 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQID$^2$: An Image-Conditioned Diffusion Model for Q-space Up-sampling of DWI Data
Sep 03, 2024We propose an image-conditioned diffusion model to estimate high angular resolution diffusion weighted imaging (DWI) from a low angular resolution acquisition. Our model, which we call QID$^2$, takes as input a set of low angular resolution DWI data and uses this information to estimate the DWI data associated with a target gradient direction. We leverage a U-Net architecture with cross-attention to preserve the positional information of the reference images, further guiding the target image generation. We train and evaluate QID$^2$ on single-shell DWI samples curated from the Human Connectome Project (HCP) dataset. Specifically, we sub-sample the HCP gradient directions to produce low angular resolution DWI data and train QID$^2$ to reconstruct the missing high angular resolution samples. We compare QID$^2$ with two state-of-the-art GAN models. Our results demonstrate that QID$^2$ not only achieves higher-quality generated images, but it consistently outperforms the GAN models in downstream tensor estimation across multiple metrics. Taken together, this study highlights the potential of diffusion models, and QID$^2$ in particular, for q-space up-sampling, thus offering a promising toolkit for clinical and research applications.
A Lesion-aware Edge-based Graph Neural Network for Predicting Language Ability in Patients with Post-stroke Aphasia
Sep 03, 2024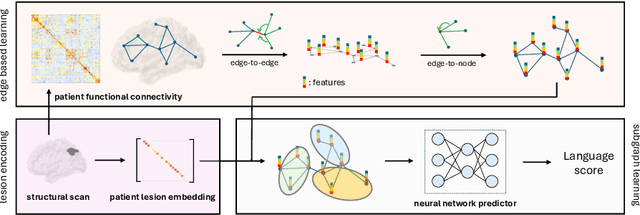



We propose a lesion-aware graph neural network (LEGNet) to predict language ability from resting-state fMRI (rs-fMRI) connectivity in patients with post-stroke aphasia. Our model integrates three components: an edge-based learning module that encodes functional connectivity between brain regions, a lesion encoding module, and a subgraph learning module that leverages functional similarities for prediction. We use synthetic data derived from the Human Connectome Project (HCP) for hyperparameter tuning and model pretraining. We then evaluate the performance using repeated 10-fold cross-validation on an in-house neuroimaging dataset of post-stroke aphasia. Our results demonstrate that LEGNet outperforms baseline deep learning methods in predicting language ability. LEGNet also exhibits superior generalization ability when tested on a second in-house dataset that was acquired under a slightly different neuroimaging protocol. Taken together, the results of this study highlight the potential of LEGNet in effectively learning the relationships between rs-fMRI connectivity and language ability in a patient cohort with brain lesions for improved post-stroke aphasia evaluation.
Re-ENACT: Reinforcement Learning for Emotional Speech Generation using Actor-Critic Strategy
Aug 04, 2024



In this paper, we propose the first method to modify the prosodic features of a given speech signal using actor-critic reinforcement learning strategy. Our approach uses a Bayesian framework to identify contiguous segments of importance that links segments of the given utterances to perception of emotions in humans. We train a neural network to produce the variational posterior of a collection of Bernoulli random variables; our model applies a Markov prior on it to ensure continuity. A sample from this distribution is used for downstream emotion prediction. Further, we train the neural network to predict a soft assignment over emotion categories as the target variable. In the next step, we modify the prosodic features (pitch, intensity, and rhythm) of the masked segment to increase the score of target emotion. We employ an actor-critic reinforcement learning to train the prosody modifier by discretizing the space of modifications. Further, it provides a simple solution to the problem of gradient computation through WSOLA operation for rhythm manipulation. Our experiments demonstrate that this framework changes the perceived emotion of a given speech utterance to the target. Further, we show that our unified technique is on par with state-of-the-art emotion conversion models from supervised and unsupervised domains that require pairwise training.
mSPD-NN: A Geometrically Aware Neural Framework for Biomarker Discovery from Functional Connectomics Manifolds
Mar 27, 2023



Connectomics has emerged as a powerful tool in neuroimaging and has spurred recent advancements in statistical and machine learning methods for connectivity data. Despite connectomes inhabiting a matrix manifold, most analytical frameworks ignore the underlying data geometry. This is largely because simple operations, such as mean estimation, do not have easily computable closed-form solutions. We propose a geometrically aware neural framework for connectomes, i.e., the mSPD-NN, designed to estimate the geodesic mean of a collections of symmetric positive definite (SPD) matrices. The mSPD-NN is comprised of bilinear fully connected layers with tied weights and utilizes a novel loss function to optimize the matrix-normal equation arising from Fr\'echet mean estimation. Via experiments on synthetic data, we demonstrate the efficacy of our mSPD-NN against common alternatives for SPD mean estimation, providing competitive performance in terms of scalability and robustness to noise. We illustrate the real-world flexibility of the mSPD-NN in multiple experiments on rs-fMRI data and demonstrate that it uncovers stable biomarkers associated with subtle network differences among patients with ADHD-ASD comorbidities and healthy controls.
