 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Brain-like Synergistic Core in LLMs Drives Behaviour and Learning
Jan 11, 2026The independent evolution of intelligence in biological and artificial systems offers a unique opportunity to identify its fundamental computational principles. Here we show that large language models spontaneously develop synergistic cores -- components where information integration exceeds individual parts -- remarkably similar to those in the human brain. Using principles of information decomposition across multiple LLM model families and architectures, we find that areas in middle layers exhibit synergistic processing while early and late layers rely on redundancy, mirroring the informational organisation in biological brains. This organisation emerges through learning and is absent in randomly initialised networks. Crucially, ablating synergistic components causes disproportionate behavioural changes and performance loss, aligning with theoretical predictions about the fragility of synergy. Moreover, fine-tuning synergistic regions through reinforcement learning yields significantly greater performance gains than training redundant components, yet supervised fine-tuning shows no such advantage. This convergence suggests that synergistic information processing is a fundamental property of intelligence, providing targets for principled model design and testable predictions for biological intelligence.
On the Identifiability of Regime-Switching Models with Multi-Lag Dependencies
Jan 06, 2026Identifiability is central to the interpretability of deep latent variable models, ensuring parameterisations are uniquely determined by the data-generating distribution. However, it remains underexplored for deep regime-switching time series. We develop a general theoretical framework for multi-lag Regime-Switching Models (RSMs), encompassing Markov Switching Models (MSMs) and Switching Dynamical Systems (SDSs). For MSMs, we formulate the model as a temporally structured finite mixture and prove identifiability of both the number of regimes and the multi-lag transitions in a nonlinear-Gaussian setting. For SDSs, we establish identifiability of the latent variables up to permutation and scaling via temporal structure, which in turn yields conditions for identifiability of regime-dependent latent causal graphs (up to regime/node permutations). Our results hold in a fully unsupervised setting through architectural and noise assumptions that are directly enforceable via neural network design. We complement the theory with a flexible variational estimator that satisfies the assumptions and validate the results on synthetic benchmarks. Across real-world datasets from neuroscience, finance, and climate, identifiability leads to more trustworthy interpretability analysis, which is crucial for scientific discovery.
Shannon invariants: A scalable approach to information decomposition
Apr 22, 2025



Distributed systems, such as biological and artificial neural networks, process information via complex interactions engaging multiple subsystems, resulting in high-order patterns with distinct properties across scales. Investigating how these systems process information remains challenging due to difficulties in defining appropriate multivariate metrics and ensuring their scalability to large systems. To address these challenges, we introduce a novel framework based on what we call "Shannon invariants" -- quantities that capture essential properties of high-order information processing in a way that depends only on the definition of entropy and can be efficiently calculated for large systems. Our theoretical results demonstrate how Shannon invariants can be used to resolve long-standing ambiguities regarding the interpretation of widely used multivariate information-theoretic measures. Moreover, our practical results reveal distinctive information-processing signatures of various deep learning architectures across layers, which lead to new insights into how these systems process information and how this evolves during training. Overall, our framework resolves fundamental limitations in analyzing high-order phenomena and offers broad opportunities for theoretical developments and empirical analyses.
Grokking at the Edge of Numerical Stability
Jan 08, 2025Grokking, the sudden generalization that occurs after prolonged overfitting, is a surprising phenomenon challenging our understanding of deep learning. Although significant progress has been made in understanding grokking, the reasons behind the delayed generalization and its dependence on regularization remain unclear. In this work, we argue that without regularization, grokking tasks push models to the edge of numerical stability, introducing floating point errors in the Softmax function, which we refer to as Softmax Collapse (SC). We demonstrate that SC prevents grokking and that mitigating SC enables grokking without regularization. Investigating the root cause of SC, we find that beyond the point of overfitting, the gradients strongly align with what we call the na\"ive loss minimization (NLM) direction. This component of the gradient does not alter the model's predictions but decreases the loss by scaling the logits, typically by scaling the weights along their current direction. We show that this scaling of the logits explains the delay in generalization characteristic of grokking and eventually leads to SC, halting further learning. To validate our hypotheses, we introduce two key contributions that address the challenges in grokking tasks: StableMax, a new activation function that prevents SC and enables grokking without regularization, and $\perp$Grad, a training algorithm that promotes quick generalization in grokking tasks by preventing NLM altogether. These contributions provide new insights into grokking, elucidating its delayed generalization, reliance on regularization, and the effectiveness of existing grokking-inducing methods. Code for this paper is available at https://github.com/LucasPrietoAl/grokking-at-the-edge-of-numerical-stability.
From Lazy to Rich: Exact Learning Dynamics in Deep Linear Networks
Sep 22, 2024



