 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges of Context and Time in Reinforcement Learning: Introducing Space Fortress as a Benchmark
Paper and Code
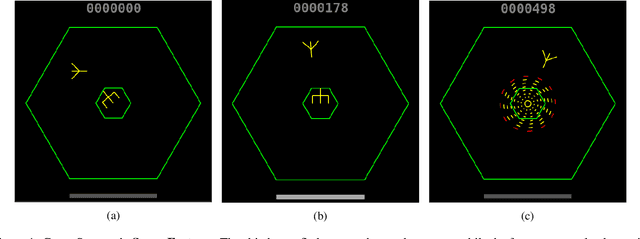

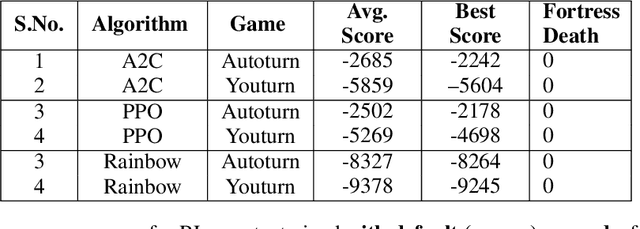
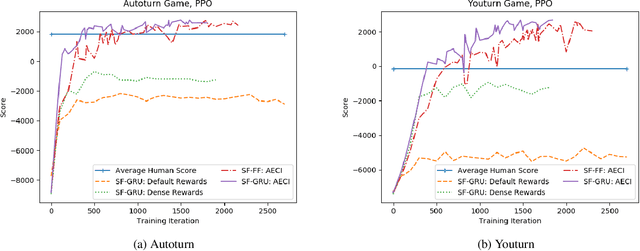
Research in deep reinforcement learning (RL) has coalesced around improving performance on benchmarks like the Arcade Learning Environment. However, these benchmarks conspicuously miss important characteristics like abrupt context-dependent shifts in strategy and temporal sensitivity that are often present in real-world domains. As a result, RL research has not focused on these challenges, resulting in algorithms which do not understand critical changes in context, and have little notion of real world time. To tackle this issue, this paper introduces the game of Space Fortress as a RL benchmark which incorporates these characteristics. We show that existing state-of-the-art RL algorithms are unable to learn to play the Space Fortress game. We then confirm that this poor performance is due to the RL algorithms' context insensitivity and reward sparsity. We also identify independent axes along which to vary context and temporal sensitivity, allowing Space Fortress to be used as a testbed for understanding both characteristics in combination and also in isolation. We release Space Fortress as an open-source Gym environment.