 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProspective Learning: Back to the Future
Jan 19, 2022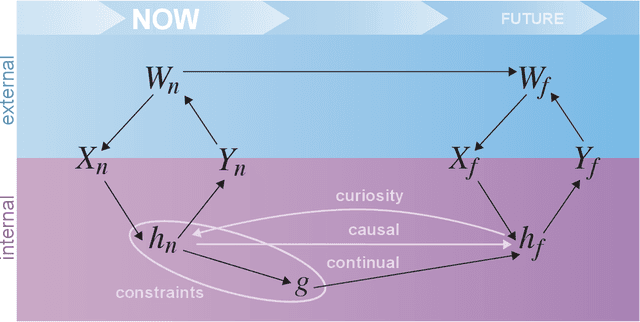

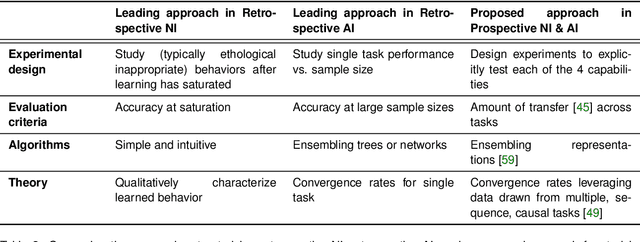
Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
A critical reappraisal of predicting suicidal ideation using fMRI
Mar 10, 2021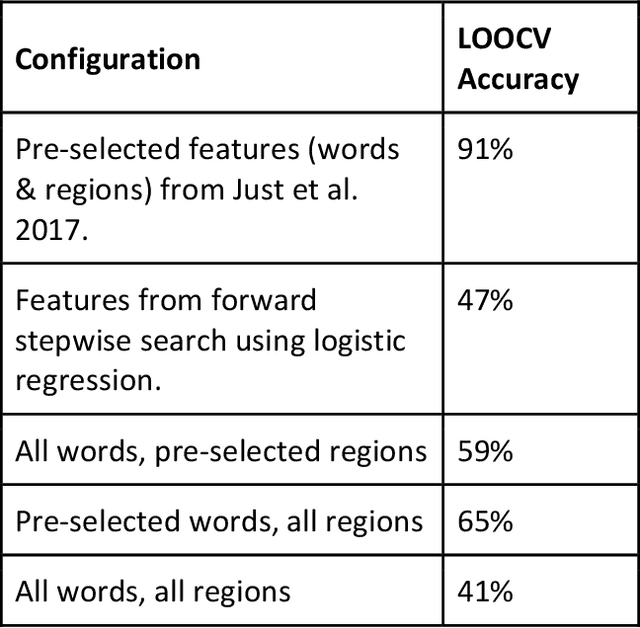
For many psychiatric disorders, neuroimaging offers a potential for revolutionizing diagnosis and treatment by providing access to preverbal mental processes. In their study "Machine learning of neural representations of suicide and emotion concepts identifies suicidal youth."1, Just and colleagues report that a Naive Bayes classifier, trained on voxelwise fMRI responses in human participants during the presentation of words and concepts related to mortality, can predict whether an individual had reported having suicidal ideations with a classification accuracy of 91%. Here we report a reappraisal of the methods employed by the authors, including re-analysis of the same data set, that calls into question the accuracy of the authors findings.
