 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Martingale Kernel Independence Test
May 21, 2026The Hilbert-Schmidt Independence Criterion (HSIC) and its joint-independence extension $d\mathrm{HSIC}$ are degenerate $V$-statistics whose data-dependent weighted-$χ^2$ null limits force a permutation calibration that multiplies the per-test cost by the number of permutations, in practice two orders of magnitude. Adapting the recent martingale MMD construction for two-sample testing to the (joint) independence problem, we introduce two studentised statistics whose null distributions are standard normal regardless of the data law, so that a single normal-quantile lookup replaces the permutation step entirely. The first, $m\mathrm{HSIC}$, is a self-normalised lower-triangular sum of the Hadamard product of two empirically centred Gram matrices. Under independence and bounded-fourth-moment kernels it converges to a standard normal. It is consistent against every fixed alternative, and runs at quadratic cost in the sample size without any sample split, matching the biased HSIC $V$-statistic. Our second statistic, $md\mathrm{HSIC}$, achieves finite-sample consistency with a single half-sample split: the centring is estimated on one half and the lower-triangular self-normalised martingale is run on the other, shrinking the conditional-mean residual to a quantity that is exponentially small in $d$, so the statistic is asymptotically standard normal at every fixed number of jointly tested variables, with a per-test cost that grows only linearly in $d$. On synthetic data with per-variable input dimension from $1$ to $500$ and between $2$ and $10$ jointly tested variables, both statistics match the empirical type-I error rate and test power of permutation-calibrated baselines while running $25$ to $60\times$ faster.
A continuous Structural Intervention Distance to compare Causal Graphs
Jul 31, 2023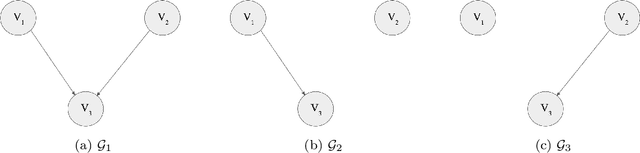
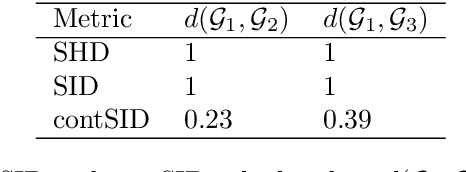
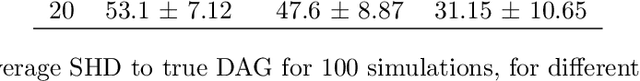
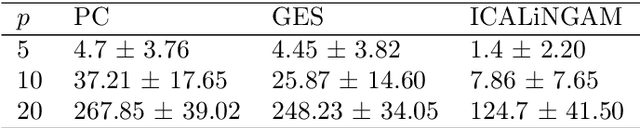
Understanding and adequately assessing the difference between a true and a learnt causal graphs is crucial for causal inference under interventions. As an extension to the graph-based structural Hamming distance and structural intervention distance, we propose a novel continuous-measured metric that considers the underlying data in addition to the graph structure for its calculation of the difference between a true and a learnt causal graph. The distance is based on embedding intervention distributions over each pair of nodes as conditional mean embeddings into reproducing kernel Hilbert spaces and estimating their difference by the maximum (conditional) mean discrepancy. We show theoretical results which we validate with numerical experiments on synthetic data.
Kernel-based Joint Independence Tests for Multivariate Stationary and Nonstationary Time-Series
May 15, 2023



Multivariate time-series data that capture the temporal evolution of interconnected systems are ubiquitous in diverse areas. Understanding the complex relationships and potential dependencies among co-observed variables is crucial for the accurate statistical modelling and analysis of such systems. Here, we introduce kernel-based statistical tests of joint independence in multivariate time-series by extending the d-variable Hilbert-Schmidt independence criterion (dHSIC) to encompass both stationary and nonstationary random processes, thus allowing broader real-world applications. By leveraging resampling techniques tailored for both single- and multiple-realization time series, we show how the method robustly uncovers significant higher-order dependencies in synthetic examples, including frequency mixing data, as well as real-world climate and socioeconomic data. Our method adds to the mathematical toolbox for the analysis of complex high-dimensional time-series datasets.
