 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Computing for Materials Acceleration Platforms
Aug 17, 2022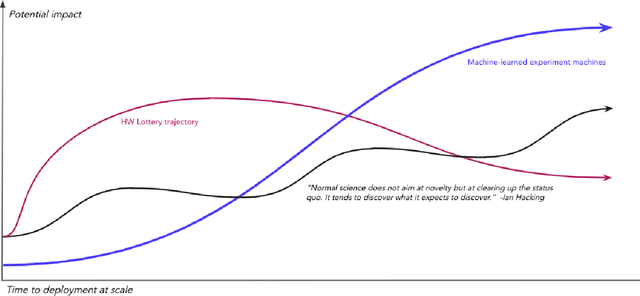
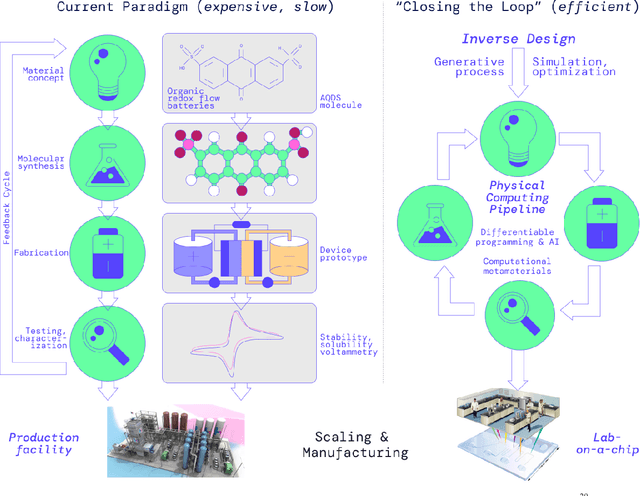
A ''technology lottery'' describes a research idea or technology succeeding over others because it is suited to the available software and hardware, not necessarily because it is superior to alternative directions--examples abound, from the synergies of deep learning and GPUs to the disconnect of urban design and autonomous vehicles. The nascent field of Self-Driving Laboratories (SDL), particularly those implemented as Materials Acceleration Platforms (MAPs), is at risk of an analogous pitfall: the next logical step for building MAPs is to take existing lab equipment and workflows and mix in some AI and automation. In this whitepaper, we argue that the same simulation and AI tools that will accelerate the search for new materials, as part of the MAPs research program, also make possible the design of fundamentally new computing mediums. We need not be constrained by existing biases in science, mechatronics, and general-purpose computing, but rather we can pursue new vectors of engineering physics with advances in cyber-physical learning and closed-loop, self-optimizing systems. Here we outline a simulation-based MAP program to design computers that use physics itself to solve optimization problems. Such systems mitigate the hardware-software-substrate-user information losses present in every other class of MAPs and they perfect alignment between computing problems and computing mediums eliminating any technology lottery. We offer concrete steps toward early ''Physical Computing (PC) -MAP'' advances and the longer term cyber-physical R&D which we expect to introduce a new era of innovative collaboration between materials researchers and computer scientists.
Simulation Intelligence: Towards a New Generation of Scientific Methods
Dec 06, 2021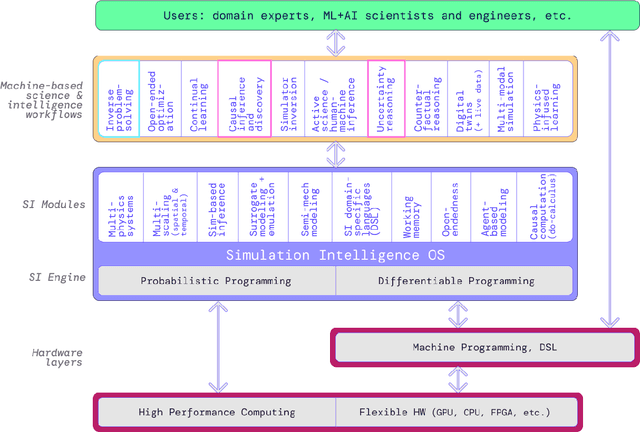
