 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-Based Visual Stream Compression for Event Cameras
Mar 12, 2024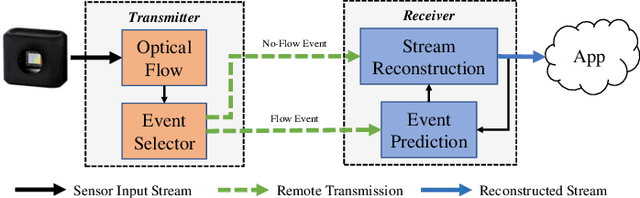

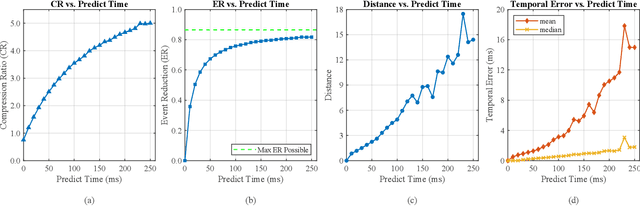
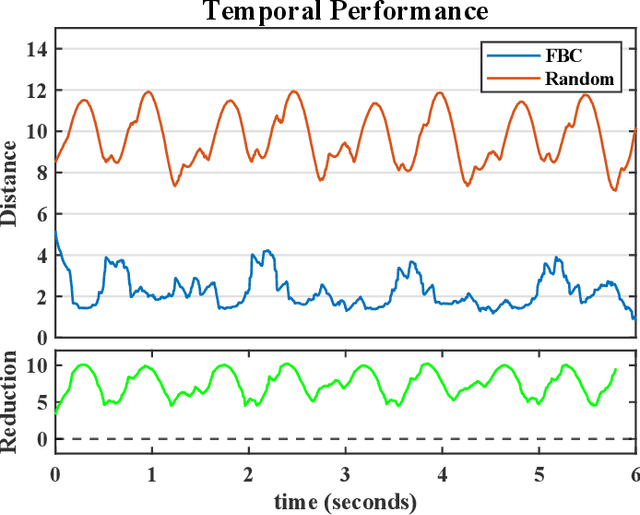
As the use of neuromorphic, event-based vision sensors expands, the need for compression of their output streams has increased. While their operational principle ensures event streams are spatially sparse, the high temporal resolution of the sensors can result in high data rates from the sensor depending on scene dynamics. For systems operating in communication-bandwidth-constrained and power-constrained environments, it is essential to compress these streams before transmitting them to a remote receiver. Therefore, we introduce a flow-based method for the real-time asynchronous compression of event streams as they are generated. This method leverages real-time optical flow estimates to predict future events without needing to transmit them, therefore, drastically reducing the amount of data transmitted. The flow-based compression introduced is evaluated using a variety of methods including spatiotemporal distance between event streams. The introduced method itself is shown to achieve an average compression ratio of 2.81 on a variety of event-camera datasets with the evaluation configuration used. That compression is achieved with a median temporal error of 0.48 ms and an average spatiotemporal event-stream distance of 3.07. When combined with LZMA compression for non-real-time applications, our method can achieve state-of-the-art average compression ratios ranging from 10.45 to 17.24. Additionally, we demonstrate that the proposed prediction algorithm is capable of performing real-time, low-latency event prediction.
An event-based implementation of saliency-based visual attention for rapid scene analysis
Jan 10, 2024Selective attention is an essential mechanism to filter sensory input and to select only its most important components, allowing the capacity-limited cognitive structures of the brain to process them in detail. The saliency map model, originally developed to understand the process of selective attention in the primate visual system, has also been extensively used in computer vision. Due to the wide-spread use of frame-based video, this is how dynamic input from non-stationary scenes is commonly implemented in saliency maps. However, the temporal structure of this input modality is very different from that of the primate visual system. Retinal input to the brain is massively parallel, local rather than frame-based, asynchronous rather than synchronous, and transmitted in the form of discrete events, neuronal action potentials (spikes). These features are captured by event-based cameras. We show that a computational saliency model can be obtained organically from such vision sensors, at minimal computational cost. We assess the performance of the model by comparing its predictions with the distribution of overt attention (fixations) of human observers, and we make available an event-based dataset that can be used as ground truth for future studies.
