 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn event-based implementation of saliency-based visual attention for rapid scene analysis
Jan 10, 2024Selective attention is an essential mechanism to filter sensory input and to select only its most important components, allowing the capacity-limited cognitive structures of the brain to process them in detail. The saliency map model, originally developed to understand the process of selective attention in the primate visual system, has also been extensively used in computer vision. Due to the wide-spread use of frame-based video, this is how dynamic input from non-stationary scenes is commonly implemented in saliency maps. However, the temporal structure of this input modality is very different from that of the primate visual system. Retinal input to the brain is massively parallel, local rather than frame-based, asynchronous rather than synchronous, and transmitted in the form of discrete events, neuronal action potentials (spikes). These features are captured by event-based cameras. We show that a computational saliency model can be obtained organically from such vision sensors, at minimal computational cost. We assess the performance of the model by comparing its predictions with the distribution of overt attention (fixations) of human observers, and we make available an event-based dataset that can be used as ground truth for future studies.
A Framework for Event-based Computer Vision on a Mobile Device
May 13, 2022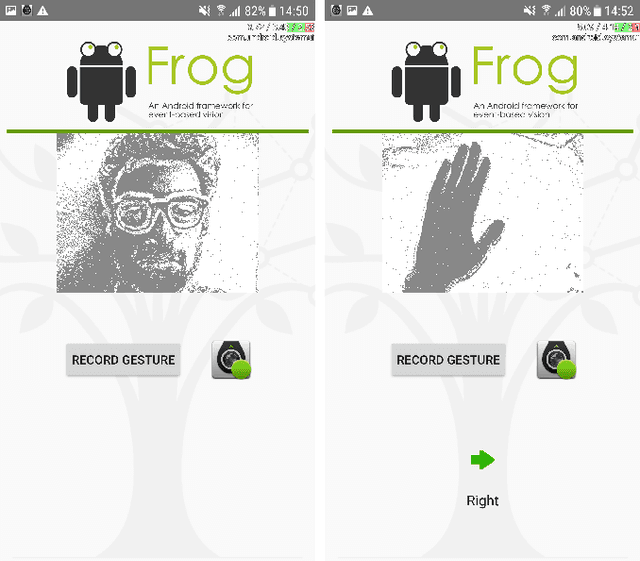
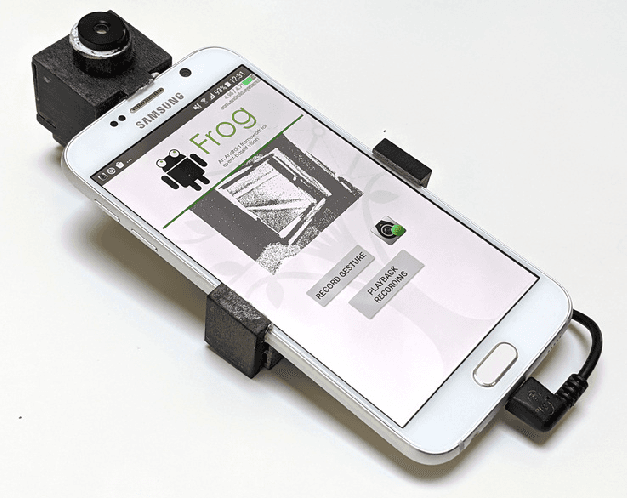
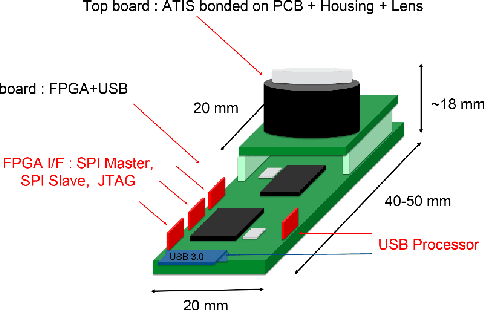
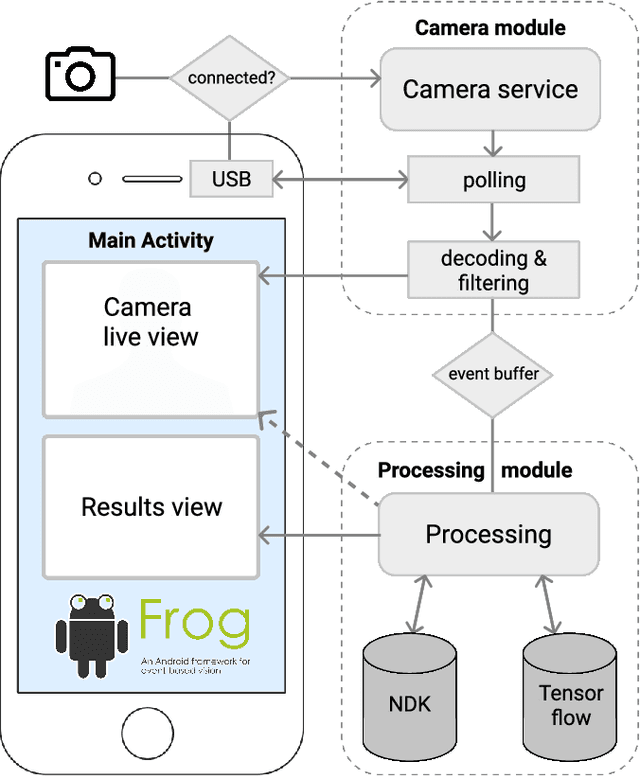