A Comparative Study of Data Augmentation Techniques for Deep Learning Based Emotion Recognition
Nov 09, 2022



Automated emotion recognition in speech is a long-standing problem. While early work on emotion recognition relied on hand-crafted features and simple classifiers, the field has now embraced end-to-end feature learning and classification using deep neural networks. In parallel to these models, researchers have proposed several data augmentation techniques to increase the size and variability of existing labeled datasets. Despite many seminal contributions in the field, we still have a poor understanding of the interplay between the network architecture and the choice of data augmentation. Moreover, only a handful of studies demonstrate the generalizability of a particular model across multiple datasets, which is a prerequisite for robust real-world performance. In this paper, we conduct a comprehensive evaluation of popular deep learning approaches for emotion recognition. To eliminate bias, we fix the model architectures and optimization hyperparameters using the VESUS dataset and then use repeated 5-fold cross validation to evaluate the performance on the IEMOCAP and CREMA-D datasets. Our results demonstrate that long-range dependencies in the speech signal are critical for emotion recognition and that speed/rate augmentation offers the most robust performance gain across models.
A Diffeomorphic Flow-based Variational Framework for Multi-speaker Emotion Conversion
Nov 09, 2022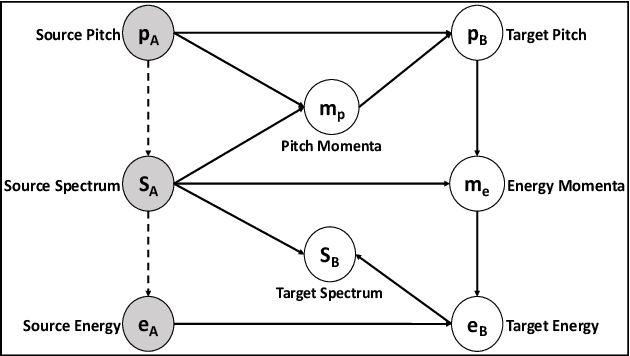
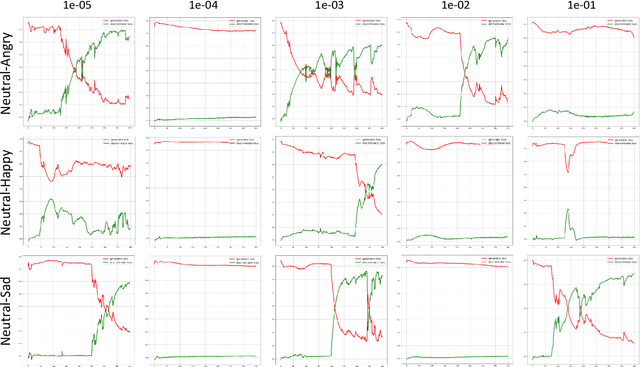
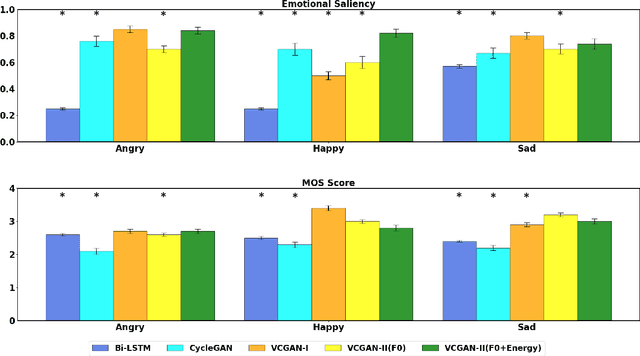
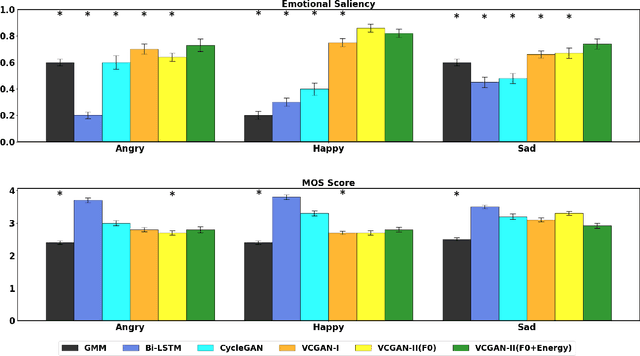
This paper introduces a new framework for non-parallel emotion conversion in speech. Our framework is based on two key contributions. First, we propose a stochastic version of the popular CycleGAN model. Our modified loss function introduces a Kullback Leibler (KL) divergence term that aligns the source and target data distributions learned by the generators, thus overcoming the limitations of sample wise generation. By using a variational approximation to this stochastic loss function, we