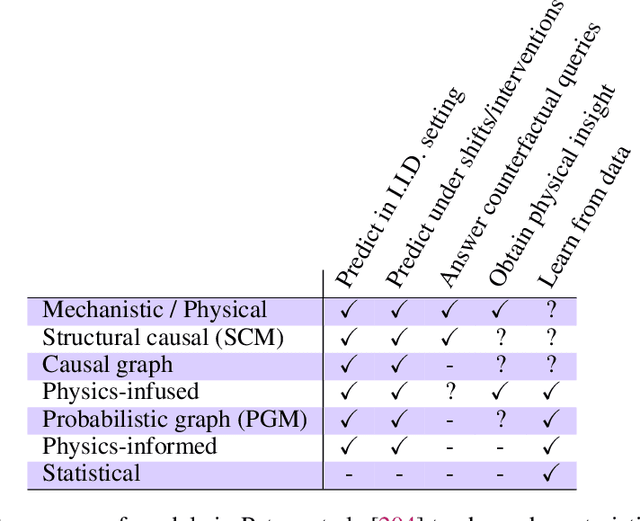
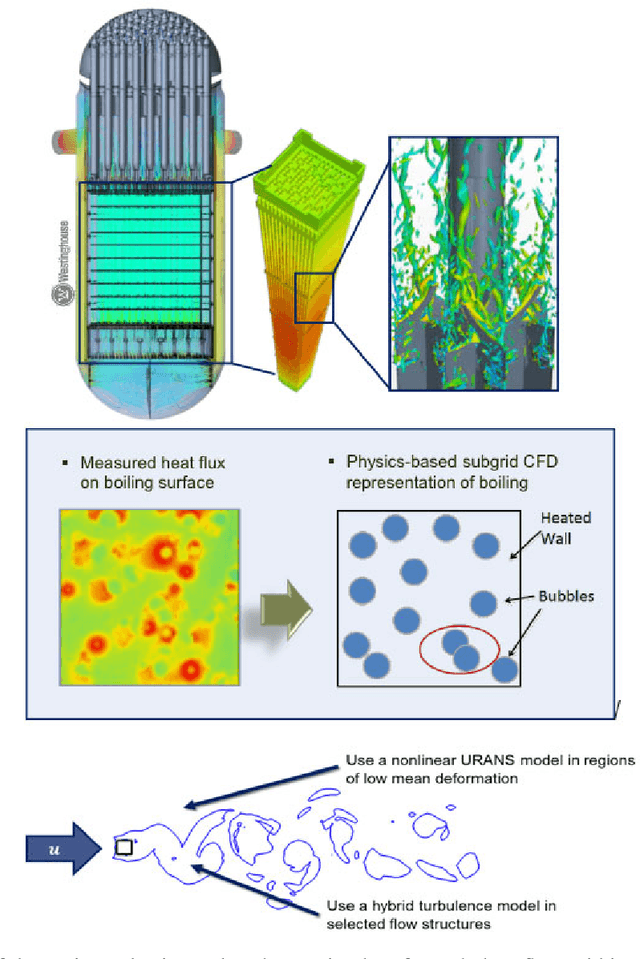
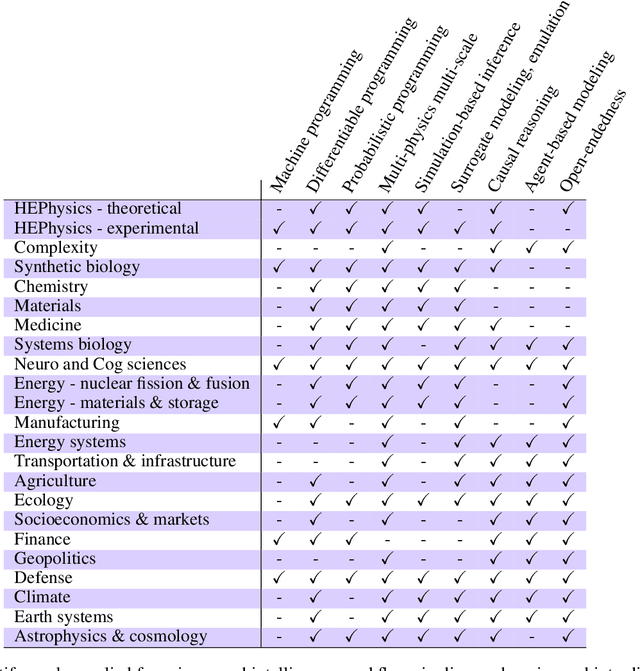
The original "Seven Motifs" set forth a roadmap of essential methods for the field of scientific computing, where a motif is an algorithmic method that captures a pattern of computation and data movement. We present the "Nine Motifs of Simulation Intelligence", a roadmap for the development and integration of the essential algorithms necessary for a merger of scientific computing, scientific simulation, and artificial intelligence. We call this merger simulation intelligence (SI), for short. We argue the motifs of simulation intelligence are interconnected and interdependent, much like the components within the layers of an operating system. Using this metaphor, we explore the nature of each layer of the simulation intelligence operating system stack (SI-stack) and the motifs therein: (1) Multi-physics and multi-scale modeling; (2) Surrogate modeling and emulation; (3) Simulation-based inference; (4) Causal modeling and inference; (5) Agent-based modeling; (6) Probabilistic programming; (7) Differentiable programming; (8) Open-ended optimization; (9) Machine programming. We believe coordinated efforts between motifs offers immense opportunity to accelerate scientific discovery, from solving inverse problems in synthetic biology and climate science, to directing nuclear energy experiments and predicting emergent behavior in socioeconomic settings. We elaborate on each layer of the SI-stack, detailing the state-of-art methods, presenting examples to highlight challenges and opportunities, and advocating for specific ways to advance the motifs and the synergies from their combinations. Advancing and integrating these technologies can enable a robust and efficient hypothesis-simulation-analysis type of scientific method, which we introduce with several use-cases for human-machine teaming and automated science.
