 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepyAMPACT: A Score-Audio Alignment Toolkit for Performance Data Estimation and Multi-modal Processing
Dec 06, 2024pyAMPACT (Python-based Automatic Music Performance Analysis and Comparison Toolkit) links symbolic and audio music representations to facilitate score-informed estimation of performance data in audio as well as general linking of symbolic and audio music representations with a variety of annotations. pyAMPACT can read a range of symbolic formats and can output note-linked audio descriptors/performance data into MEI-formatted files. The audio analysis uses score alignment to calculate time-frequency regions of importance for each note in the symbolic representation from which to estimate a range of parameters. These include tuning-, dynamics-, and timbre-related performance descriptors, with timing-related information available from the score alignment. Beyond performance data estimation, pyAMPACT also facilitates multi-modal investigations through its infrastructure for linking symbolic representations and annotations to audio.
What do MLLMs hear? Examining reasoning with text and sound components in Multimodal Large Language Models
Jun 07, 2024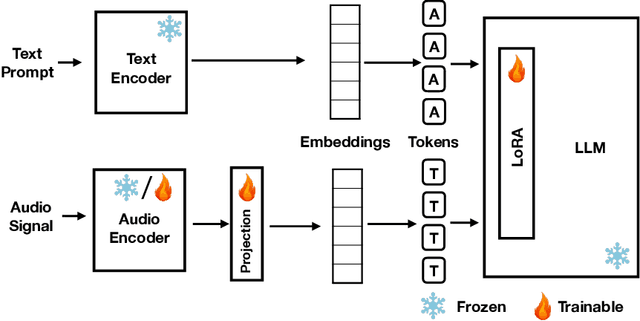
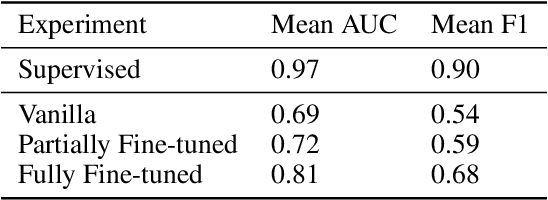
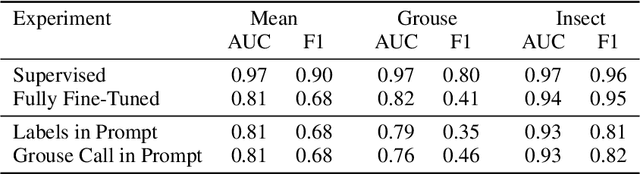
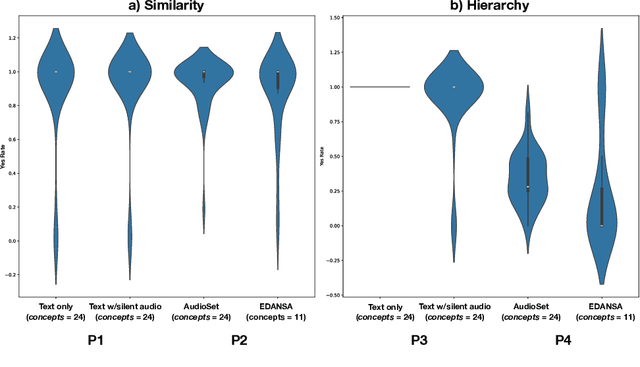
Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities, notably in connecting ideas and adhering to logical rules to solve problems. These models have evolved to accommodate various data modalities, including sound and images, known as multimodal LLMs (MLLMs), which are capable of describing images or sound recordings. Previous work has demonstrated that when the LLM component in MLLMs is frozen, the audio or visual encoder serves to caption the sound or image input facilitating text-based reasoning with the LLM component. We are interested in using the LLM's reasoning capabilities in order to facilitate classification. In this paper, we demonstrate through a captioning/classification experiment that an audio MLLM cannot fully leverage its LLM's text-based reasoning when generating audio captions. We also consider how this may be due to MLLMs separately representing auditory and textual information such that it severs the reasoning pathway from the LLM to the audio encoder.
Encoding Performance Data in MEI with the Automatic Music Performance Analysis and Comparison Toolkit
Nov 19, 2023

This paper presents a new method of encoding performance data in MEI using the recently added \texttt{<extData>} element. Performance data was extracted using the Automatic Music Performance Analysis and Comparison Toolkit (AMPACT) and encoded as a JSON object within an \texttt{<extData>} element linked to a specific musical note. A set of pop music vocals has was encoded to demonstrate both the range of descriptors that can be encoded in <extData> and how AMPACT can be used for extracting performance data in the absence of a fully specified musical score.