Event Based Time-Vectors for auditory features extraction: a neuromorphic approach for low power audio recognition
Dec 13, 2021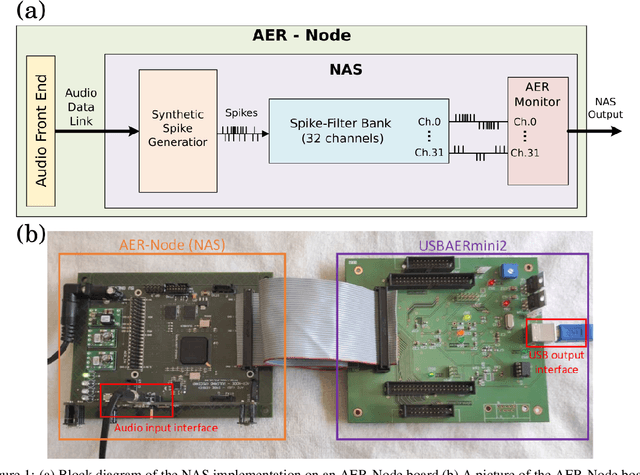
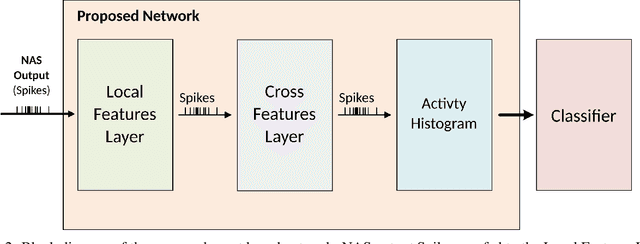
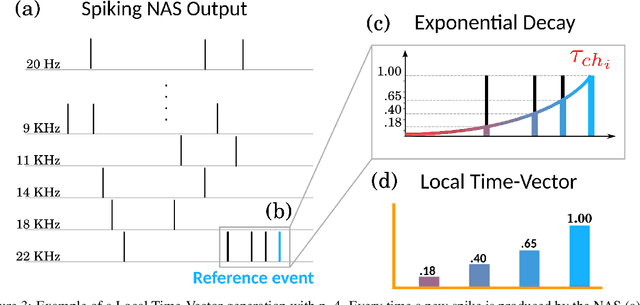
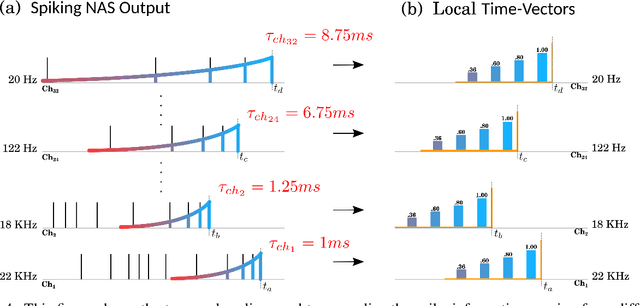
In recent years tremendous efforts have been done to advance the state of the art for Natural Language Processing (NLP) and audio recognition. However, these efforts often translated in increased power consumption and memory requirements for bigger and more complex models. These solutions falls short of the constraints of IoT devices which need low power, low memory efficient computation, and therefore they fail to meet the growing demand of efficient edge computing. Neuromorphic systems have proved to be excellent candidates for low-power low-latency computation in a multitude of applications. For this reason we present a neuromorphic architecture, capable of unsupervised auditory feature recognition. We then validate the network on a subset of Google's Speech Commands dataset.
