 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
One to rule them all: Towards Joint Indic Language Hate Speech Detection
Sep 28, 2021

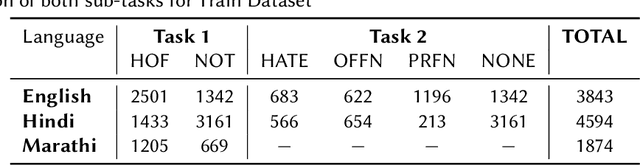
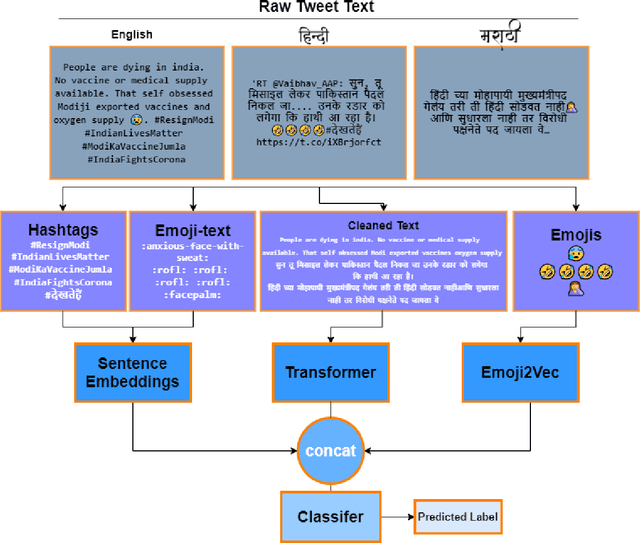
This paper is a contribution to the Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC) 2021 shared task. Social media today is a hotbed of toxic and hateful conversations, in various languages. Recent news reports have shown that current models struggle to automatically identify hate posted in minority languages. Therefore, efficiently curbing hate speech is a critical challenge and problem of interest. We present a multilingual architecture using state-of-the-art transformer language models to jointly learn hate and offensive speech detection across three languages namely, English, Hindi, and Marathi. On the provided testing corpora, we achieve Macro F1 scores of 0.7996, 0.7748, 0.8651 for sub-task 1A and 0.6268, 0.5603 during the fine-grained classification of sub-task 1B. These results show the efficacy of exploiting a multilingual training scheme.
End to End Binarized Neural Networks for Text Classification
Oct 11, 2020
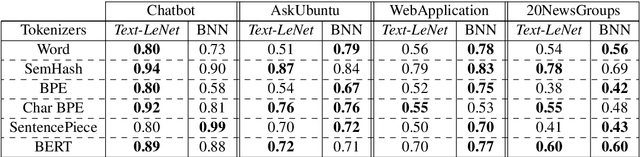

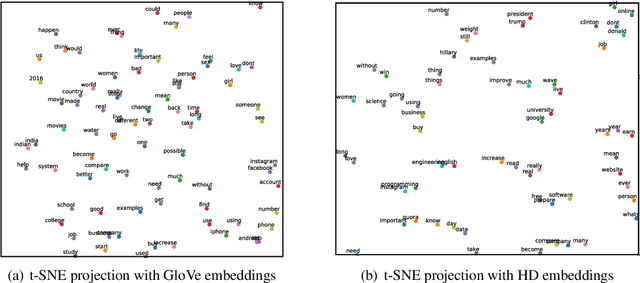
Deep neural networks have demonstrated their superior performance in almost every Natural Language Processing task, however, their increasing complexity raises concerns. In particular, these networks require high expenses on computational hardware, and training budget is a concern for many. Even for a trained network, the inference phase can be too demanding for resource-constrained devices, thus limiting its applicability. The state-of-the-art transformer models are a vivid example. Simplifying the computations performed by a network is one way of relaxing the complexity requirements. In this paper, we propose an end to end binarized neural network architecture for the intent classification task. In order to fully utilize the potential of end to end binarization, both input representations (vector embeddings of tokens statistics) and the classifier are binarized. We demonstrate the efficiency of such architecture on the intent classification of short texts over three datasets and for text classification with a larger dataset. The proposed architecture achieves comparable to the state-of-the-art results on standard intent classification datasets while utilizing ~ 20-40% lesser memory and training time. Furthermore, the individual components of the architecture, such as binarized vector embeddings of documents or binarized classifiers, can be used separately with not necessarily fully binary architectures.
Learning Transferable Cooperative Behavior in Multi-Agent Teams
Jun 04, 2019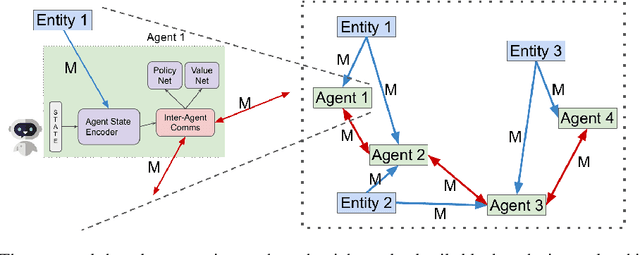

