 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do MLLMs hear? Examining reasoning with text and sound components in Multimodal Large Language Models
Jun 07, 2024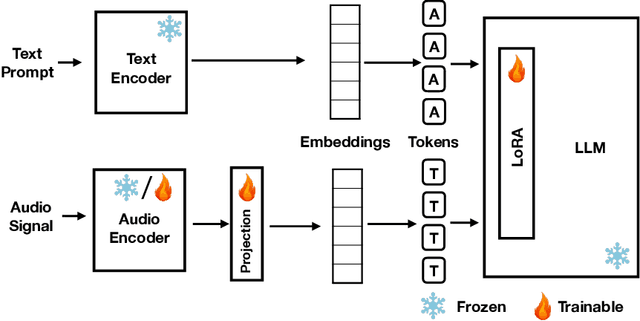
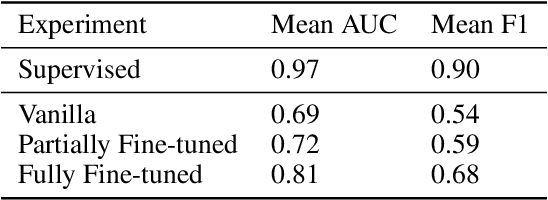
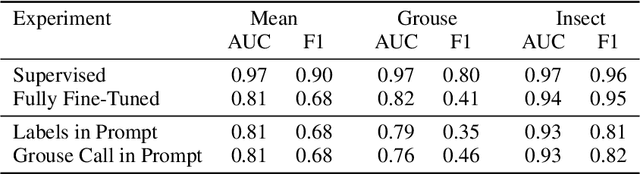
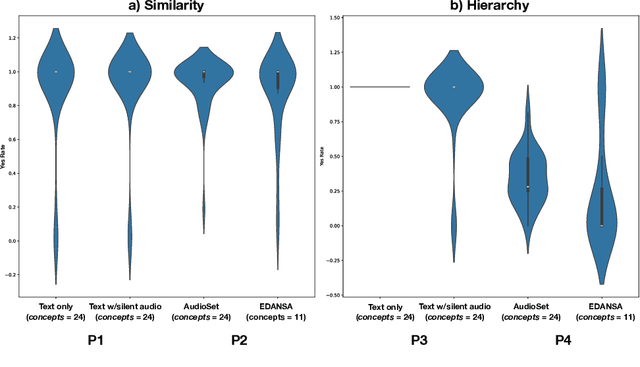
Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities, notably in connecting ideas and adhering to logical rules to solve problems. These models have evolved to accommodate various data modalities, including sound and images, known as multimodal LLMs (MLLMs), which are capable of describing images or sound recordings. Previous work has demonstrated that when the LLM component in MLLMs is frozen, the audio or visual encoder serves to caption the sound or image input facilitating text-based reasoning with the LLM component. We are interested in using the LLM's reasoning capabilities in order to facilitate classification. In this paper, we demonstrate through a captioning/classification experiment that an audio MLLM cannot fully leverage its LLM's text-based reasoning when generating audio captions. We also consider how this may be due to MLLMs separately representing auditory and textual information such that it severs the reasoning pathway from the LLM to the audio encoder.
Towards High Resolution Weather Monitoring with Sound Data
Sep 28, 2023Across various research domains, remotely-sensed weather products are valuable for answering many scientific questions; however, their temporal and spatial resolutions are often too coarse to answer many questions. For instance, in wildlife research, it's crucial to have fine-scaled, highly localized weather observations when studying animal movement and behavior. This paper harnesses acoustic data to identify variations in rain, wind and air temperature at different thresholds, with rain being the most successfully predicted. Training a model solely on acoustic data yields optimal results, but it demands labor-intensive sample labeling. Meanwhile, hourly satellite data from the MERRA-2 system, though sufficient for certain tasks, produced predictions that were notably less accurate in predict these acoustic labels. We find that acoustic classifiers can be trained from the MERRA-2 data that are more accurate than the raw MERRA-2 data itself. By using MERRA-2 to roughly identify rain in the acoustic data, we were able to produce a functional model without using human-validated labels. Since MERRA-2 has global coverage, our method offers a practical way to train rain models using acoustic datasets around the world.