Better Safe than Sorry: Evidence Accumulation Allows for Safe Reinforcement Learning
Sep 24, 2018
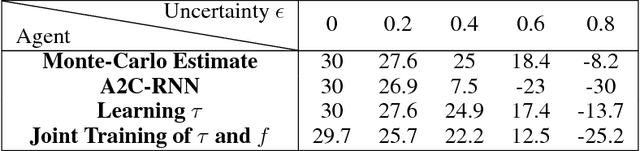
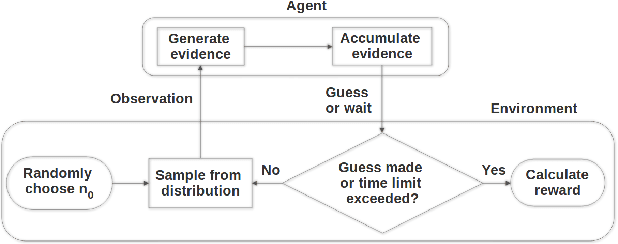
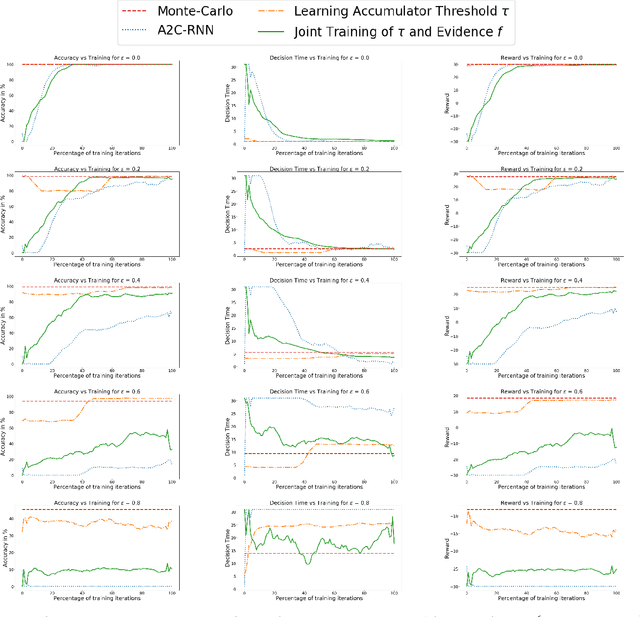
In the real world, agents often have to operate in situations with incomplete information, limited sensing capabilities, and inherently stochastic environments, making individual observations incomplete and unreliable. Moreover, in many situations it is preferable to delay a decision rather than run the risk of making a bad decision. In such situations it is necessary to aggregate information before taking an action; however, most state of the art reinforcement learning (RL) algorithms are biased towards taking actions \textit{at every time step}, even if the agent is not particularly confident in its chosen action. This lack of caution can lead the agent to make critical mistakes, regardless of prior experience and acclimation to the environment. Motivated by theories of dynamic resolution of uncertainty during decision making in biological brains, we propose a simple accumulator module which accumulates evidence in favor of each possible decision, encodes uncertainty as a dynamic competition between actions, and acts on the environment only when it is sufficiently confident in the chosen action. The agent makes no decision by default, and the burden of proof to make a decision falls on the policy to accrue evidence strongly in favor of a single decision. Our results show that this accumulator module achieves near-optimal performance on a simple guessing game, far outperforming deep recurrent networks using traditional, forced action selection policies.