 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHermEIS: A Parallel Multichannel Approach to Rapid Spectral Characterization of Neural MEAs
Mar 12, 2024The promise of increasing channel counts in high density ($> 10^4$) neural Microelectrode Arrays (MEAs) for high resolution recording comes with the curse of developing faster characterization strategies for concurrent acquisition of multichannel electrode integrities over a wide frequency spectrum. To circumvent the latency associated with the current multiplexed technique for impedance acquisition, it is common practice to resort to the single frequency impedance measurement (i.e. $Z_{1 \text{kHz}}$). This, however, does not offer sufficient spectral impedance information crucial for determining the capacity of electrodes at withstanding slow and fast-changing stimulus and recordings. In this work, we present \textit{HermEIS}, a novel approach that leverages single cycle in-phase and quadrature signal integrations for reducing the massive data throughput characteristic of such high density acquisition systems. As an initial proof-of-concept, we demonstrate over $6$ decades of impedance bandwidth ($5\times10^{-2} - 5\times10^{4}\text{ Hz}$) in a parallel $4$-channel potentiostatic setup composed of a custom PCB with off-the-shelf electronics working in tandem with an FPGA.
Pix2HDR -- A pixel-wise acquisition and deep learning-based synthesis approach for high-speed HDR videos
Oct 24, 2023Accurately capturing dynamic scenes with wide-ranging motion and light intensity is crucial for many vision applications. However, acquiring high-speed high dynamic range (HDR) video is challenging because the camera's frame rate restricts its dynamic range. Existing methods sacrifice speed to acquire multi-exposure frames. Yet, misaligned motion in these frames can still pose complications for HDR fusion algorithms, resulting in artifacts. Instead of frame-based exposures, we sample the videos using individual pixels at varying exposures and phase offsets. Implemented on a pixel-wise programmable image sensor, our sampling pattern simultaneously captures fast motion at a high dynamic range. We then transform pixel-wise outputs into an HDR video using end-to-end learned weights from deep neural networks, achieving high spatiotemporal resolution with minimized motion blurring. We demonstrate aliasing-free HDR video acquisition at 1000 FPS, resolving fast motion under low-light conditions and against bright backgrounds - both challenging conditions for conventional cameras. By combining the versatility of pixel-wise sampling patterns with the strength of deep neural networks at decoding complex scenes, our method greatly enhances the vision system's adaptability and performance in dynamic conditions.
Neuromorphic Place Cells
Oct 16, 2023A neuromorphic SLAM system shows potential for more efficient implementation than its traditional counterpart. We demonstrate a mixed-mode implementation for spatial encoding neurons including theta cells, vector cells and place cells. Together, they form a biologically plausible network that could reproduce the localization functionality of place cells. Experimental results validate the robustness of our model when suffering from variations of analog circuits. We provide a foundation for implementing dynamic neuromorphic SLAM systems and inspirations for the formation of spatial cells in biology.