We present the first publicly available Android framework to stream data from an event camera directly to a mobile phone. Today's mobile devices handle a wider range of workloads than ever before and they incorporate a growing gamut of sensors that make devices smarter, more user friendly and secure. Conventional cameras in particular play a central role in such tasks, but they cannot record continuously, as the amount of redundant information recorded is costly to process. Bio-inspired event cameras on the other hand only record changes in a visual scene and have shown promising low-power applications that specifically suit mobile tasks such as face detection, gesture recognition or gaze tracking. Our prototype device is the first step towards embedding such an event camera into a battery-powered handheld device. The mobile framework allows us to stream events in real-time and opens up the possibilities for always-on and on-demand sensing on mobile phones. To liaise the asynchronous event camera output with synchronous von Neumann hardware, we look at how buffering events and processing them in batches can benefit mobile applications. We evaluate our framework in terms of latency and throughput and show examples of computer vision tasks that involve both event-by-event and pre-trained neural network methods for gesture recognition, aperture robust optical flow and grey-level image reconstruction from events. The code is available at https://github.com/neuromorphic-paris/frog
Event-Based Features Selection and Tracking from Intertwined Estimation of Velocity and Generative Contours
Nov 19, 2018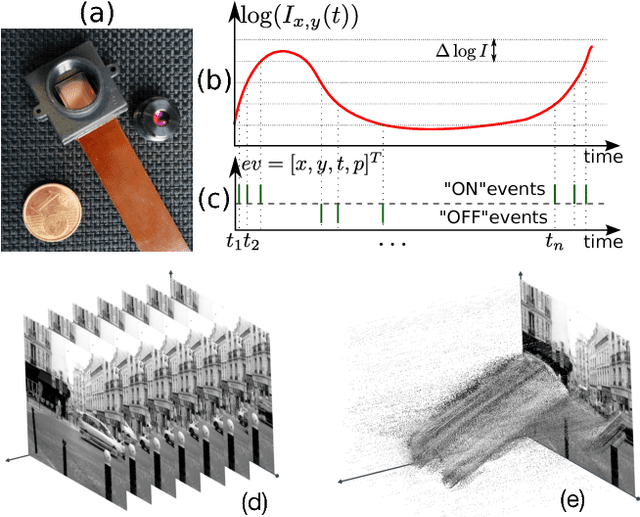
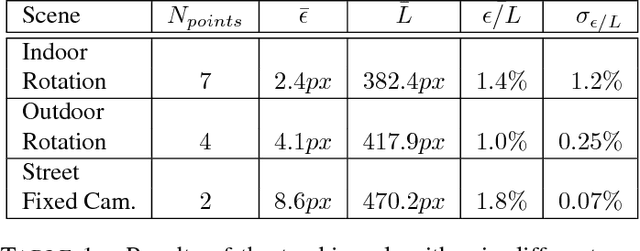
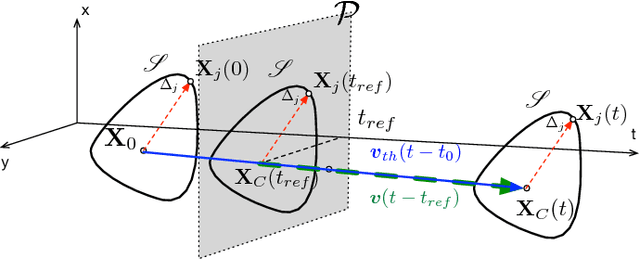
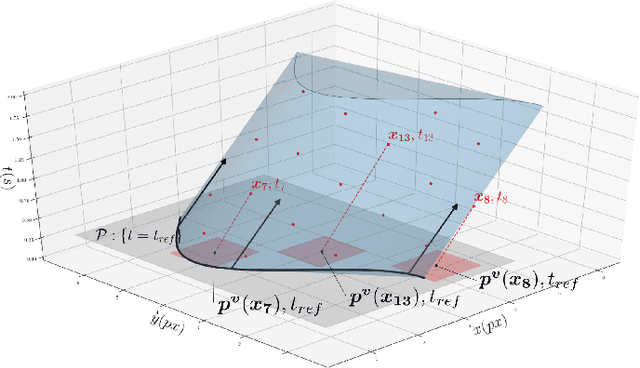