Better Safe than Sorry: Evidence Accumulation Allows for Safe Reinforcement Learning
Sep 24, 2018
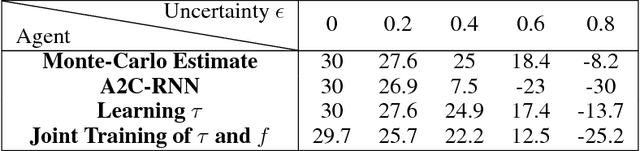
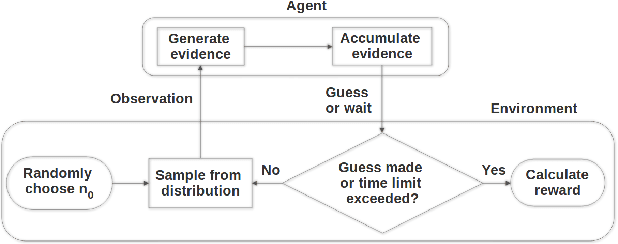
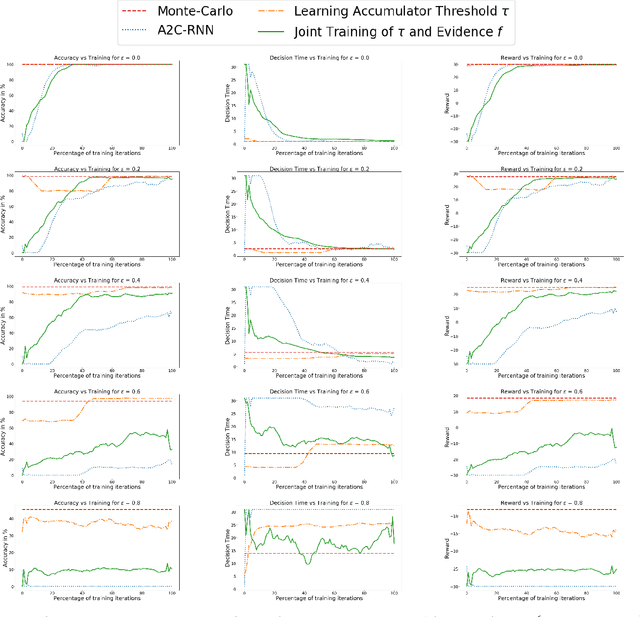
In the real world, agents often have to operate in situations with incomplete information, limited sensing capabilities, and inherently stochastic environments, making individual observations incomplete and unreliable. Moreover, in many situations it is preferable to delay a decision rather than run the risk of making a bad decision. In such situations it is necessary to aggregate information before taking an action; however, most state of the art reinforcement learning (RL) algorithms are biased towards taking actions \textit{at every time step}, even if the agent is not particularly confident in its chosen action. This lack of caution can lead the agent to make critical mistakes, regardless of prior experience and acclimation to the environment. Motivated by theories of dynamic resolution of uncertainty during decision making in biological brains, we propose a simple accumulator module which accumulates evidence in favor of each possible decision, encodes uncertainty as a dynamic competition between actions, and acts on the environment only when it is sufficiently confident in the chosen action. The agent makes no decision by default, and the burden of proof to make a decision falls on the policy to accrue evidence strongly in favor of a single decision. Our results show that this accumulator module achieves near-optimal performance on a simple guessing game, far outperforming deep recurrent networks using traditional, forced action selection policies.
Local White Matter Architecture Defines Functional Brain Dynamics
Sep 16, 2018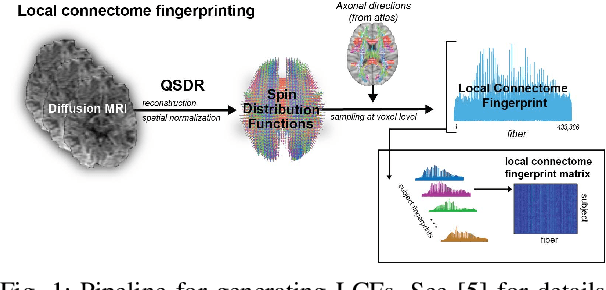
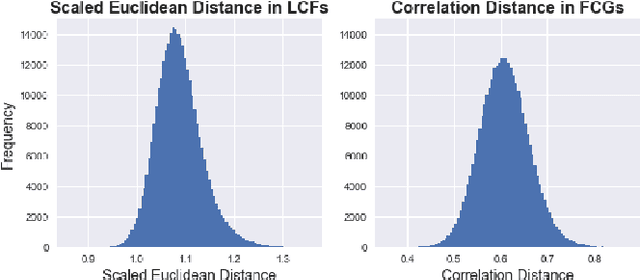
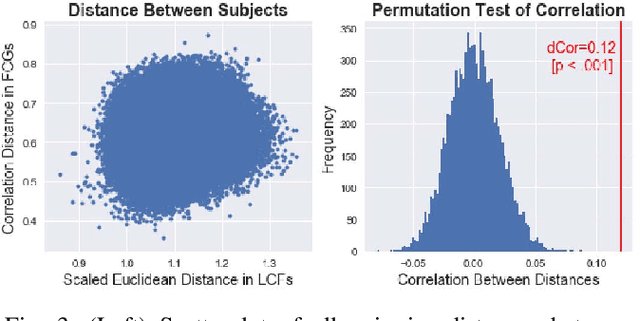
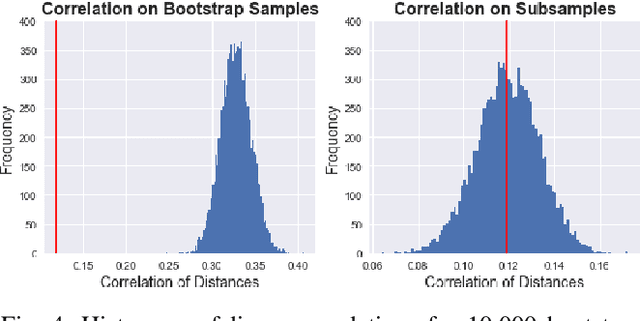
Large bundles of myelinated axons, called white matter, anatomically connect disparate brain regions together and compose the structural core of the human connectome. We recently proposed a method of measuring the local integrity along the length of each white matter fascicle, termed the local connectome. If communication efficiency is fundamentally constrained by the integrity along the entire length of a white matter bundle, then variability in the functional dynamics of brain networks should be associated with variability in the local connectome. We test this prediction using two statistical approaches that are capable of handling the high dimensionality of data. First, by performing statistical inference on distance-based correlations, we show that similarity in the local connectome between individuals is significantly correlated with similarity in their patterns of functional connectivity. Second, by employing variable selection using sparse canonical correlation analysis and cross-validation, we show that segments of the local connectome are predictive of certain patterns of functional brain dynamics. These results are consistent with the hypothesis that structural variability along axon bundles constrains communication between disparate brain regions.