Neutron-Induced, Single-Event Effects on Neuromorphic Event-based Vision Sensor: A First Step Towards Space Applications
Jan 29, 2021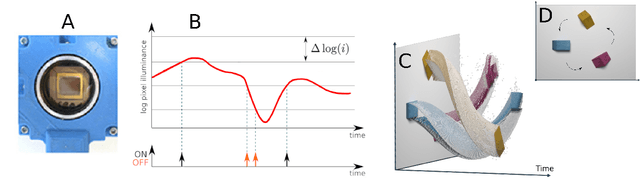

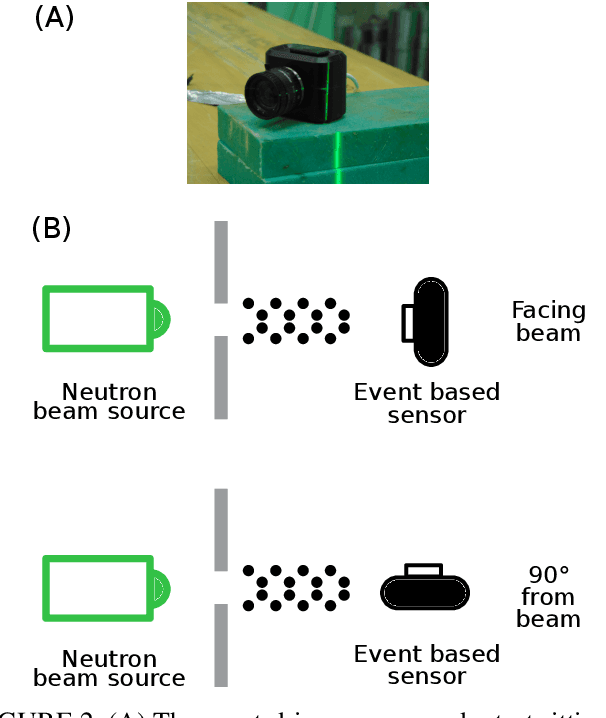
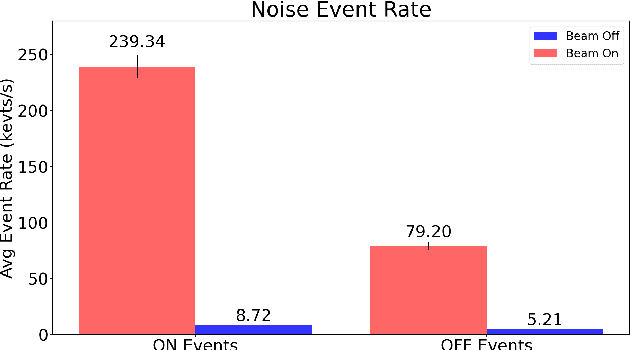
This paper studies the suitability of neuromorphic event-based vision cameras for spaceflight, and the effects of neutron radiation on their performance. Neuromorphic event-based vision cameras are novel sensors that implement asynchronous, clockless data acquisition, providing information about the change in illuminance greater than 120dB with sub-millisecond temporal precision. These sensors have huge potential for space applications as they provide an extremely sparse representation of visual dynamics while removing redundant information, thereby conforming to low-resource requirements. An event-based sensor was irradiated under wide-spectrum neutrons at Los Alamos Neutron Science Center and its effects were classified. We found that the sensor had very fast recovery during radiation, showing high correlation of noise event bursts with respect to source macro-pulses. No significant differences were observed between the number of events induced at different angles of incidence but significant differences were found in the spatial structure of noise events at different angles. The results show that event-based cameras are capable of functioning in a space-like, radiative environment with a signal-to-noise ratio of 3.355. They also show that radiation-induced noise does not affect event-level computation. We also introduce the Event-based Radiation-Induced Noise Simulation Environment (Event-RINSE), a simulation environment based on the noise-modelling we conducted and capable of injecting the effects of radiation-induced noise from the collected data to any stream of events in order to ensure that developed code can operate in a radiative environment. To the best of our knowledge, this is the first time such analysis of neutron-induced noise analysis has been performed on a neuromorphic vision sensor, and this study shows the advantage of using such sensors for space applications.
