 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-theoretic signatures of causality in Bayesian networks and hypergraphs
Dec 23, 2025Analyzing causality in multivariate systems involves establishing how information is generated, distributed and combined, and thus requires tools that capture interactions beyond pairwise relations. Higher-order information theory provides such tools. In particular, Partial Information Decomposition (PID) allows the decomposition of the information that a set of sources provides about a target into redundant, unique, and synergistic components. Yet the mathematical connection between such higher-order information-theoretic measures and causal structure remains undeveloped. Here we establish the first theoretical correspondence between PID components and causal structure in both Bayesian networks and hypergraphs. We first show that in Bayesian networks unique information precisely characterizes direct causal neighbors, while synergy identifies collider relationships. This establishes a localist causal discovery paradigm in which the structure surrounding each variable can be recovered from its immediate informational footprint, eliminating the need for global search over graph space. Extending these results to higher-order systems, we prove that PID signatures in Bayesian hypergraphs differentiate parents, children, co-heads, and co-tails, revealing a higher-order collider effect unique to multi-tail hyperedges. We also present procedures by which our results can be used to characterize systematically the causal structure of Bayesian networks and hypergraphs. Our results position PID as a rigorous, model-agnostic foundation for inferring both pairwise and higher-order causal structure, and introduce a fundamentally local information-theoretic viewpoint on causal discovery.
Permutation-Free High-Order Interaction Tests
Jun 06, 2025Kernel-based hypothesis tests offer a flexible, non-parametric tool to detect high-order interactions in multivariate data, beyond pairwise relationships. Yet the scalability of such tests is limited by the computationally demanding permutation schemes used to generate null approximations. Here we introduce a family of permutation-free high-order tests for joint independence and partial factorisations of $d$ variables. Our tests eliminate the need for permutation-based approximations by leveraging V-statistics and a novel cross-centring technique to yield test statistics with a standard normal limiting distribution under the null. We present implementations of the tests and showcase their efficacy and scalability through synthetic datasets. We also show applications inspired by causal discovery and feature selection, which highlight both the importance of high-order interactions in data and the need for efficient computational methods.
Hyperspectral Image Restoration and Super-resolution with Physics-Aware Deep Learning for Biomedical Applications
Mar 03, 2025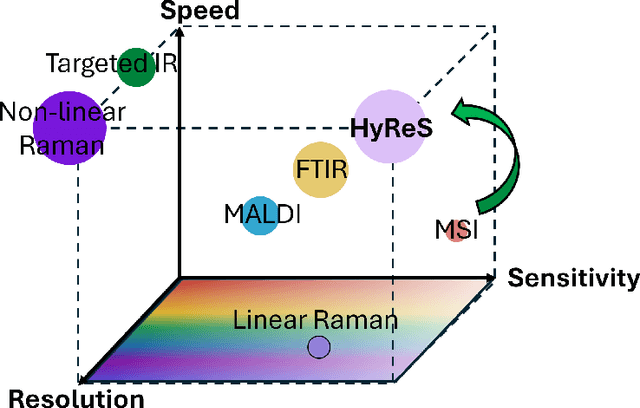
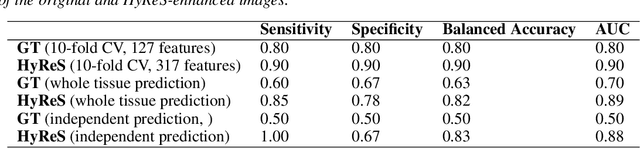
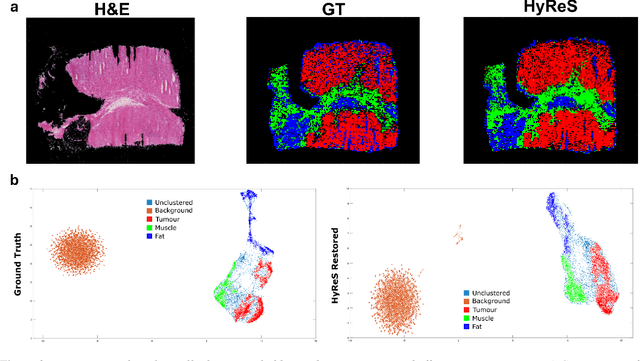
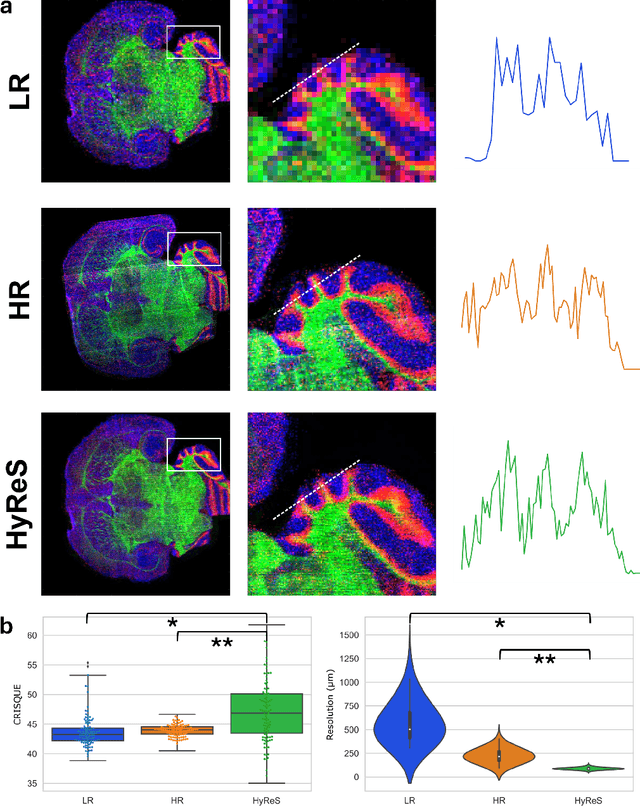
Hyperspectral imaging is a powerful bioimaging tool which can uncover novel insights, thanks to its sensitivity to the intrinsic properties of materials. However, this enhanced contrast comes at the cost of system complexity, constrained by an inherent trade-off between spatial resolution, spectral resolution, and imaging speed. To overcome this limitation, we present a deep learning-based approach that restores and enhances pixel resolution post-acquisition without any a priori knowledge. Fine-tuned using metrics aligned with the imaging model, our physics-aware method achieves a 16X pixel super-resolution enhancement and a 12X imaging speedup without the need of additional training data for transfer learning. Applied to both synthetic and experimental data from five different sample types, we demonstrate that the model preserves biological integrity, ensuring no features are lost or hallucinated. We also concretely demonstrate the model's ability to reveal disease-associated metabolic changes in Downs syndrome that would otherwise remain undetectable. Furthermore, we provide physical insights into the inner workings of the model, paving the way for future refinements that could potentially surpass instrumental limits in an explainable manner. All methods are available as open-source software on GitHub.
Information-Theoretic Measures on Lattices for High-Order Interactions
Aug 14, 2024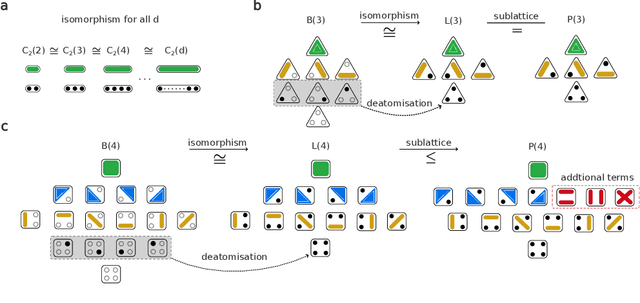