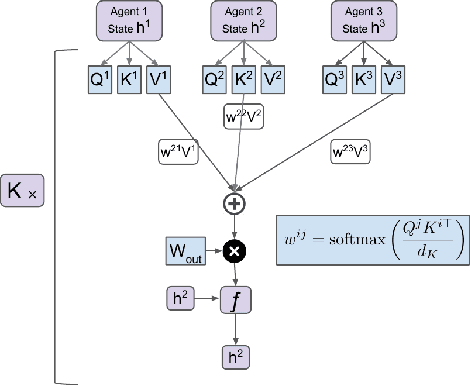

While multi-agent interactions can be naturally modeled as a graph, the environment has traditionally been considered as a black box. We propose to create a shared agent-entity graph, where agents and environmental entities form vertices, and edges exist between the vertices which can communicate with each other. Agents learn to cooperate by exchanging messages along the edges of this graph. Our proposed multi-agent reinforcement learning framework is invariant to the number of agents or entities present in the system as well as permutation invariance, both of which are desirable properties for any multi-agent system representation. We present state-of-the-art results on coverage, formation and line control tasks for multi-agent teams in a fully decentralized framework and further show that the learned policies quickly transfer to scenarios with different team sizes along with strong zero-shot generalization performance. This is an important step towards developing multi-agent teams which can be realistically deployed in the real world without assuming complete prior knowledge or instantaneous communication at unbounded distances.
Better Safe than Sorry: Evidence Accumulation Allows for Safe Reinforcement Learning
Sep 24, 2018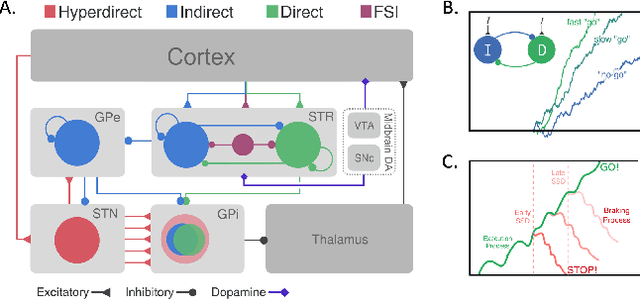
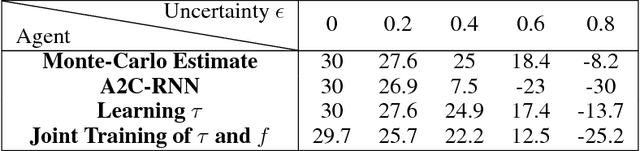
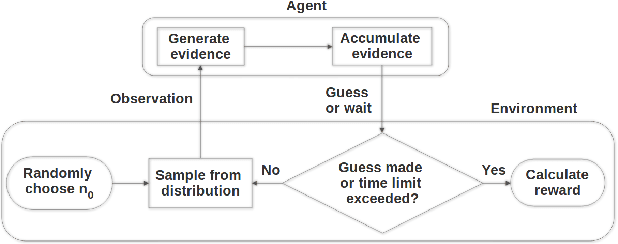
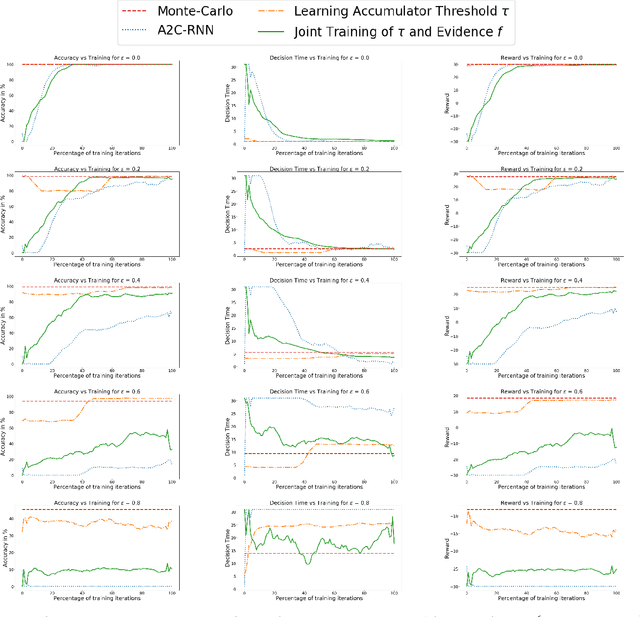
In the real world, agents often have to operate in situations with incomplete information, limited sensing capabilities, and inherently stochastic environments, making individual observations incomplete and unreliable. Moreover, in many situations it is preferable to delay a decision rather than run the risk of making a bad decision. In such situations it is necessary to aggregate information before taking an action; however, most state of the art reinforcement learning (RL) algorithms are biased towards taking actions \textit{at every time step}, even if