This paper presents a new event-based method for detecting and tracking features from the output of an event-based camera. Unlike many tracking algorithms from the computer vision community, this process does not aim for particular predefined shapes such as corners. It relies on a dual intertwined iterative continuous -- pure event-based -- estimation of the velocity vector and a bayesian description of the generative feature contours. By projecting along estimated speeds updated for each incoming event it is possible to identify and determine the spatial location and generative contour of the tracked feature while iteratively updating the estimation of the velocity vector. Results on several environments are shown taking into account large variations in terms of luminosity, speed, nature and size of the tracked features. The usage of speed instead of positions allows for a much faster feedback allowing for very fast convergence rates.
When Conventional machine learning meets neuromorphic engineering: Deep Temporal Networks (DTNets) a machine learning frawmework allowing to operate on Events and Frames and implantable on Tensor Flow Like Hardware
Nov 19, 2018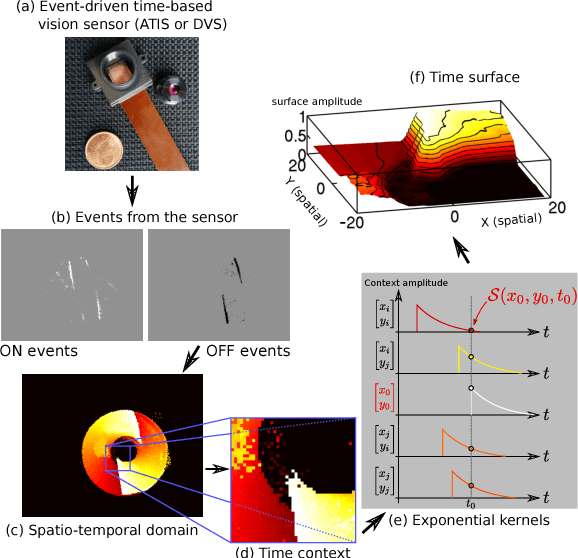
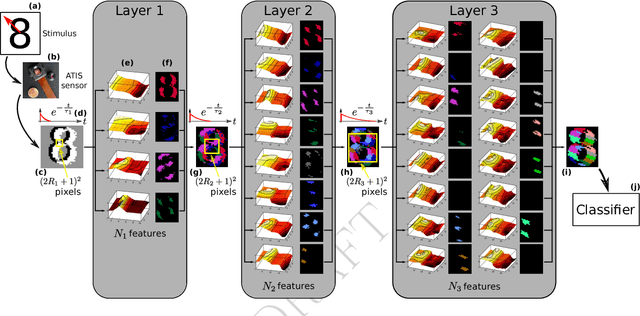
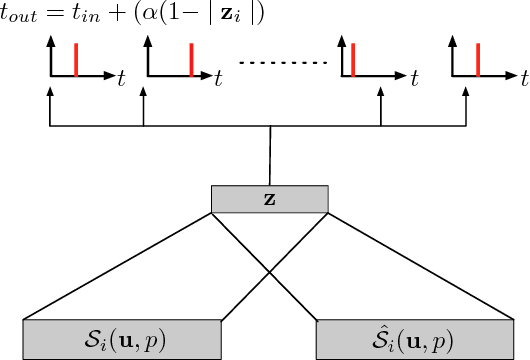
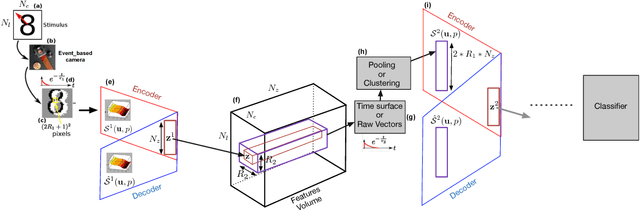
We introduce in this paper the principle of Deep Temporal Networks that allow to add time to convolutional networks by allowing deep integration principles not only using spatial information but also increasingly large temporal window. The concept can be used for conventional image inputs but also event based data. Although inspired by the architecture of brain that inegrates information over increasingly larger spatial but also temporal scales it can operate on conventional hardware using existing architectures. We introduce preliminary results to show the efficiency of the method. More in-depth results and analysis will be reported soon!
