 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep-Bayesian Framework for Adaptive Speech Duration Modification
Paper and Code
Jul 11, 2021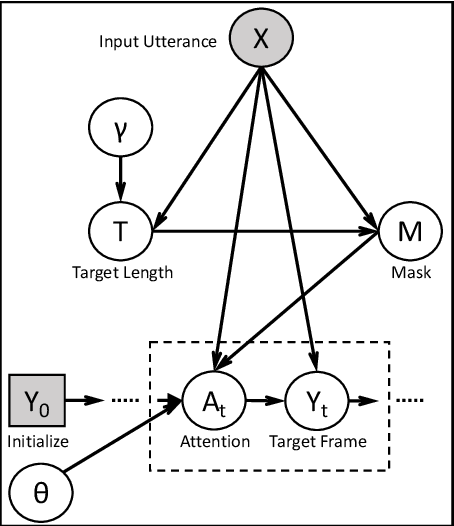

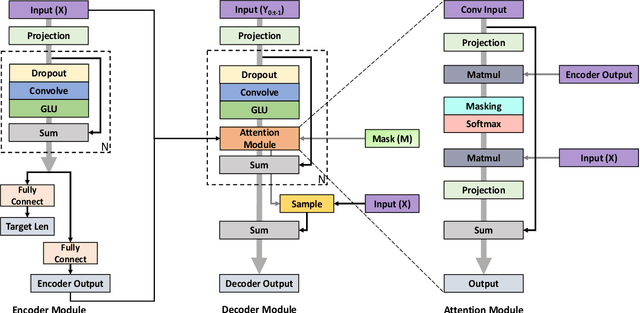
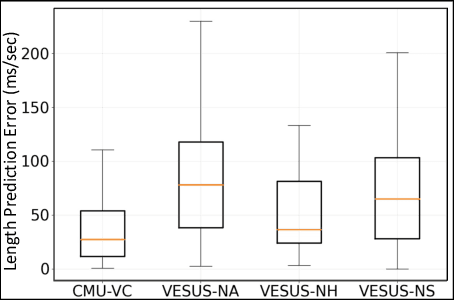
We propose the first method to adaptively modify the duration of a given speech signal. Our approach uses a Bayesian framework to define a latent attention map that links frames of the input and target utterances. We train a masked convolutional encoder-decoder network to produce this attention map via a stochastic version of the mean absolute error loss function; our model also predicts the length of the target speech signal using the encoder embeddings. The predicted length determines the number of steps for the decoder operation. During inference, we generate the attention map as a proxy for the similarity matrix between the given input speech and an unknown target speech signal. Using this similarity matrix, we compute a warping path of alignment between the two signals. Our experiments demonstrate that this adaptive framework produces similar results to dynamic time warping, which relies on a known target signal, on both voice conversion and emotion conversion tasks. We also show that our technique results in a high quality of generated speech that is on par with state-of-the-art vocoders.