Keep it stupid simple
Sep 10, 2018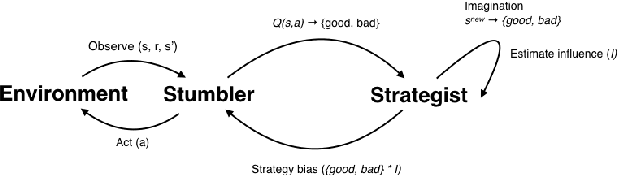

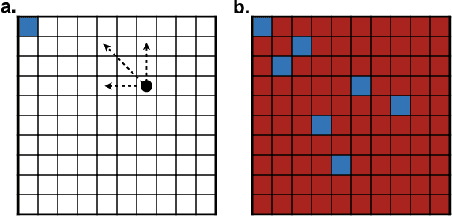
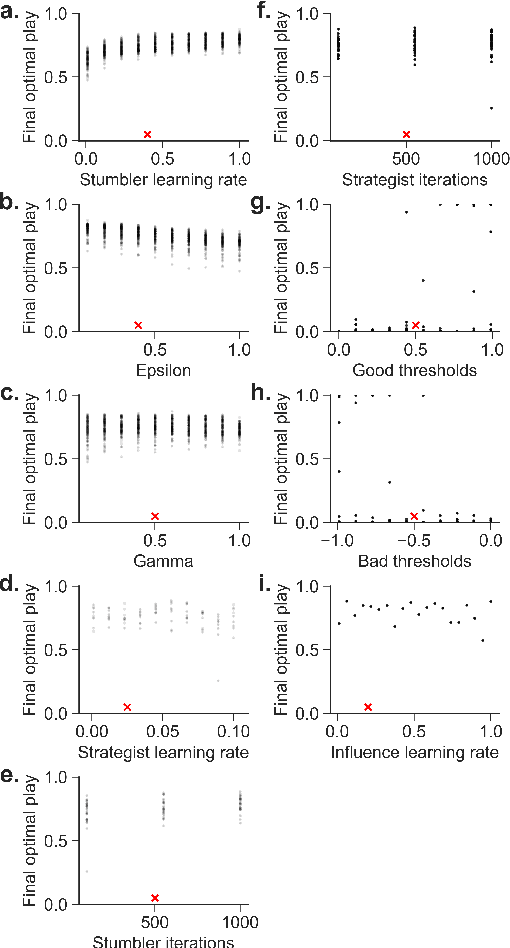
Deep reinforcement learning can match and exceed human performance, but if even minor changes are introduced to the environment artificial networks often can't adapt. Humans meanwhile are quite adaptable. We hypothesize that this is partly because of how humans use heuristics, and partly because humans can imagine new and more challenging environments to learn from. We've developed a model of hierarchical reinforcement learning that combines both these elements into a stumbler-strategist network. We test transfer performance of this network using Wythoff's game, a gridworld environment with a known optimal strategy. We show that combining imagined play with a heuristic--labeling each position as "good" or "bad"'--both accelerates learning and promotes transfer to novel games, while also improving model interpretability.