Event-based Dynamic Face Detection and Tracking Based on Activity
Mar 27, 2018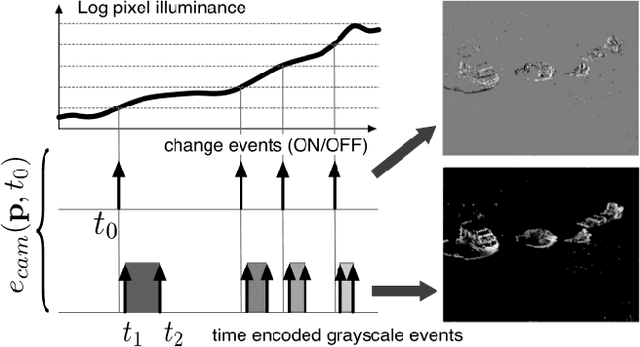
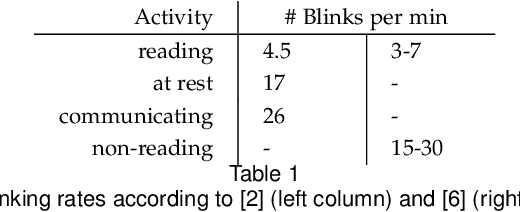
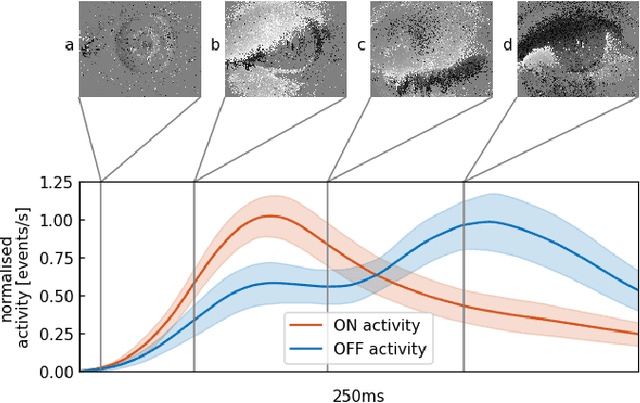
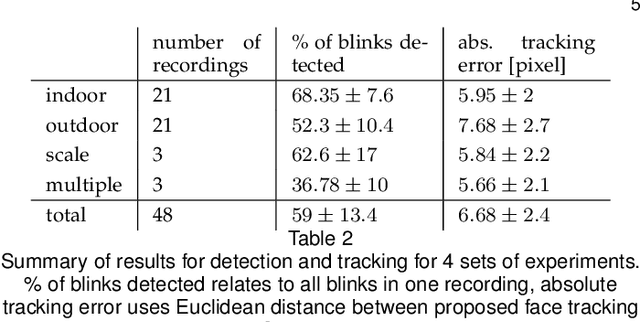
We present the first purely event-based approach for face detection using an ATIS, a neuromorphic camera. We look for pairs of blinking eyes by comparing local activity across the input frame to a predefined range, which is defined by the number of events per second in a specific location. If within range, the signal is checked for additional constraints such as duration, synchronicity and distance between the eyes. After a valid blink is registered, we await a second blink in the same spot to initiate Gaussian trackers above the eyes. Based on their position, a bounding box around the estimated outlines of the face is drawn. The face can then be tracked until it is occluded.