Prospective Learning: Back to the Future
Jan 19, 2022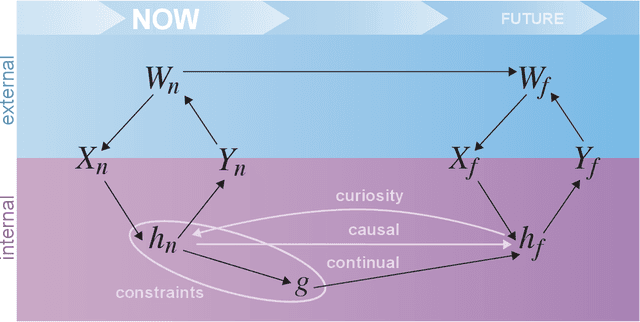

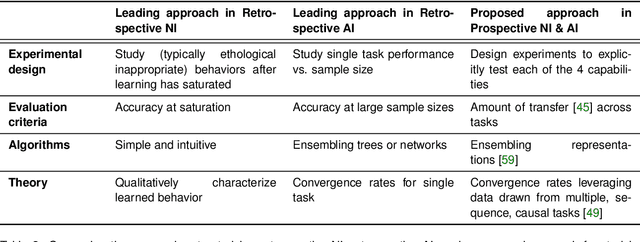
Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
A Neuromorphic Proto-Object Based Dynamic Visual Saliency Model with an FPGA Implementation
Mar 12, 2020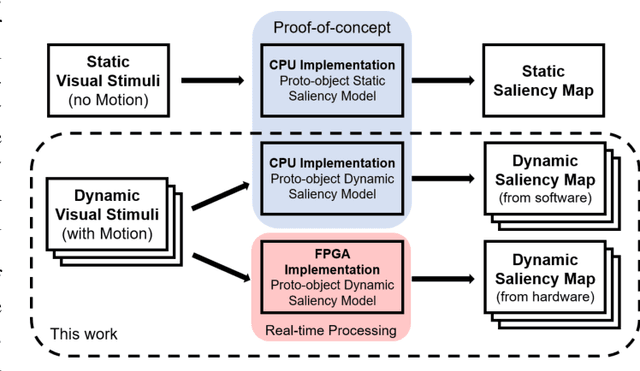
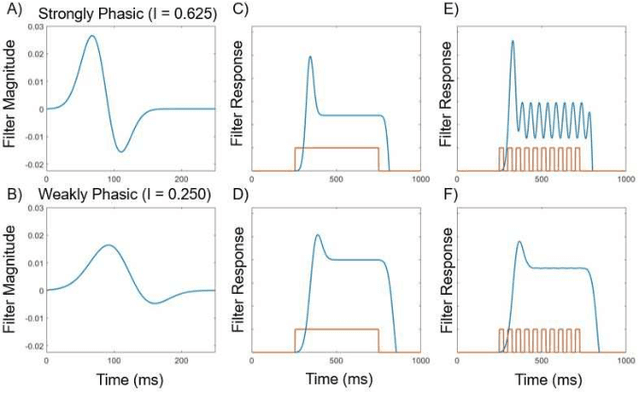
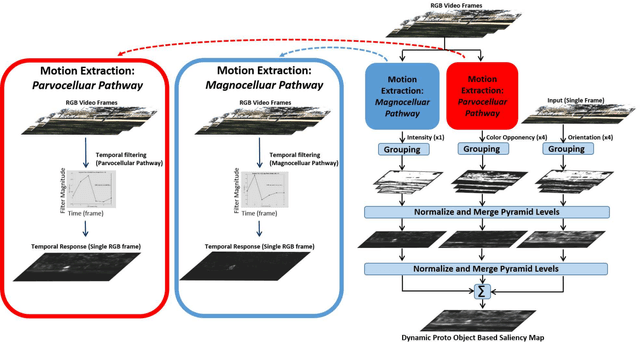
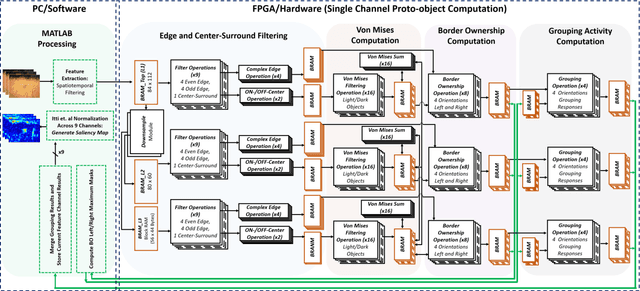
The ability to attend to salient regions of a visual scene is an innate and necessary preprocessing step for both biological and engineered systems performing high-level visual tasks (e.g. object detection, tracking, and classification). Computational efficiency, in regard to processing bandwidth and speed, is improved by only devoting computational resources to salient regions of the visual stimuli. In this paper, we first present a biologically-plausible, bottom-up, dynamic visual saliency model based on the notion of proto-objects. This is achieved by incorporating the temporal characteristics of the visual stimulus into the model, similarly to the manner in which early stages of the human visual system extracts temporal information. This model outperforms state-of-the-art dynamic visual saliency models in predicting human eye fixations on a commonly-used video dataset with associated eye tracking data. Secondly, for this model to have practical applications, it must be capable of performing its computations in real-time under lowpower, small-size, and lightweight constraints. To address this, we introduce a Field-Programmable Gate Array implementation of the model on an Opal Kelly 7350 Kintex-7 board. This novel hardware implementation allows for processing of up to 23.35 frames per second running on a 100 MHz clock -- better than 26x speedup from the software implementation.