Improved MVDR Beamforming Using LSTM Speech Models to Clean Spatial Clustering Masks
Dec 02, 2020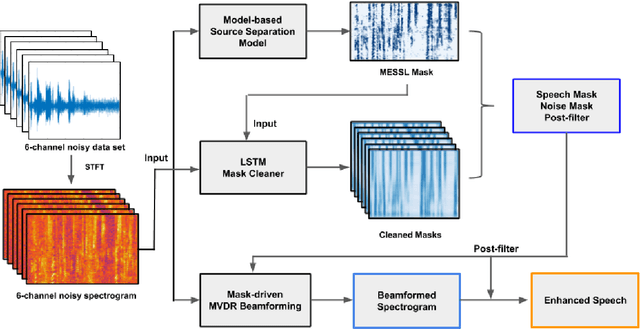
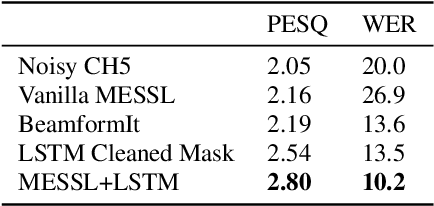
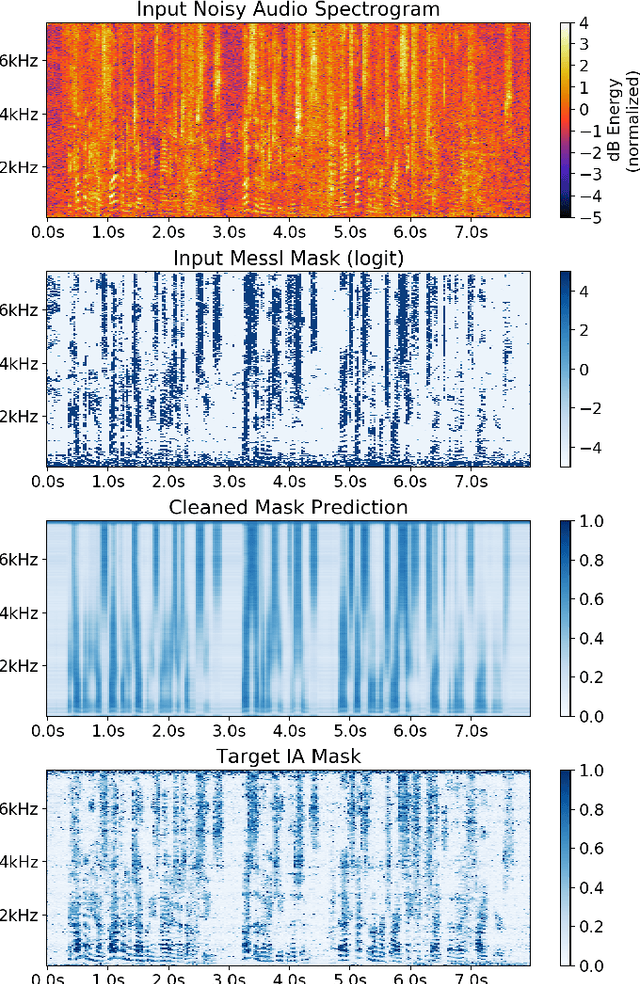
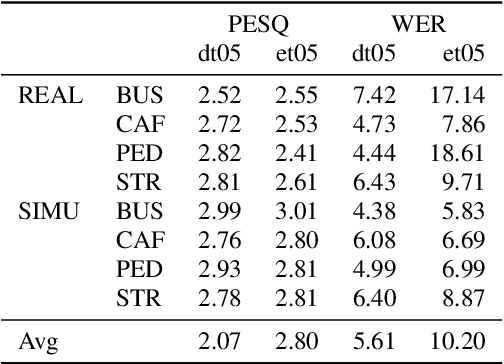
Spatial clustering techniques can achieve significant multi-channel noise reduction across relatively arbitrary microphone configurations, but have difficulty incorporating a detailed speech/noise model. In contrast, LSTM neural networks have successfully been trained to recognize speech from noise on single-channel inputs, but have difficulty taking full advantage of the information in multi-channel recordings. This paper integrates these two approaches, training LSTM speech models to clean the masks generated by the Model-based EM Source Separation and Localization (MESSL) spatial clustering method. By doing so, it attains both the spatial separation performance and generality of multi-channel spatial clustering and the signal modeling performance of multiple parallel single-channel LSTM speech enhancers. Our experiments show that when our system is applied to the CHiME-3 dataset of noisy tablet recordings, it increases speech quality as measured by the Perceptual Evaluation of Speech Quality (PESQ) algorithm and reduces the word error rate of the baseline CHiME-3 speech recognizer, as compared to the default BeamformIt beamformer.