the agent is not particularly confident in its chosen action. This lack of caution can lead the agent to make critical mistakes, regardless of prior experience and acclimation to the environment. Motivated by theories of dynamic resolution of uncertainty during decision making in biological brains, we propose a simple accumulator module which accumulates evidence in favor of each possible decision, encodes uncertainty as a dynamic competition between actions, and acts on the environment only when it is sufficiently confident in the chosen action. The agent makes no decision by default, and the burden of proof to make a decision falls on the policy to accrue evidence strongly in favor of a single decision. Our results show that this accumulator module achieves near-optimal performance on a simple guessing game, far outperforming deep recurrent networks using traditional, forced action selection policies.
Learning Time-Sensitive Strategies in Space Fortress
Sep 13, 2018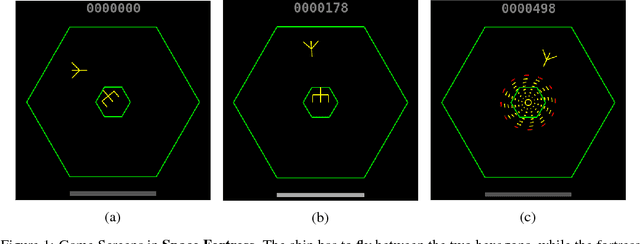


Although there has been remarkable progress and impressive performance on reinforcement learning (RL) on Atari games, there are many problems with challenging characteristics that have not yet been explored in Deep Learning for RL. These include reward sparsity, abrupt context-dependent reversals of strategy and time-sensitive game play. In this paper, we present Space Fortress, a game that incorporates all these characteristics and experimentally show that the presence of any of these renders state of the art Deep RL algorithms incapable of learning. Then, we present our enhancements to an existing algorithm and show big performance increases through each enhancement through an ablation study. We discuss how each of these enhancements was able to help and also argue that appropriate transfer learning boosts performance.
Challenges of Context and Time in Reinforcement Learning: Introducing Space Fortress as a Benchmark
Sep 06, 2018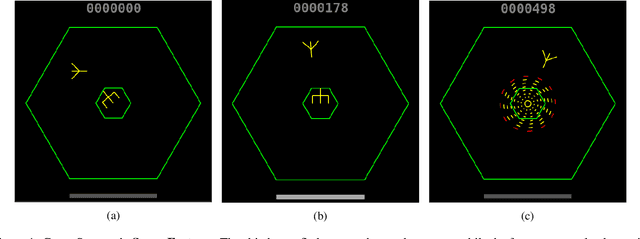

