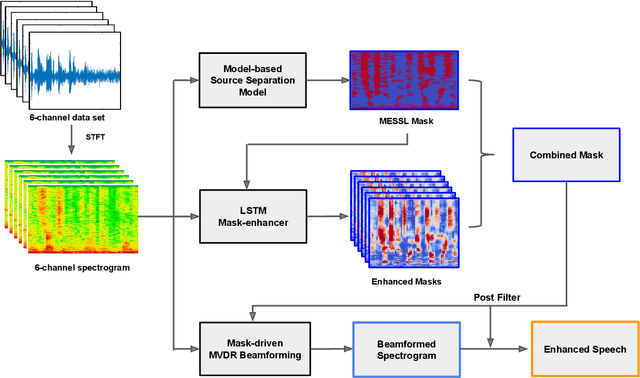

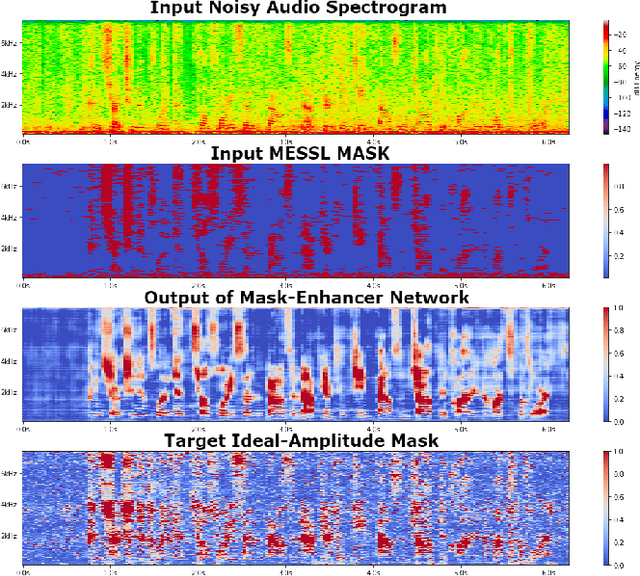
Recent works have shown that Deep Recurrent Neural Networks using the LSTM architecture can achieve strong single-channel speech enhancement by estimating time-frequency masks. However, these models do not naturally generalize to multi-channel inputs from varying microphone configurations. In contrast, spatial clustering techniques can achieve such generalization but lack a strong signal model. Our work proposes a combination of the two approaches. By using LSTMs to enhance spatial clustering based time-frequency masks, we achieve both the signal modeling performance of multiple single-channel LSTM-DNN speech enhancers and the signal separation performance and generality of multi-channel spatial clustering. We compare our proposed system to several baselines on the CHiME-3 dataset. We evaluate the quality of the audio from each system using SDR from the BSS\_eval toolkit and PESQ. We evaluate the intelligibility of the output of each system using word error rate from a Kaldi automatic speech recognizer.