One to rule them all: Towards Joint Indic Language Hate Speech Detection
Sep 28, 2021

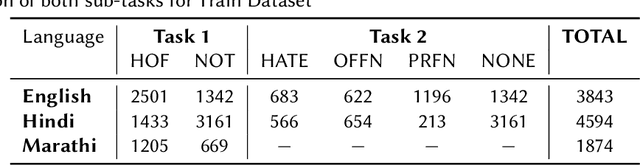
This paper is a contribution to the Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC) 2021 shared task. Social media today is a hotbed of toxic and hateful conversations, in various languages. Recent news reports have shown that current models struggle to automatically identify hate posted in minority languages. Therefore, efficiently curbing hate speech is a critical challenge and problem of interest. We present a multilingual architecture using state-of-the-art transformer language models to jointly learn hate and offensive speech detection across three languages namely, English, Hindi, and Marathi. On the provided testing corpora, we achieve Macro F1 scores of 0.7996, 0.7748, 0.8651 for sub-task 1A and 0.6268, 0.5603 during the fine-grained classification of sub-task 1B. These results show the efficacy of exploiting a multilingual training scheme.
Indic-Transformers: An Analysis of Transformer Language Models for Indian Languages
Nov 04, 2020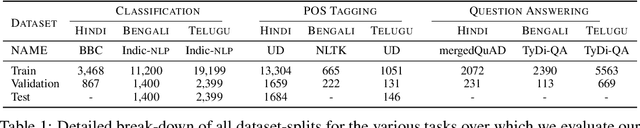
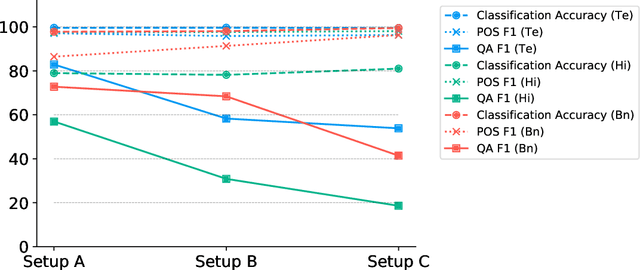
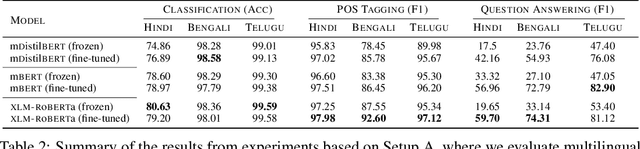

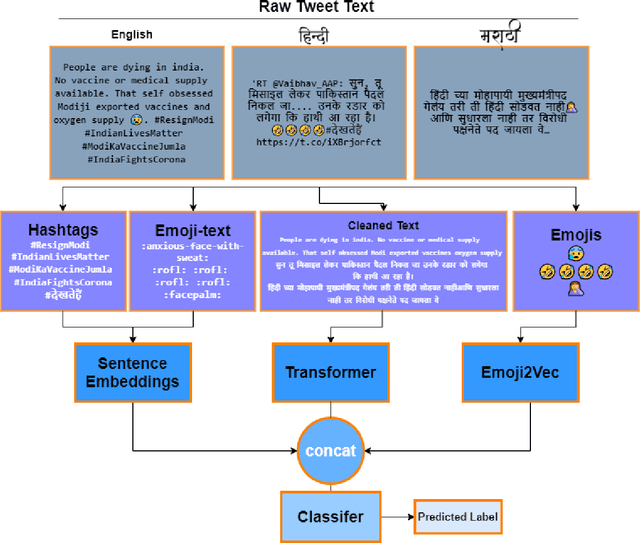
Language models based on the Transformer architecture have achieved state-of-the-art performance on a wide range of NLP tasks such as text classification, question-answering, and token classification. However, this performance is usually tested and reported on high-resource languages, like English, French, Spanish, and German. Indian languages, on the other hand, are underrepresented in such benchmarks. Despite some Indian languages being included in training multilingual Transformer models, they have not been the primary focus of such work. In order to evaluate the performance on Indian languages specifically, we analyze these language models through extensive experiments on multiple downstream tasks in Hindi, Bengali, and Telugu language. Here, we compare the efficacy of fine-tuning model parameters of pre-trained models against that of training a language model from scratch. Moreover, we empirically argue against the strict dependency between the dataset size and model performance, but rather encourage task-specific model and method selection. We achieve state-of-the-art performance on Hindi and Bengali languages for text classification task. Finally, we present effective strategies for handling the modeling of Indian languages and we release our model checkpoints for the community : https://huggingface.co/neuralspace-reverie.