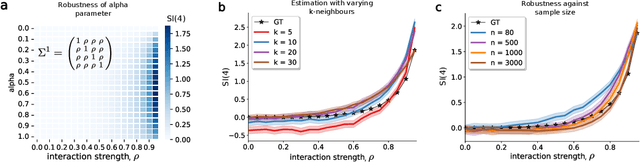

Traditional models reliant solely on pairwise associations often prove insufficient in capturing the complex statistical structure inherent in multivariate data. Yet existing methods for identifying information shared among groups of $d>3$ variables are often intractable; asymmetric around a target variable; or unable to consider all factorisations of the joint probability distribution. Here, we present a framework that systematically derives high-order measures using lattice and operator function pairs, whereby the lattice captures the algebraic relational structure of the variables and the operator function computes measures over the lattice. We show that many existing information-theoretic high-order measures can be derived by using divergences as operator functions on sublattices of the partition lattice, thus preventing the accurate quantification of all interactions for $d>3$. Similarly, we show that using the KL divergence as the operator function also leads to unwanted cancellation of interactions for $d>3$. To characterise all interactions among $d$ variables, we introduce the Streitberg information defined on the full partition lattice using generalisations of the KL divergence as operator functions. We validate our results numerically on synthetic data, and illustrate the use of the Streitberg information through applications to stock market returns and neural electrophysiology data.
Interaction Measures, Partition Lattices and Kernel Tests for High-Order Interactions
Jun 01, 2023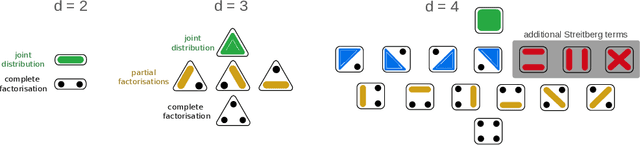

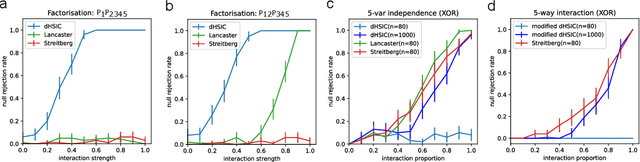

Models that rely solely on pairwise relationships often fail to capture the complete statistical structure of the complex multivariate data found in diverse domains, such as socio-economic, ecological, or biomedical systems. Non-trivial dependencies between groups of more than two variables can play a significant role in the analysis and modelling of such systems, yet extracting such high-order interactions from data remains challenging. Here, we introduce a hierarchy of $d$-order ($d \geq 2$) interaction measures, increasingly inclusive of possible factorisations of the joint probability distribution, and define non-parametric, kernel-based tests to establish systematically the statistical significance of $d$-order interactions. We also establish mathematical links with lattice theory, which elucidate the derivation of the interaction measures and their composite permutation tests; clarify the connection of simplicial complexes with kernel matrix centring; and provide a means to enhance computational efficiency. We illustrate our results numerically with validations on synthetic data, and through an application to neuroimaging data.
Kernel-based Joint Independence Tests for Multivariate Stationary and Nonstationary Time-Series
May 15, 2023



Multivariate time-series data that capture the temporal evolution of interconnected systems are ubiquitous in diverse areas. Understanding the complex relationships and potential dependencies among co-observed variables is crucial for the accurate statistical modelling and analysis of such systems. Here, we introduce kernel-based statistical tests of joint independence in multivariate time-series by extending the d-variable Hilbert-Schmidt independence criterion (dHSIC) to encompass both stationary and nonstationary random processes, thus allowing broader real-world applications. By leveraging resampling techniques tailored for both single- and multiple-realization time series, we show how the method robustly uncovers significant higher-order dependencies in synthetic examples, including frequency mixing data, as well as real-world climate and socioeconomic data. Our method adds to the mathematical toolbox for the analysis of complex high-dimensional time-series datasets.