See before you see: Real-time high speed motion prediction using fast aperture-robust event-driven visual flow
Nov 27, 2018



Optical flow is a crucial component of the feature space for early visual processing of dynamic scenes especially in new applications such as self-driving vehicles, drones and autonomous robots. The dynamic vision sensors are well suited for such applications because of their asynchronous, sparse and temporally precise representation of the visual dynamics. Many algorithms proposed for computing visual flow for these sensors suffer from the aperture problem as the direction of the estimated flow is governed by the curvature of the object rather than the true motion direction. Some methods that do overcome this problem by temporal windowing under-utilize the true precise temporal nature of the dynamic sensors. In this paper, we propose a novel multi-scale plane fitting based visual flow algorithm that is robust to the aperture problem and also computationally fast and efficient. Our algorithm performs well in many scenarios ranging from fixed camera recording simple geometric shapes to real world scenarios such as camera mounted on a moving car and can successfully perform event-by-event motion estimation of objects in the scene to allow for predictions of upto 500 ms i.e. equivalent to 10 to 25 frames with traditional cameras.
Event-Based Features Selection and Tracking from Intertwined Estimation of Velocity and Generative Contours
Nov 19, 2018
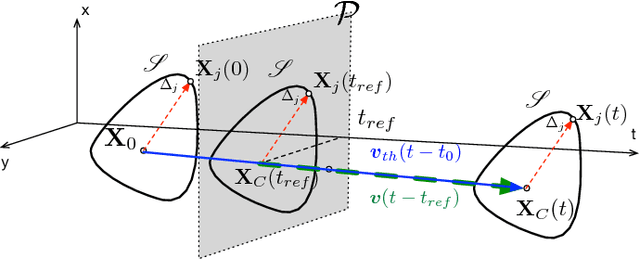
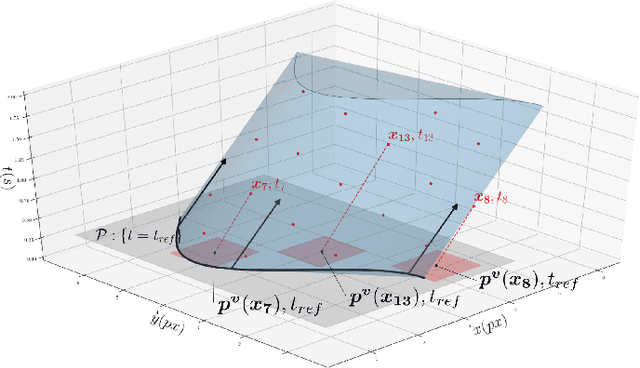
This paper presents a new event-based method for detecting and tracking features from the output of an event-based camera. Unlike many tracking algorithms from the computer vision community, this process does not aim for particular predefined shapes such as corners. It relies on a dual intertwined iterative continuous -- pure event-based -- estimation of the velocity vector and a bayesian description of the generative feature contours. By projecting along estimated speeds updated for each incoming event it is possible to identify and determine the spatial location and generative contour of the tracked feature while iteratively updating the estimation of the velocity vector. Results on several environments are shown taking into account large variations in terms of luminosity, speed, nature and size of the tracked features. The usage of speed instead of positions allows for a much faster feedback allowing for very fast convergence rates.
Event-based Gesture Recognition with Dynamic Background Suppression using Smartphone Computational Capabilities
Nov 19, 2018



This paper introduces a framework of gesture recognition operating on the output of an event based camera using the computational resources of a mobile phone. We will introduce a new development around the concept of time-surfaces modified and adapted to run on the limited computational resources of a mobile platform. We also introduce a new method to remove dynamically backgrounds that makes full use of the high temporal resolution of event-based cameras. We assess the performances of the framework by operating on several dynamic scenarios in uncontrolled lighting conditions indoors and outdoors. We also introduce a new publicly available event-based dataset for gesture recognition selected through a clinical process to allow human-machine interactions for the visually-impaired and the elderly. We finally report comparisons with prior works that tackled event-based gesture recognition reporting comparable if not superior results if taking into account the limited computational and memory constraints of the used hardware.