A Comprehensive guide to Bayesian Convolutional Neural Network with Variational Inference
Jan 08, 2019



Artificial Neural Networks are connectionist systems that perform a given task by learning on examples without having prior knowledge about the task. This is done by finding an optimal point estimate for the weights in every node. Generally, the network using point estimates as weights perform well with large datasets, but they fail to express uncertainty in regions with little or no data, leading to overconfident decisions. In this paper, Bayesian Convolutional Neural Network (BayesCNN) using Variational Inference is proposed, that introduces probability distribution over the weights. Furthermore, the proposed BayesCNN architecture is applied to tasks like Image Classification, Image Super-Resolution and Generative Adversarial Networks. The results are compared to point-estimates based architectures on MNIST, CIFAR-10 and CIFAR-100 datasets for Image CLassification task, on BSD300 dataset for Image Super Resolution task and on CIFAR10 dataset again for Generative Adversarial Network task. BayesCNN is based on Bayes by Backprop which derives a variational approximation to the true posterior. We, therefore, introduce the idea of applying two convolutional operations, one for the mean and one for the variance. Our proposed method not only achieves performances equivalent to frequentist inference in identical architectures but also incorporate a measurement for uncertainties and regularisation. It further eliminates the use of dropout in the model. Moreover, we predict how certain the model prediction is based on the epistemic and aleatoric uncertainties and empirically show how the uncertainty can decrease, allowing the decisions made by the network to become more deterministic as the training accuracy increases. Finally, we propose ways to prune the Bayesian architecture and to make it more computational and time effective.
Bayesian Convolutional Neural Networks
Sep 10, 2018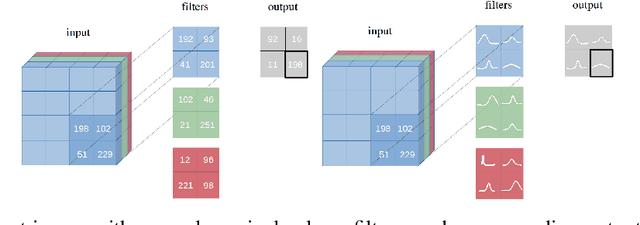
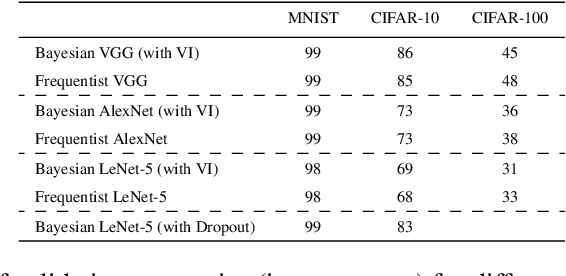
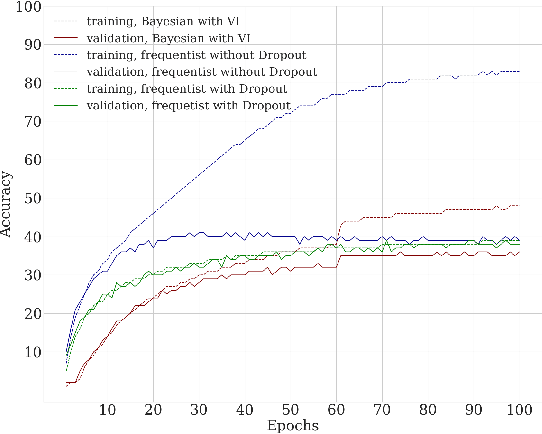
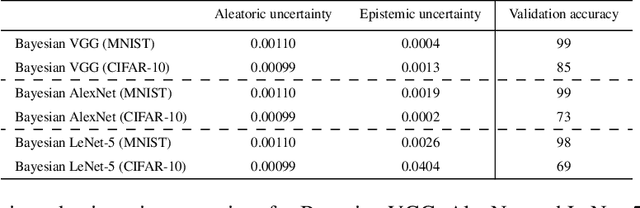
We introduce Bayesian Convolutional Neural Networks (BayesCNNs), a variant of Convolutional Neural Networks (CNNs) which is built upon Bayes by Backprop. We demonstrate how this novel reliable variational inference method can serve as a fundamental construct for various network architectures. On multiple datasets in supervised learning settings (MNIST, CIFAR-10, CIFAR-100, and STL-10), our proposed variational inference method achieves performances equivalent to frequentist inference in identical architectures, while a measurement for uncertainties and a regularisation are incorporated naturally. In the past, Bayes by Backprop has been successfully implemented in feedforward and recurrent neural networks, but not in convolutional ones. This work symbolises the extension of Bayesian neural networks which encompasses all three aforementioned types of network architectures now.