Biological and artificial neural networks develop internal representations that enable them to perform complex tasks. In artificial networks, the effectiveness of these models relies on their ability to build task specific representation, a process influenced by interactions among datasets, architectures, initialization strategies, and optimization algorithms. Prior studies highlight that different initializations can place networks in either a lazy regime, where representations remain static, or a rich/feature learning regime, where representations evolve dynamically. Here, we examine how initialization influences learning dynamics in deep linear neural networks, deriving exact solutions for lambda-balanced initializations-defined by the relative scale of weights across layers. These solutions capture the evolution of representations and the Neural Tangent Kernel across the spectrum from the rich to the lazy regimes. Our findings deepen the theoretical understanding of the impact of weight initialization on learning regimes, with implications for continual learning, reversal learning, and transfer learning, relevant to both neuroscience and practical applications.
Identifying Nonstationary Causal Structures with High-Order Markov Switching Models
Jun 25, 2024
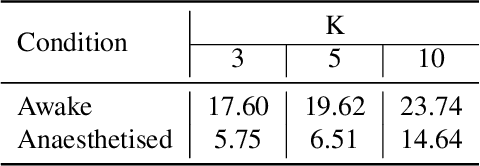

Causal discovery in time series is a rapidly evolving field with a wide variety of applications in other areas such as climate science and neuroscience. Traditional approaches assume a stationary causal graph, which can be adapted to nonstationary time series with time-dependent effects or heterogeneous noise. In this work we address nonstationarity via regime-dependent causal structures. We first establish identifiability for high-order Markov Switching Models, which provide the foundations for identifiable regime-dependent causal discovery. Our empirical studies demonstrate the scalability of our proposed approach for high-order regime-dependent structure estimation, and we illustrate its applicability on brain activity data.
Interaction Measures, Partition Lattices and Kernel Tests for High-Order Interactions
Jun 01, 2023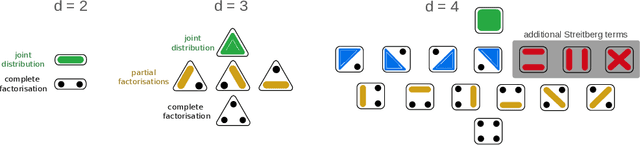