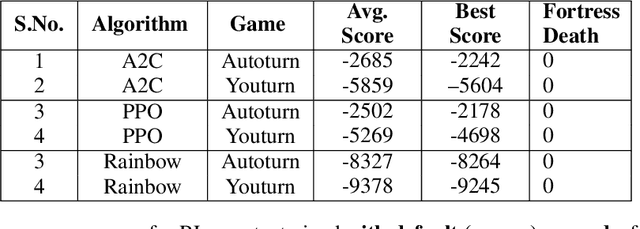
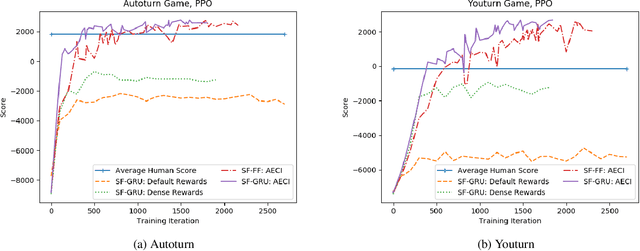
Research in deep reinforcement learning (RL) has coalesced around improving performance on benchmarks like the Arcade Learning Environment. However, these benchmarks conspicuously miss important characteristics like abrupt context-dependent shifts in strategy and temporal sensitivity that are often present in real-world domains. As a result, RL research has not focused on these challenges, resulting in algorithms which do not understand critical changes in context, and have little notion of real world time. To tackle this issue, this paper introduces the game of Space Fortress as a RL benchmark which incorporates these characteristics. We show that existing state-of-the-art RL algorithms are unable to learn to play the Space Fortress game. We then confirm that this poor performance is due to the RL algorithms' context insensitivity and reward sparsity. We also identify independent axes along which to vary context and temporal sensitivity, allowing Space Fortress to be used as a testbed for understanding both characteristics in combination and also in isolation. We release Space Fortress as an open-source Gym environment.
Community Regularization of Visually-Grounded Dialog
Sep 06, 2018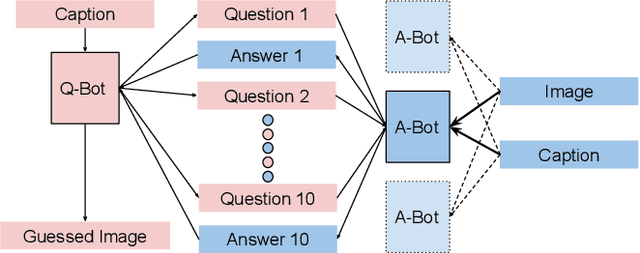
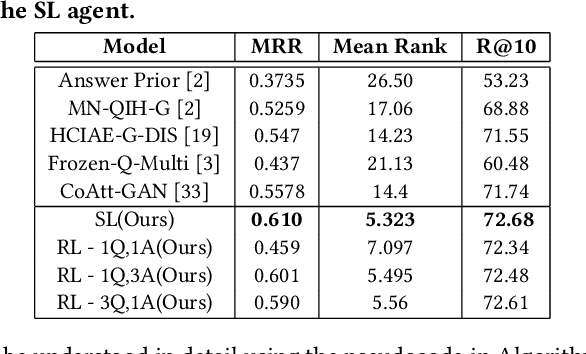


The task of conducting visually grounded dialog involves learning goal-oriented cooperative dialog between autonomous agents who exchange information about a scene through several rounds of questions and answers in natural language. We posit that requiring artificial agents to adhere to the rules of human language, while also requiring them to maximize information exchange through dialog is an ill-posed problem. We observe that humans do not stray from a common language because they are social creatures who live in communities, and have to communicate with many people everyday, so it is far easier to stick to a common language even at the cost of some efficiency loss. Using this as inspiration, we propose and evaluate a multi-agent community-based dialog framework where each agent interacts with, and learns from, multiple agents, and show that this community-enforced regularization results in more relevant and coherent dialog (as judged by human evaluators) without sacrificing task performance (as judged by quantitative metrics).