 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Safe than Sorry: Evidence Accumulation Allows for Safe Reinforcement Learning
Sep 24, 2018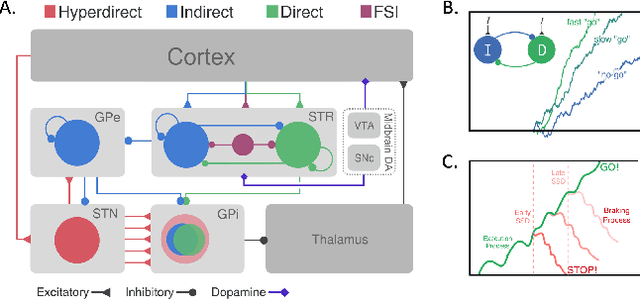
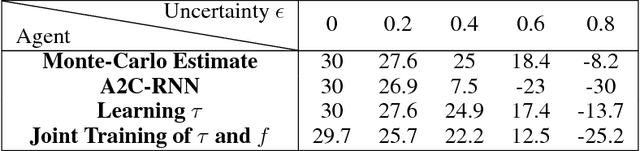
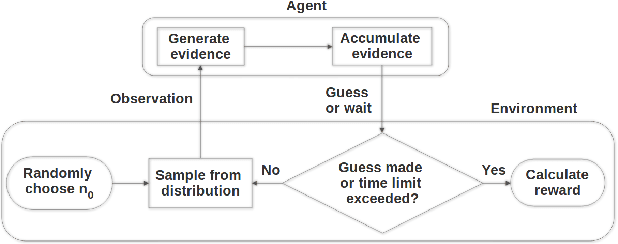
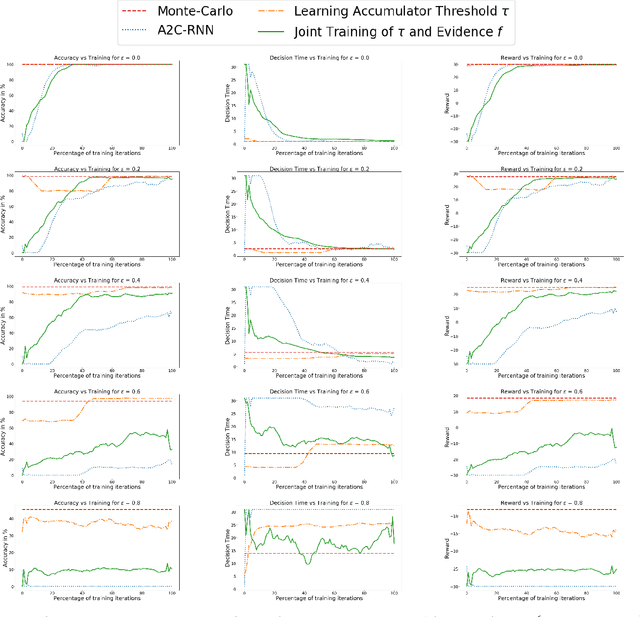
In the real world, agents often have to operate in situations with incomplete information, limited sensing capabilities, and inherently stochastic environments, making individual observations incomplete and unreliable. Moreover, in many situations it is preferable to delay a decision rather than run the risk of making a bad decision. In such situations it is necessary to aggregate information before taking an action; however, most state of the art reinforcement learning (RL) algorithms are biased towards taking actions \textit{at every time step}, even if the agent is not particularly confident in its chosen action. This lack of caution can lead the agent to make critical mistakes, regardless of prior experience and acclimation to the environment. Motivated by theories of dynamic resolution of uncertainty during decision making in biological brains, we propose a simple accumulator module which accumulates evidence in favor of each possible decision, encodes uncertainty as a dynamic competition between actions, and acts on the environment only when it is sufficiently confident in the chosen action. The agent makes no decision by default, and the burden of proof to make a decision falls on the policy to accrue evidence strongly in favor of a single decision. Our results show that this accumulator module achieves near-optimal performance on a simple guessing game, far outperforming deep recurrent networks using traditional, forced action selection policies.