Large-Scale Neuromorphic Spiking Array Processors: A quest to mimic the brain
May 23, 2018
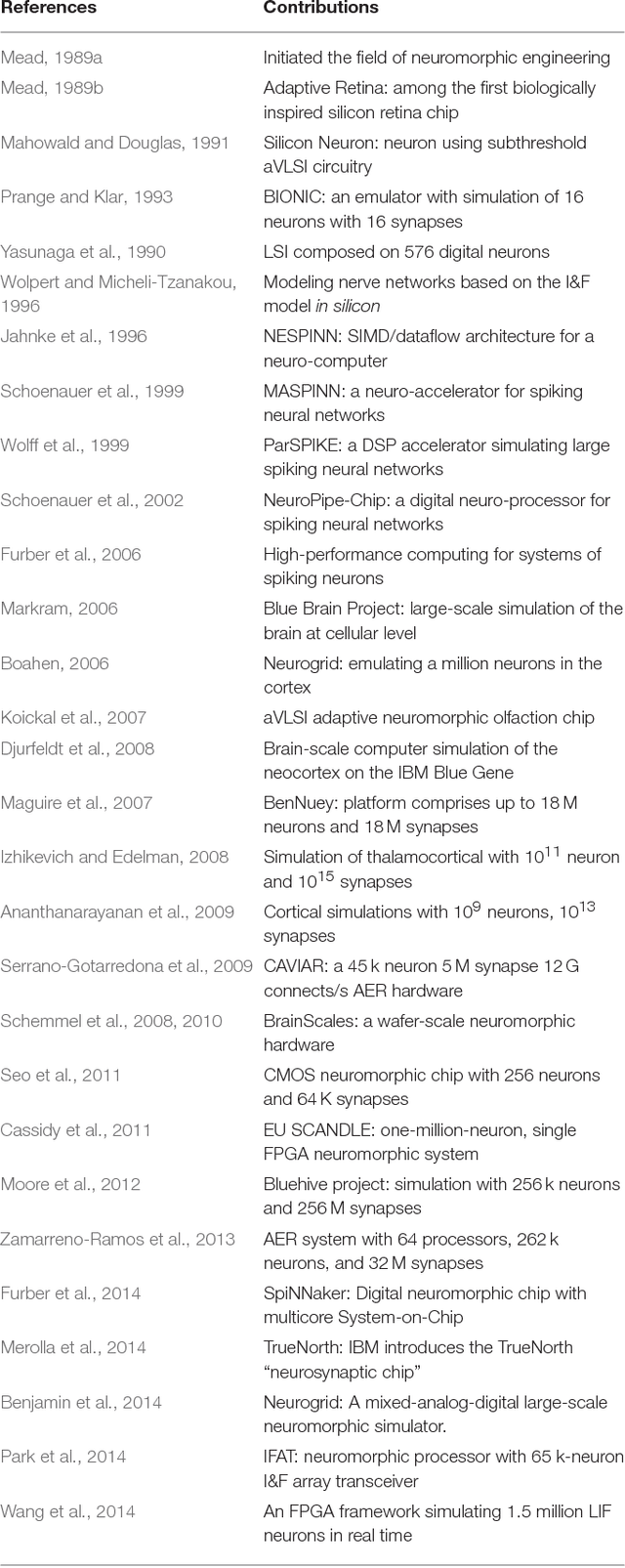
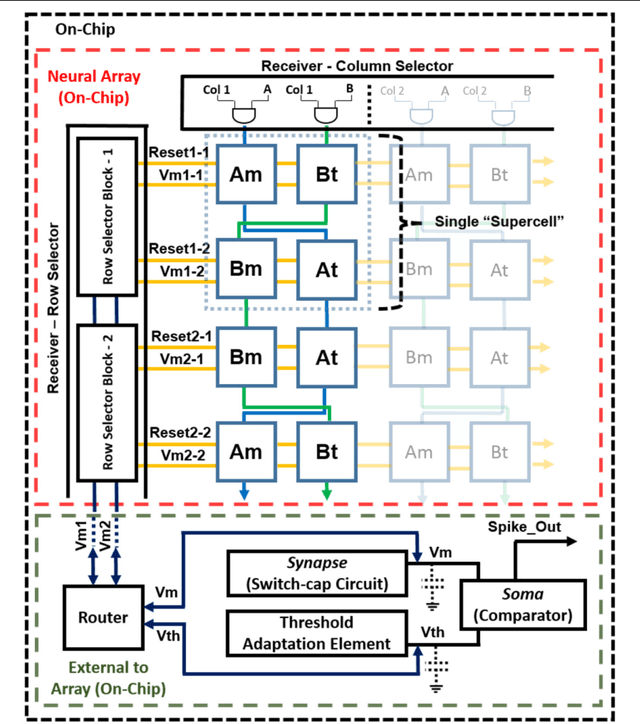
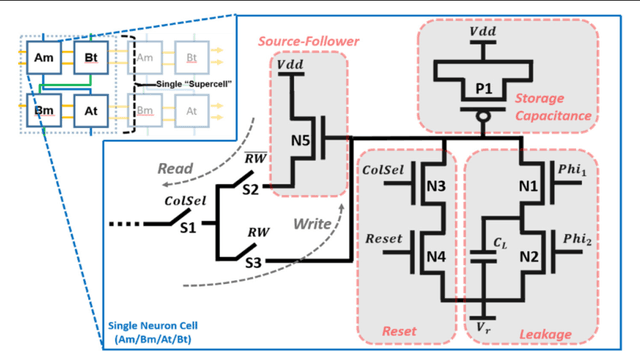
Neuromorphic engineering (NE) encompasses a diverse range of approaches to information processing that are inspired by neurobiological systems, and this feature distinguishes neuromorphic systems from conventional computing systems. The brain has evolved over billions of years to solve difficult engineering problems by using efficient, parallel, low-power computation. The goal of NE is to design systems capable of brain-like computation. Numerous large-scale neuromorphic projects have emerged recently. This interdisciplinary field was listed among the top 10 technology breakthroughs of 2014 by the MIT Technology Review and among the top 10 emerging technologies of 2015 by the World Economic Forum. NE has two-way goals: one, a scientific goal to understand the computational properties of biological neural systems by using models implemented in integrated circuits (ICs); second, an engineering goal to exploit the known properties of biological systems to design and implement efficient devices for engineering applications. Building hardware neural emulators can be extremely useful for simulating large-scale neural models to explain how intelligent behavior arises in the brain. The principle advantages of neuromorphic emulators are that they are highly energy efficient, parallel and distributed, and require a small silicon area. Thus, compared to conventional CPUs, these neuromorphic emulators are beneficial in many engineering applications such as for the porting of deep learning algorithms for various recognitions tasks. In this review article, we describe some of the most significant neuromorphic spiking emulators, compare the different architectures and approaches used by them, illustrate their advantages and drawbacks, and highlight the capabilities that each can deliver to neural modelers.