* 3 pages, 2 figures
Collaborative Song Dataset (CoSoD): An annotated dataset of multi-artist collaborations in popular music
Jul 13, 2023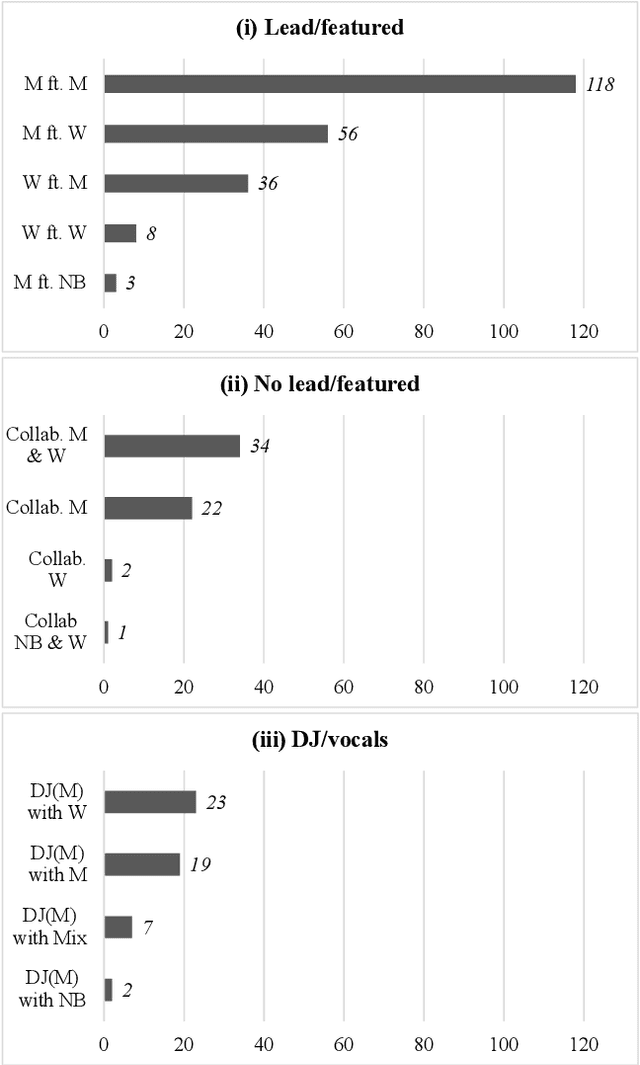
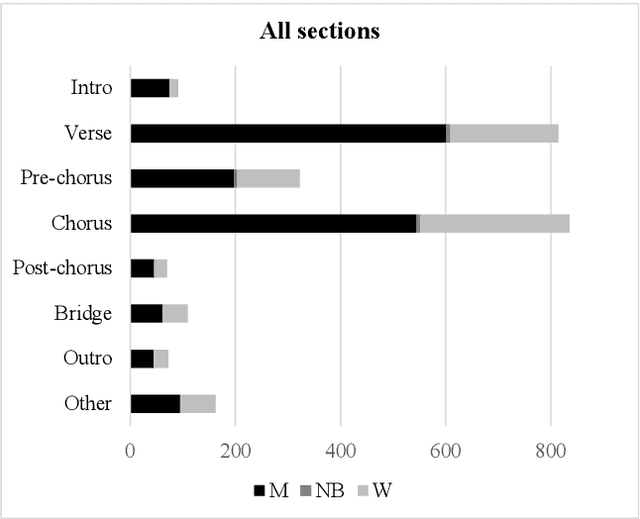
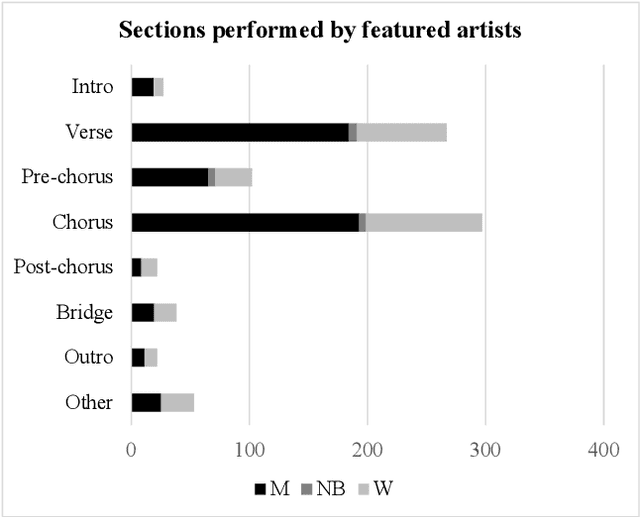
The Collaborative Song Dataset (CoSoD) is a corpus of 331 multi-artist collaborations from the 2010-2019 Billboard "Hot 100" year-end charts. The corpus is annotated with formal sections, aspects of vocal production (including reverberation, layering, panning, and gender of the performers), and relevant metadata. CoSoD complements other popular music datasets by focusing exclusively on musical collaborations between independent acts. In addition to facilitating the study of song form and vocal production, CoSoD allows for the in-depth study of gender as it relates to various timbral, pitch, and formal parameters in musical collaborations. In this paper, we detail the contents of the dataset and outline the annotation process. We also present an experiment using CoSoD that examines how the use of reverberation, layering, and panning are related to the gender of the artist. In this experiment, we find that men's voices are on average treated with less reverberation and occupy a more narrow position in the stereo mix than women's voices.