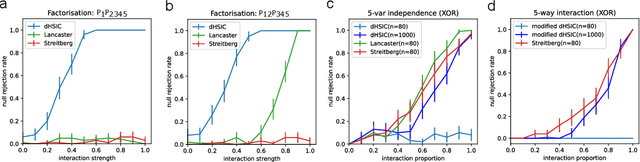

Models that rely solely on pairwise relationships often fail to capture the complete statistical structure of the complex multivariate data found in diverse domains, such as socio-economic, ecological, or biomedical systems. Non-trivial dependencies between groups of more than two variables can play a significant role in the analysis and modelling of such systems, yet extracting such high-order interactions from data remains challenging. Here, we introduce a hierarchy of $d$-order ($d \geq 2$) interaction measures, increasingly inclusive of possible factorisations of the joint probability distribution, and define non-parametric, kernel-based tests to establish systematically the statistical significance of $d$-order interactions. We also establish mathematical links with lattice theory, which elucidate the derivation of the interaction measures and their composite permutation tests; clarify the connection of simplicial complexes with kernel matrix centring; and provide a means to enhance computational efficiency. We illustrate our results numerically with validations on synthetic data, and through an application to neuroimaging data.
Synergistic information supports modality integration and flexible learning in neural networks solving multiple tasks
Oct 06, 2022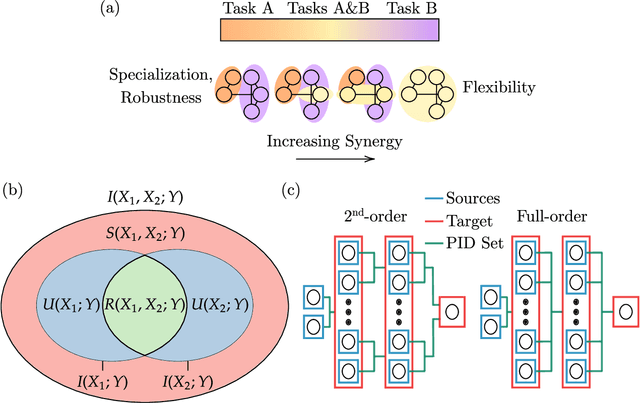
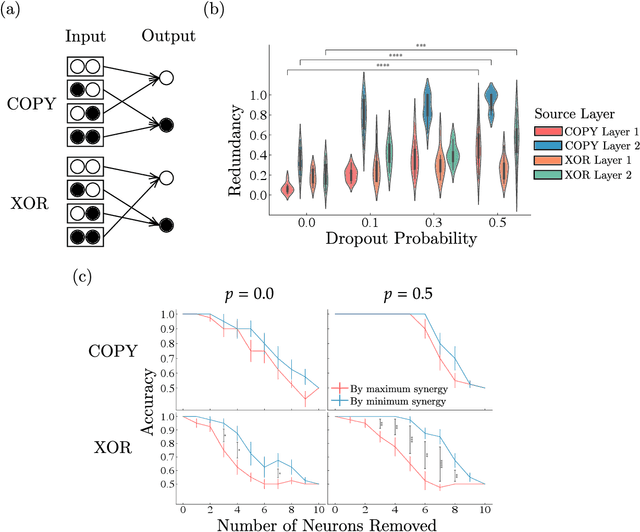
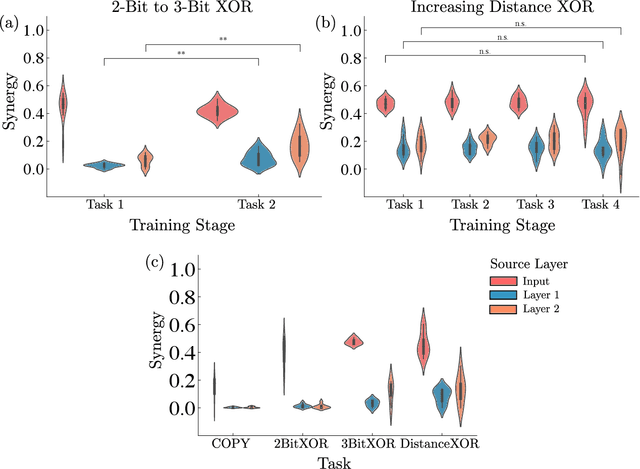
Striking progress has recently been made in understanding human cognition by analyzing how its neuronal underpinnings are engaged in different modes of information processing. Specifically, neural information can be decomposed into synergistic, redundant, and unique features, with synergistic components being particularly aligned with complex cognition. However, two fundamental questions remain unanswered: (a) precisely how and why a cognitive system can become highly synergistic; and (b) how these informational states map onto artificial neural networks in various learning modes. To address these questions, here we employ an information-decomposition framework to investigate the information processing strategies adopted by simple artificial neural networks performing a variety of cognitive tasks in both supervised and reinforcement learning settings. Our results show that synergy increases as neural networks learn multiple diverse tasks. Furthermore, performance in tasks requiring integration of multiple information sources critically relies on synergistic neurons. Finally, randomly turning off neurons during training through dropout increases network redundancy, corresponding to an increase in robustness. Overall, our results suggest that while redundant information is required for robustness to perturbations in the learning process, synergistic information is used to combine information from multiple modalities -- and more generally for flexible and efficient learning. These findings open the door to new ways of investigating how and why learning systems employ specific information-processing strategies, and support the principle that the capacity for general-purpose learning critically relies in the system's information dynamics.
Learning, compression, and leakage: Minimizing classification error via meta-universal compression principles
Oct 14, 2020Learning and compression are driven by the common aim of identifying and exploiting statistical regularities in data, which opens the door for fertile collaboration between these areas. A promising group of compression techniques for learning scenarios is normalised maximum likelihood (NML) coding, which provides strong guarantees for compression of small datasets - in contrast with more popular estimators whose guarantees hold only in the asymptotic limit. Here we put forward a novel NML-based decision strategy for supervised classification problems, and show that it attains heuristic PAC learning when applied to a wide variety of models. Furthermore, we show that the misclassification rate of our method is upper bounded by the maximal leakage, a recently proposed metric to quantify the potential of data leakage in privacy-sensitive scenarios.
Causal blankets: Theory and algorithmic framework
Sep 29, 2020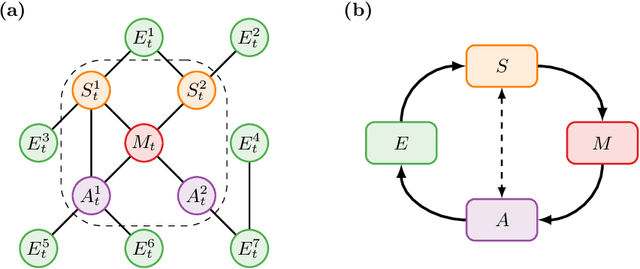
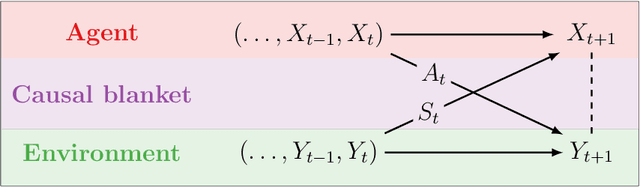
We introduce a novel framework to identify perception-action loops (PALOs) directly from data based on the principles of computational mechanics. Our approach is based on the notion of causal blanket, which captures sensory and active variables as dynamical sufficient statistics -- i.e. as the "differences that make a difference." Moreover, our theory provides a broadly applicable procedure to construct PALOs that requires neither a steady-state nor Markovian dynamics. Using our theory, we show that every bipartite stochastic process has a causal blanket, but the extent to which this leads to an effective PALO formulation varies depending on the integrated information of the bipartition.