Keep it stupid simple
Sep 10, 2018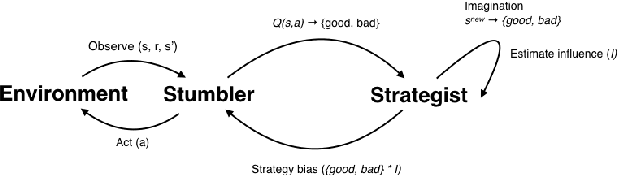

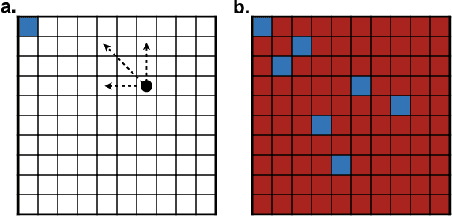
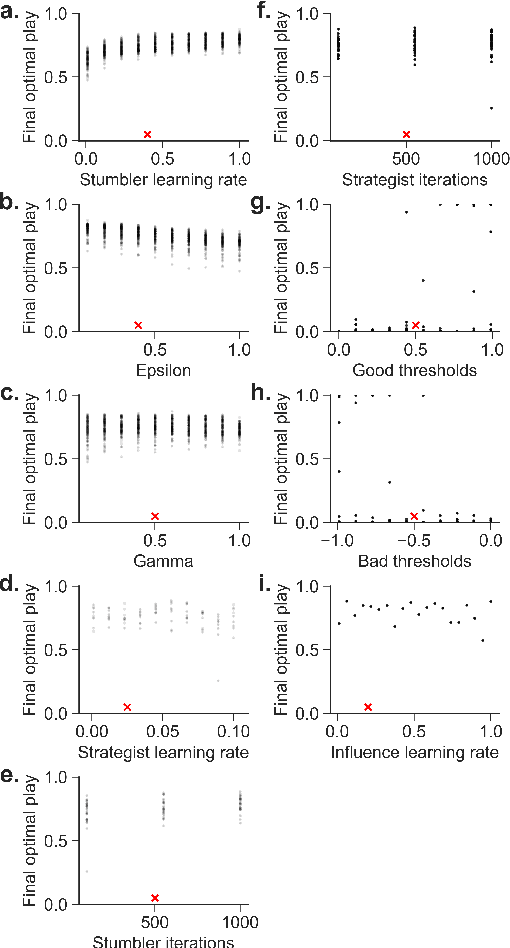
Deep reinforcement learning can match and exceed human performance, but if even minor changes are introduced to the environment artificial networks often can't adapt. Humans meanwhile are quite adaptable. We hypothesize that this is partly because of how humans use heuristics, and partly because humans can imagine new and more challenging environments to learn from. We've developed a model of hierarchical reinforcement learning that combines both these elements into a stumbler-strategist network. We test transfer performance of this network using Wythoff's game, a gridworld environment with a known optimal strategy. We show that combining imagined play with a heuristic--labeling each position as "good" or "bad"'--both accelerates learning and promotes transfer to novel games, while also improving model interpretability.
Learning model-based strategies in simple environments with hierarchical q-networks
Jan 20, 2018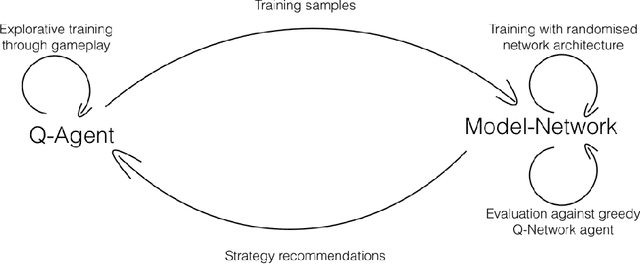
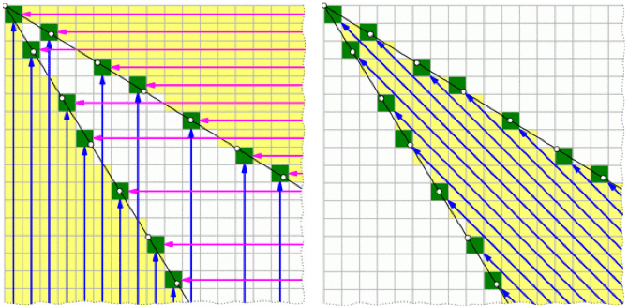


Recent advances in deep learning have allowed artificial agents to rival human-level performance on a wide range of complex tasks; however, the ability of these networks to learn generalizable strategies remains a pressing challenge. This critical limitation is due in part to two factors: the opaque information representation in deep neural networks and the complexity of the task environments in which they are typically deployed. Here we propose a novel Hierarchical Q-Network (HQN) motivated by theories of the hierarchical organization of the human prefrontal cortex, that attempts to identify lower dimensional patterns in the value landscape that can be exploited to construct an internal model of rules in simple environments. We draw on combinatorial games, where there exists a single optimal strategy for winning that generalizes across other features of the game, to probe the strategy generalization of the HQN and other reinforcement learning (RL) agents using variations of Wythoff's game. Traditional RL approaches failed to reach satisfactory performance on variants of Wythoff's Game; however, the HQN learned heuristic-like strategies that generalized across changes in board configuration. More importantly, the HQN allowed for transparent inspection of the agent's internal model of the game following training. Our results show how a biologically inspired hierarchical learner can facilitate learning abstract rules to promote robust and flexible action policies in simplified training environments with clearly delineated optimal strategies.