Fast Neuromimetic Object Recognition using FPGA Outperforms GPU Implementations
Oct 31, 2015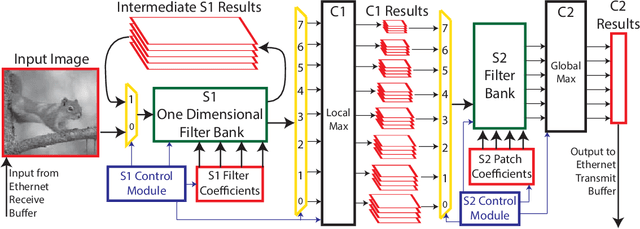
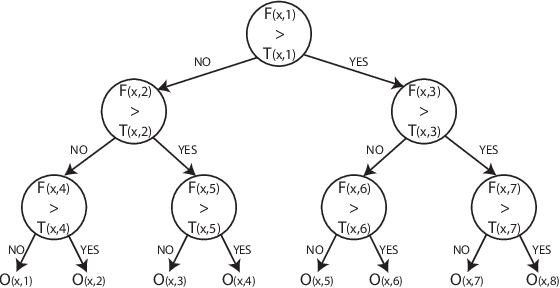
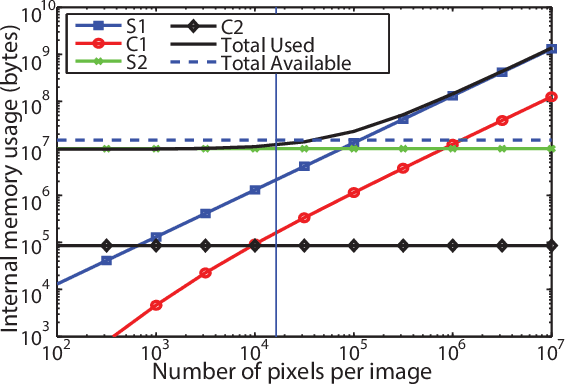
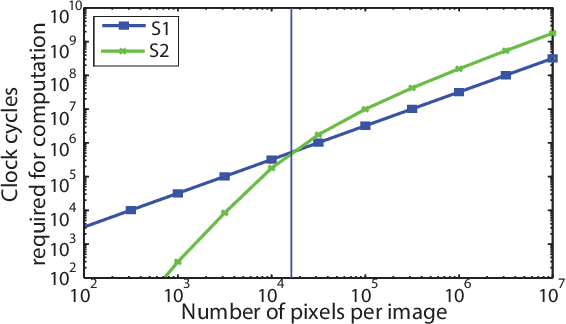
Recognition of objects in still images has traditionally been regarded as a difficult computational problem. Although modern automated methods for visual object recognition have achieved steadily increasing recognition accuracy, even the most advanced computational vision approaches are unable to obtain performance equal to that of humans. This has led to the creation of many biologically-inspired models of visual object recognition, among them the HMAX model. HMAX is traditionally known to achieve high accuracy in visual object recognition tasks at the expense of significant computational complexity. Increasing complexity, in turn, increases computation time, reducing the number of images that can be processed per unit time. In this paper we describe how the computationally intensive, biologically inspired HMAX model for visual object recognition can be modified for implementation on a commercial Field Programmable Gate Array, specifically the Xilinx Virtex 6 ML605 evaluation board with XC6VLX240T FPGA. We show that with minor modifications to the traditional HMAX model we can perform recognition on images of size 128x128 pixels at a rate of 190 images per second with a less than 1% loss in recognition accuracy in both binary and multi-class visual object recognition tasks.