Learning model-based strategies in simple environments with hierarchical q-networks
Jan 20, 2018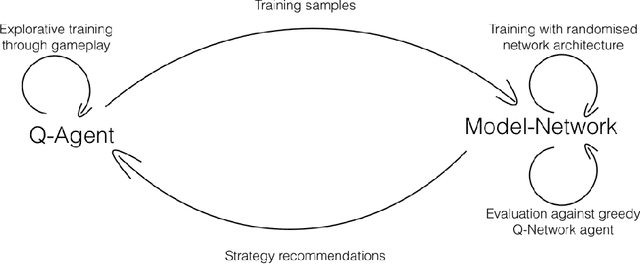
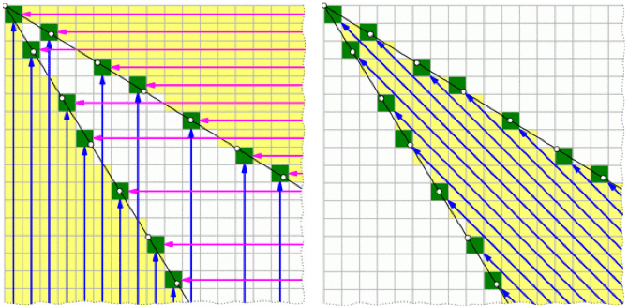


Recent advances in deep learning have allowed artificial agents to rival human-level performance on a wide range of complex tasks; however, the ability of these networks to learn generalizable strategies remains a pressing challenge. This critical limitation is due in part to two factors: the opaque information representation in deep neural networks and the complexity of the task environments in which they are typically deployed. Here we propose a novel Hierarchical Q-Network (HQN) motivated by theories of the hierarchical organization of the human prefrontal cortex, that attempts to identify lower dimensional patterns in the value landscape that can be exploited to construct an internal model of rules in simple environments. We draw on combinatorial games, where there exists a single optimal strategy for winning that generalizes across other features of the game, to probe the strategy generalization of the HQN and other reinforcement learning (RL) agents using variations of Wythoff's game. Traditional RL approaches failed to reach satisfactory performance on variants of Wythoff's Game; however, the HQN learned heuristic-like strategies that generalized across changes in board configuration. More importantly, the HQN allowed for transparent inspection of the agent's internal model of the game following training. Our results show how a biologically inspired hierarchical learner can facilitate learning abstract rules to promote robust and flexible action policies in simplified training environments with clearly delineated optimal strategies.
FuSSO: Functional Shrinkage and Selection Operator
Mar 09, 2014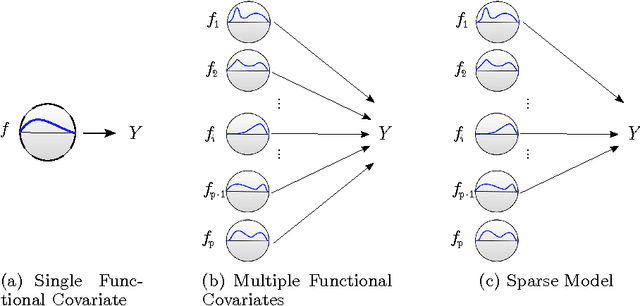
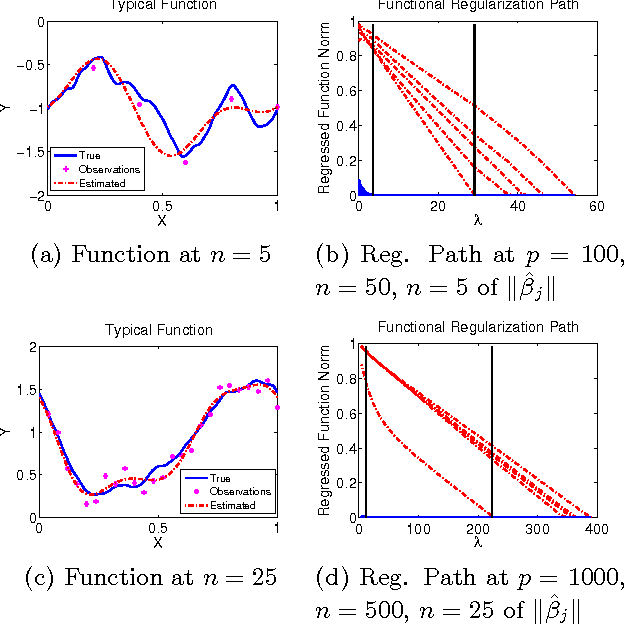
We present the FuSSO, a functional analogue to the LASSO, that efficiently finds a sparse set of functional input covariates to regress a real-valued response against. The FuSSO does so in a semi-parametric fashion, making no parametric assumptions about the nature of input functional covariates and assuming a linear form to the mapping of functional covariates to the response. We provide a statistical backing for use of the FuSSO via proof of asymptotic sparsistency under various conditions. Furthermore, we observe good results on both synthetic and real-world data.