When Conventional machine learning meets neuromorphic engineering: Deep Temporal Networks (DTNets) a machine learning frawmework allowing to operate on Events and Frames and implantable on Tensor Flow Like Hardware
Nov 19, 2018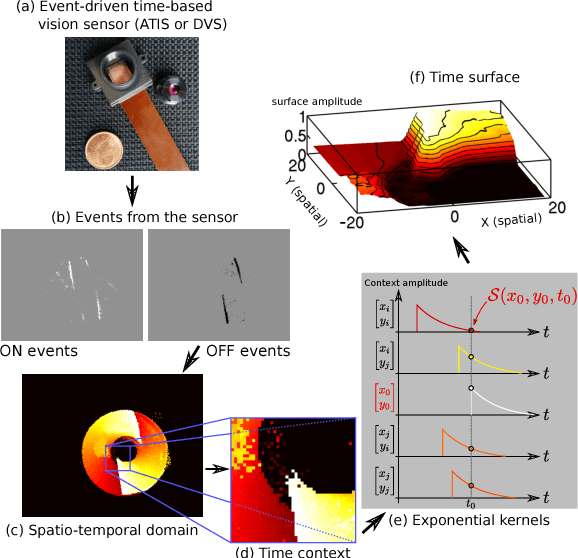
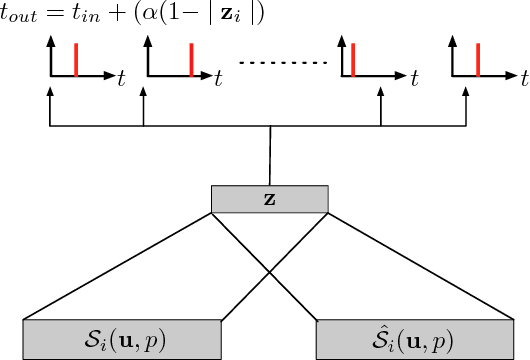
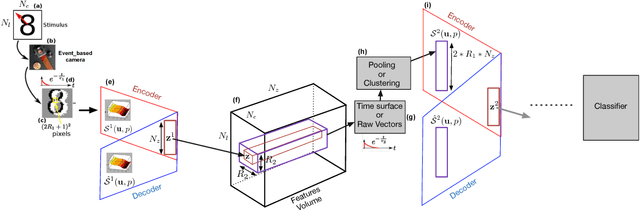
We introduce in this paper the principle of Deep Temporal Networks that allow to add time to convolutional networks by allowing deep integration principles not only using spatial information but also increasingly large temporal window. The concept can be used for conventional image inputs but also event based data. Although inspired by the architecture of brain that inegrates information over increasingly larger spatial but also temporal scales it can operate on conventional hardware using existing architectures. We introduce preliminary results to show the efficiency of the method. More in-depth results and analysis will be reported soon!
A Sparse Coding Multi-Scale Precise-Timing Machine Learning Algorithm for Neuromorphic Event-Based Sensors
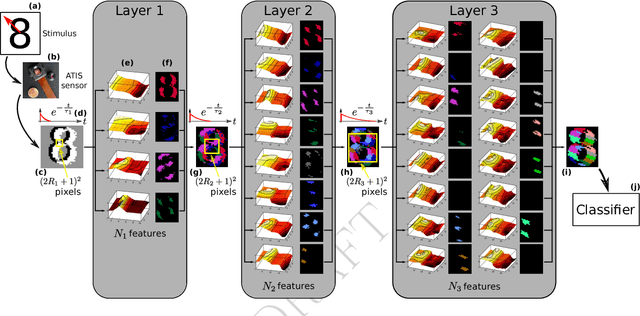
Apr 24, 2018This paper introduces an unsupervised compact architecture that can extract features and classify the contents of dynamic scenes from the temporal output of a neuromorphic asynchronous event-based camera. Event-based cameras are clock-less sensors where each pixel asynchronously reports intensity changes encoded in time at the microsecond precision. While this technology is gaining more attention, there is still a lack of methodology and understanding of their temporal properties. This paper introduces an unsupervised time-oriented event-based machine learning algorithm building on the concept of hierarchy of temporal descriptors called time surfaces. In this work we show that the use of sparse coding allows for a very compact yet efficient time-based machine learning that lowers both the computational cost and memory need. We show that we can represent visual scene temporal dynamics with a finite set of elementary time surfaces while providing similar recognition rates as an uncompressed version by storing the most representative time surfaces using clustering techniques. Experiments will illustrate the main optimizations and trade-offs to consider when implementing the method for online continuous vs. offline learning. We report results on the same previously published 36 class character recognition task and a 4 class canonical dynamic card pip task, achieving 100% accuracy on each.