* 14 pages, 8 figures, 5 tables
Bioinspired Visual Motion Estimation
Oct 31, 2015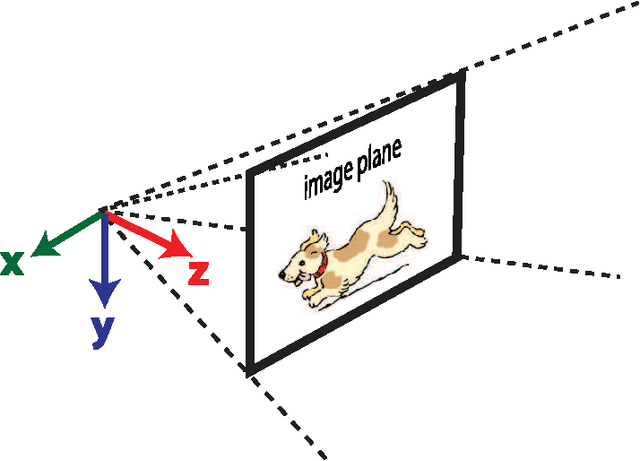
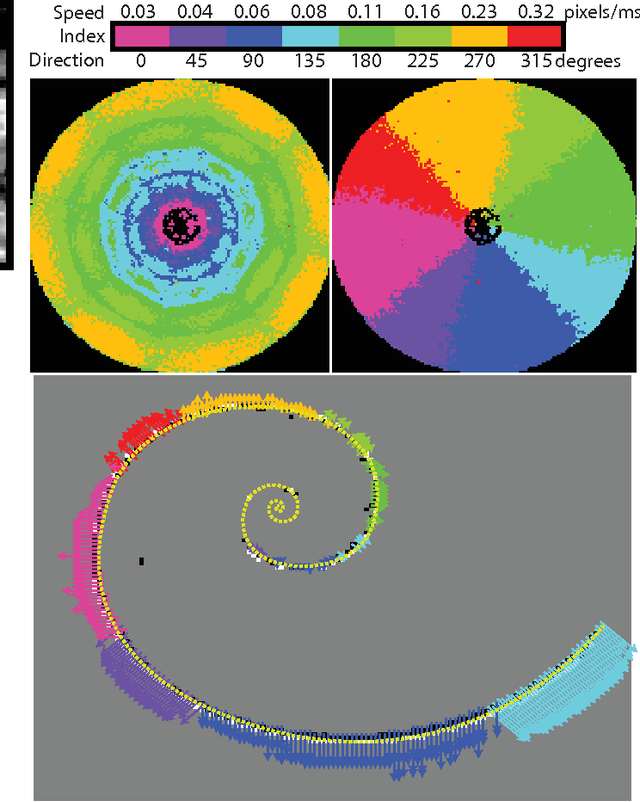

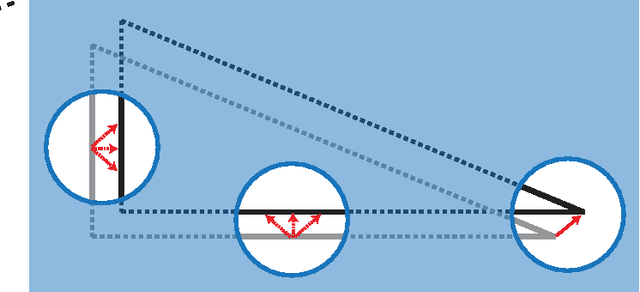
Visual motion estimation is a computationally intensive, but important task for sighted animals. Replicating the robustness and efficiency of biological visual motion estimation in artificial systems would significantly enhance the capabilities of future robotic agents. 25 years ago, in this very journal, Carver Mead outlined his argument for replicating biological processing in silicon circuits. His vision served as the foundation for the field of neuromorphic engineering, which has experienced a rapid growth in interest over recent years as the ideas and technologies mature. Replicating biological visual sensing was one of the first tasks attempted in the neuromorphic field. In this paper we focus specifically on the task of visual motion estimation. We describe the task itself, present the progression of works from the early first attempts through to the modern day state-of-the-art, and provide an outlook for future directions in the field.