show that our KL divergence term can be implemented via a paired density discriminator. We term this new architecture a variational CycleGAN (VCGAN). Second, we model the prosodic features of target emotion as a smooth and learnable deformation of the source prosodic features. This approach provides implicit regularization that offers key advantages in terms of better range alignment to unseen and out of distribution speakers. We conduct rigorous experiments and comparative studies to demonstrate that our proposed framework is fairly robust with high performance against several state-of-the-art baselines.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
Prospective Learning: Back to the Future
Jan 19, 2022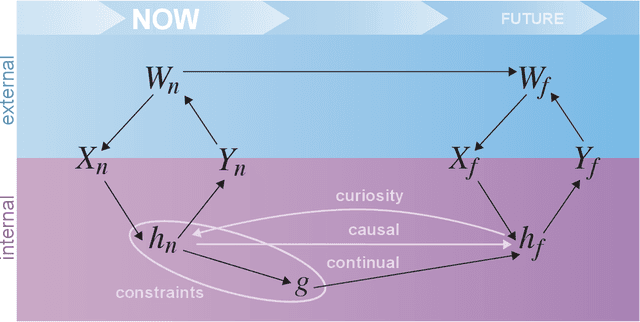

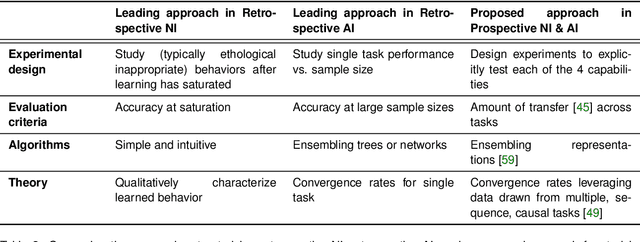
Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
A Deep-Bayesian Framework for Adaptive Speech Duration Modification
Jul 11, 2021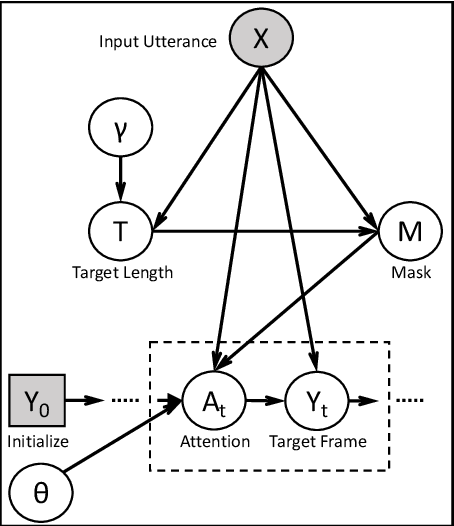

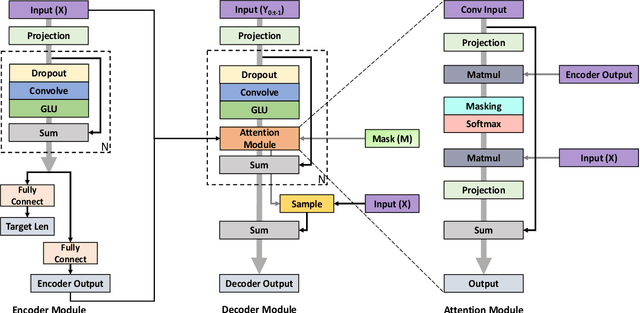
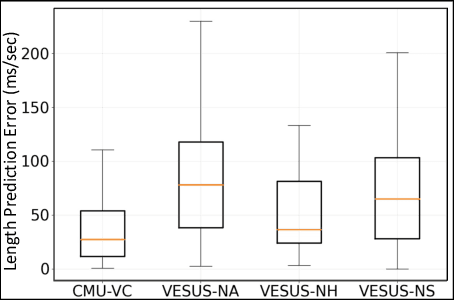
We propose the first method to adaptively modify the duration of a given speech signal. Our approach uses a Bayesian framework to define a latent attention map that links frames of the input and target utterances. We train a masked convolutional encoder-decoder network to produce this attention map via a stochastic version of the mean absolute error loss function; our model also predicts the length of the target speech signal using the encoder embeddings. The predicted length determines the number of steps for the decoder operation. During inference, we generate the attention map as a proxy for the similarity matrix between the given input speech and an unknown target speech signal. Using this similarity matrix, we compute a warping path of alignment between the two signals. Our experiments demonstrate that this adaptive framework produces similar results to dynamic time warping, which relies on a known target signal, on both voice conversion and emotion conversion tasks. We also show that our technique results in a high quality of generated speech that is on par with state-of-the-art vocoders.