Beyond chord vocabularies: Exploiting pitch-relationships in a chord estimation metric
Jan 13, 2022
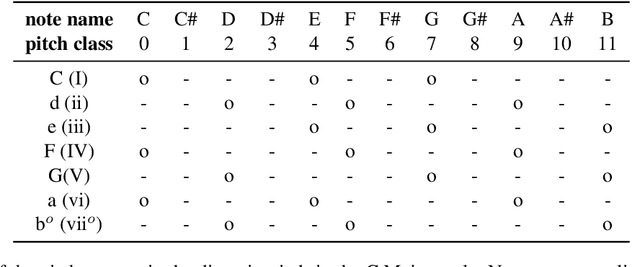
Chord estimation metrics treat chord labels as independent of one another. This fails to represent the pitch relationships between the chords in a meaningful way, resulting in evaluations that must make compromises with complex chord vocabularies and that often require time-consuming qualitative analyses to determine details about how a chord estimation algorithm performs. This paper presents an accuracy metric for chord estimation that compares the pitch content of the estimated chords against the ground truth that captures both the correct notes that are estimated and additional notes that are inserted into the estimate. This is not a stand-alone evaluation protocol but rather a metric that can be integrated as a weighting into existing evaluation approaches.
* Extended abstract, 3 pages, 2 tables
Digital Audio Processing Tools for Music Corpus Studies
Nov 09, 2021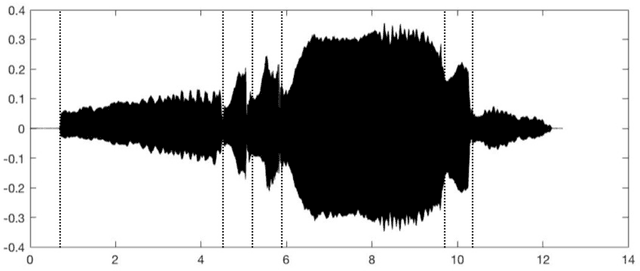
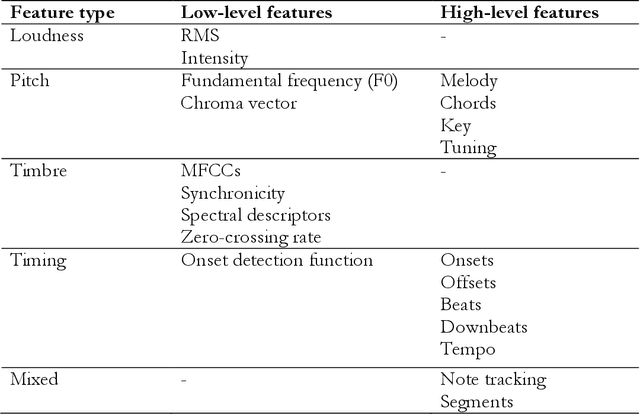
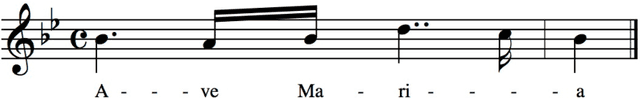
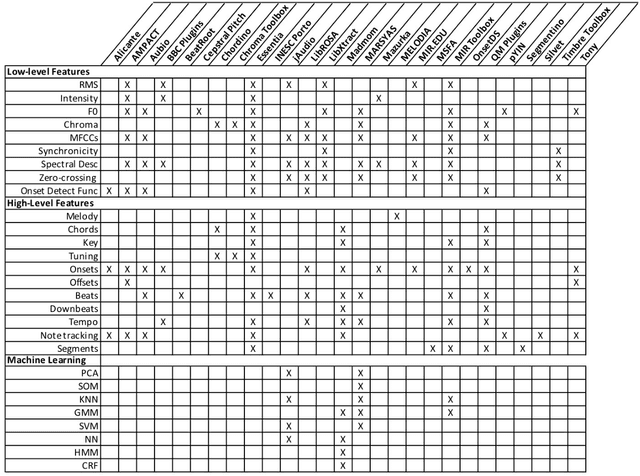
Digital audio processing tools offer music researchers the opportunity to examine both non-notated music and music as performance. This chapter summarises the types of information that can be extracted from audio as well as currently available audio tools for music corpus studies. The survey of extraction methods includes both a primer on signal processing and background theory on audio feature extraction. The survey of audio tools focuses on widely used tools, including both those with a graphical user interface, namely Audacity and Sonic Visualiser, and code-based tools written in the C/C++, Java, MATLAB, and Python computer programming languages.