DeBaCl: A Python Package for Interactive DEnsity-BAsed CLustering
Jul 30, 2013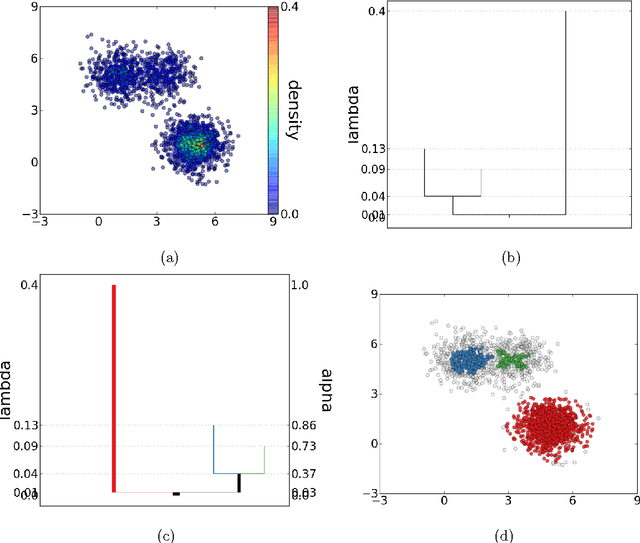
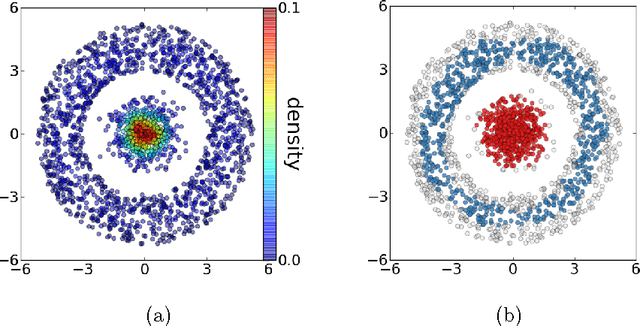
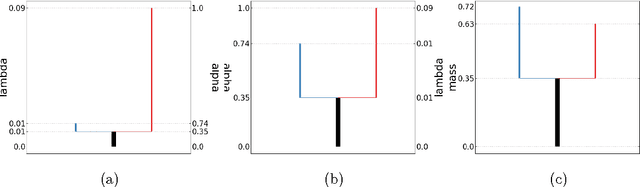
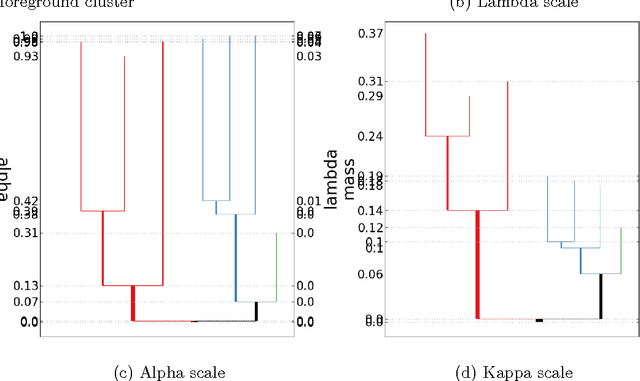
The level set tree approach of Hartigan (1975) provides a probabilistically based and highly interpretable encoding of the clustering behavior of a dataset. By representing the hierarchy of data modes as a dendrogram of the level sets of a density estimator, this approach offers many advantages for exploratory analysis and clustering, especially for complex and high-dimensional data. Several R packages exist for level set tree estimation, but their practical usefulness is limited by computational inefficiency, absence of interactive graphical capabilities and, from a theoretical perspective, reliance on asymptotic approximations. To make it easier for practitioners to capture the advantages of level set trees, we have written the Python package DeBaCl for DEnsity-BAsed CLustering. In this article we illustrate how DeBaCl's level set tree estimates can be used for difficult clustering tasks and interactive graphical data analysis. The package is intended to promote the practical use of level set trees through improvements in computational efficiency and a high degree of user customization. In addition, the flexible algorithms implemented in DeBaCl enjoy finite sample accuracy, as demonstrated in recent literature on density clustering. Finally, we show the level set tree framework can be easily extended to deal with functional data.