Event-based Dynamic Face Detection and Tracking Based on Activity
Mar 27, 2018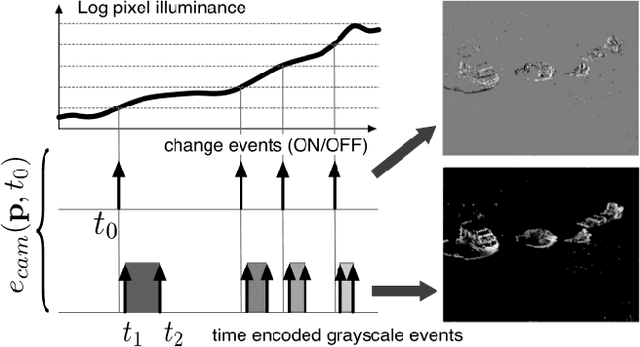
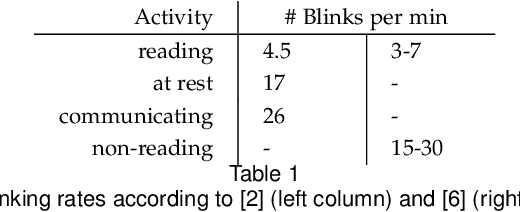
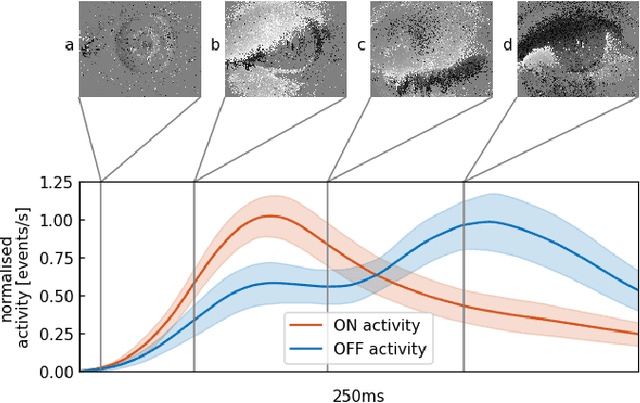
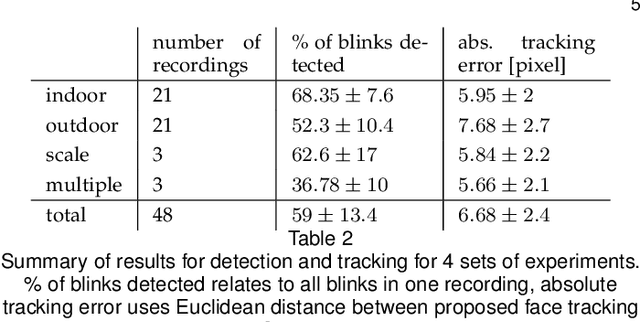
We present the first purely event-based approach for face detection using an ATIS, a neuromorphic camera. We look for pairs of blinking eyes by comparing local activity across the input frame to a predefined range, which is defined by the number of events per second in a specific location. If within range, the signal is checked for additional constraints such as duration, synchronicity and distance between the eyes. After a valid blink is registered, we await a second blink in the same spot to initiate Gaussian trackers above the eyes. Based on their position, a bounding box around the estimated outlines of the face is drawn. The face can then be tracked until it is occluded.