* 16 pages, 11 figures, 1 table
HFirst: A Temporal Approach to Object Recognition
Aug 05, 2015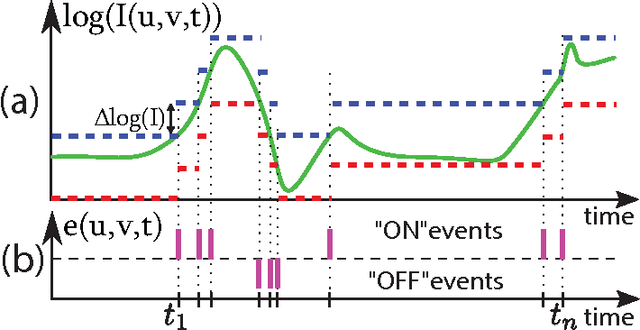
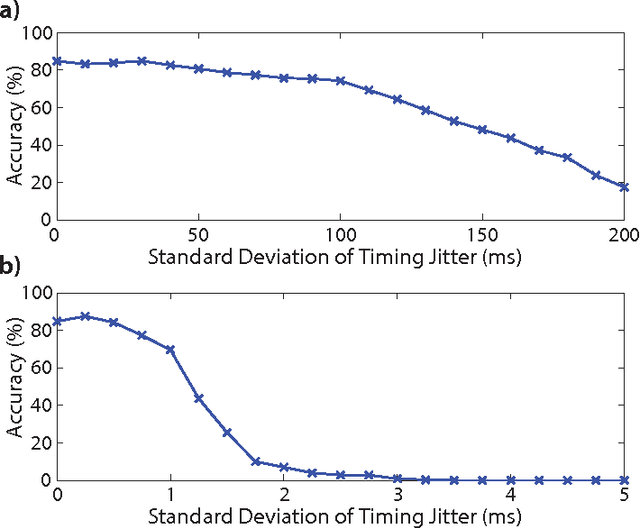
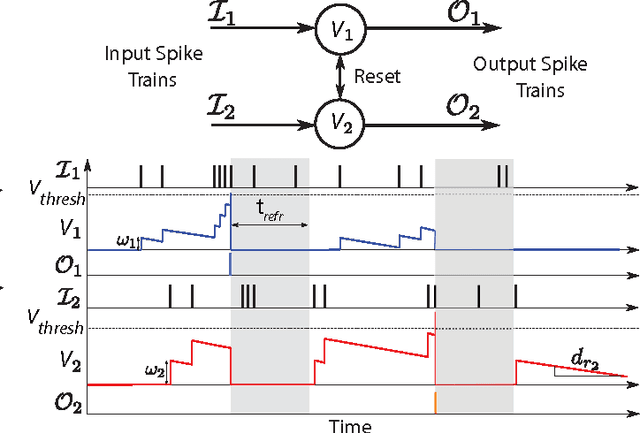
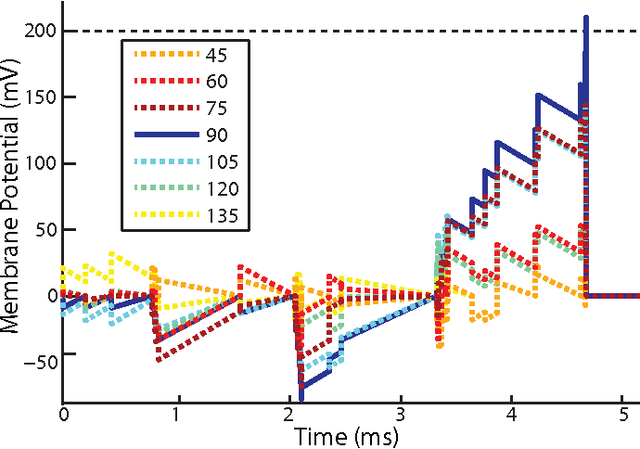
This paper introduces a spiking hierarchical model for object recognition which utilizes the precise timing information inherently present in the output of biologically inspired asynchronous Address Event Representation (AER) vision sensors. The asynchronous nature of these systems frees computation and communication from the rigid predetermined timing enforced by system clocks in conventional systems. Freedom from rigid timing constraints opens the possibility of using true timing to our advantage in computation. We show not only how timing can be used in object recognition, but also how it can in fact simplify computation. Specifically, we rely on a simple temporal-winner-take-all rather than more computationally intensive synchronous operations typically used in biologically inspired neural networks for object recognition. This approach to visual computation represents a major paradigm shift from conventional clocked systems and can find application in other sensory modalities and computational tasks. We showcase effectiveness of the approach by achieving the highest reported accuracy to date (97.5\%$\pm$3.5\%) for a previously published four class card pip recognition task and an accuracy of 84.9\%$\pm$1.9\% for a new more difficult 36 class character recognition task.
* 13 pages, 10 figures