 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd to End Binarized Neural Networks for Text Classification
Paper and Code

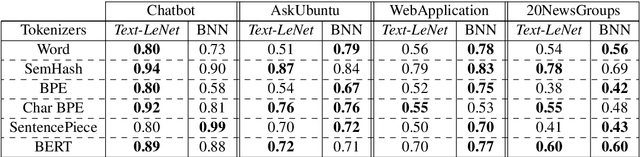

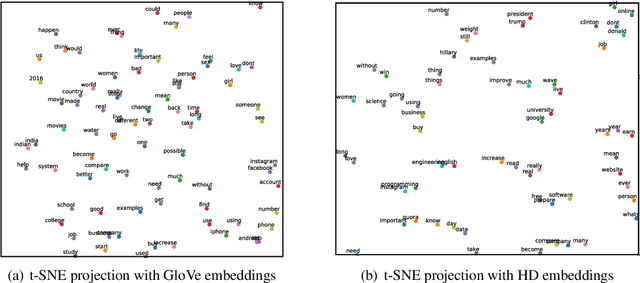
Deep neural networks have demonstrated their superior performance in almost every Natural Language Processing task, however, their increasing complexity raises concerns. In particular, these networks require high expenses on computational hardware, and training budget is a concern for many. Even for a trained network, the inference phase can be too demanding for resource-constrained devices, thus limiting its applicability. The state-of-the-art transformer models are a vivid example. Simplifying the computations performed by a network is one way of relaxing the complexity requirements. In this paper, we propose an end to end binarized neural network architecture for the intent classification task. In order to fully utilize the potential of end to end binarization, both input representations (vector embeddings of tokens statistics) and the classifier are binarized. We demonstrate the efficiency of such architecture on the intent classification of short texts over three datasets and for text classification with a larger dataset. The proposed architecture achieves comparable to the state-of-the-art results on standard intent classification datasets while utilizing ~ 20-40% lesser memory and training time. Furthermore, the individual components of the architecture, such as binarized vector embeddings of documents or binarized classifiers, can be used separately with not necessarily fully binary architectures.