A Matrix Autoencoder Framework to Align the Functional and Structural Connectivity Manifolds as Guided by Behavioral Phenotypes
May 30, 2021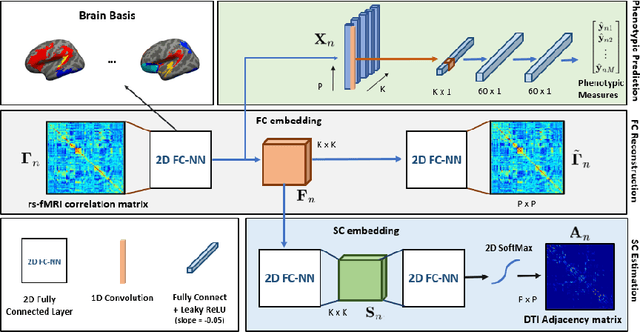
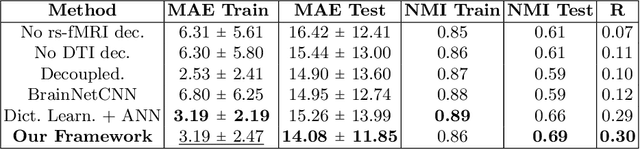
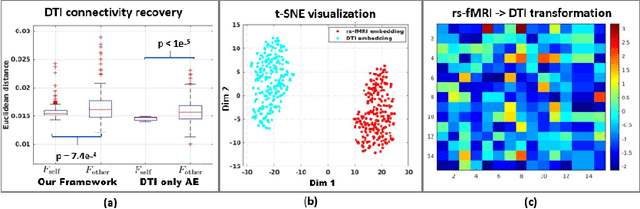
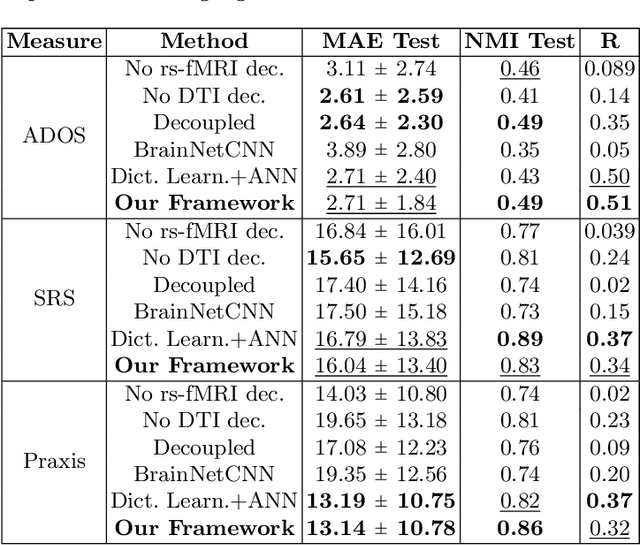
We propose a novel matrix autoencoder to map functional connectomes from resting state fMRI (rs-fMRI) to structural connectomes from Diffusion Tensor Imaging (DTI), as guided by subject-level phenotypic measures. Our specialized autoencoder infers a low dimensional manifold embedding for the rs-fMRI correlation matrices that mimics a canonical outer-product decomposition. The embedding is simultaneously used to reconstruct DTI tractography matrices via a second manifold alignment decoder and to predict inter-subject phenotypic variability via an artificial neural network. We validate our framework on a dataset of 275 healthy individuals from the Human Connectome Project database and on a second clinical dataset consisting of 57 subjects with Autism Spectrum Disorder. We demonstrate that the model reliably recovers structural connectivity patterns across individuals, while robustly extracting predictive and interpretable brain biomarkers in a cross-validated setting. Finally, our framework outperforms several baselines at predicting behavioral phenotypes in both real-world datasets.