 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimal-AI 3: What's New & Why You Should Care
Dec 18, 2023
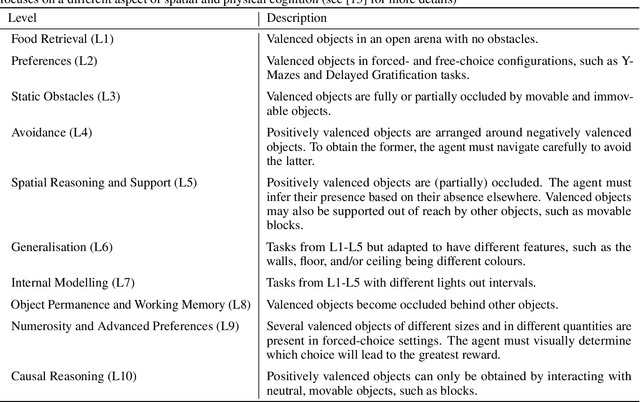
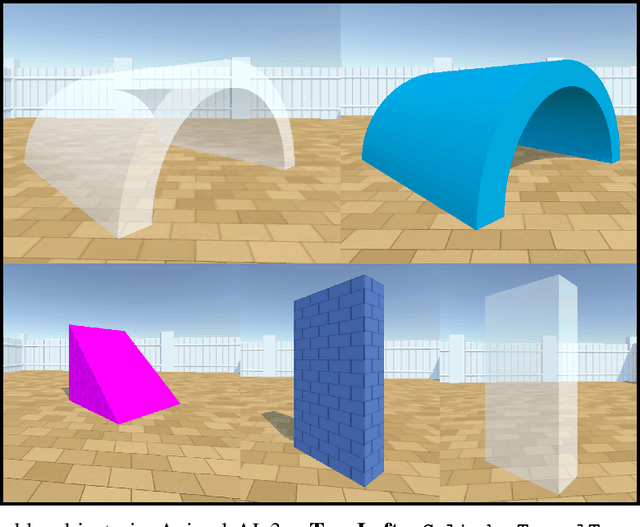
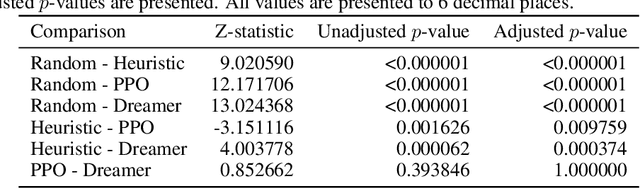
The Animal-AI Environment is a unique game-based research platform designed to serve both the artificial intelligence and cognitive science research communities. In this paper, we present Animal-AI 3, the latest version of the environment, outlining several major new features that make the game more engaging for humans and more complex for AI systems. New features include interactive buttons, reward dispensers, and player notifications, as well as an overhaul of the environment's graphics and processing for significant increases in agent training time and quality of the human player experience. We provide detailed guidance on how to build computational and behavioural experiments with Animal-AI 3. We present results from a series of agents, including the state-of-the-art Deep Reinforcement Learning agent (dreamer-v3), on newly designed tests and the Animal-AI Testbed of 900 tasks inspired by research in comparative psychology. Animal-AI 3 is designed to facilitate collaboration between the cognitive sciences and artificial intelligence. This paper serves as a stand-alone document that motivates, describes, and demonstrates Animal-AI 3 for the end user.
Synergistic information supports modality integration and flexible learning in neural networks solving multiple tasks
Oct 06, 2022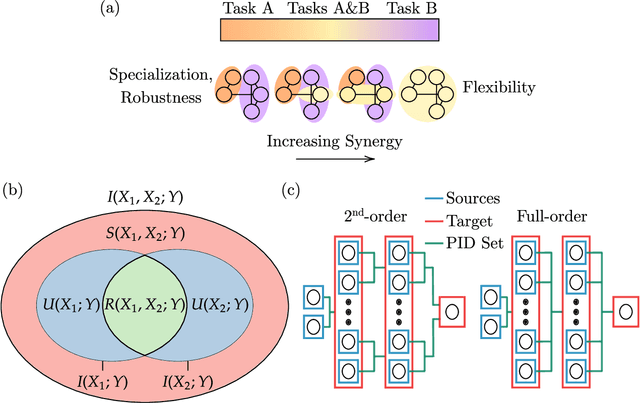
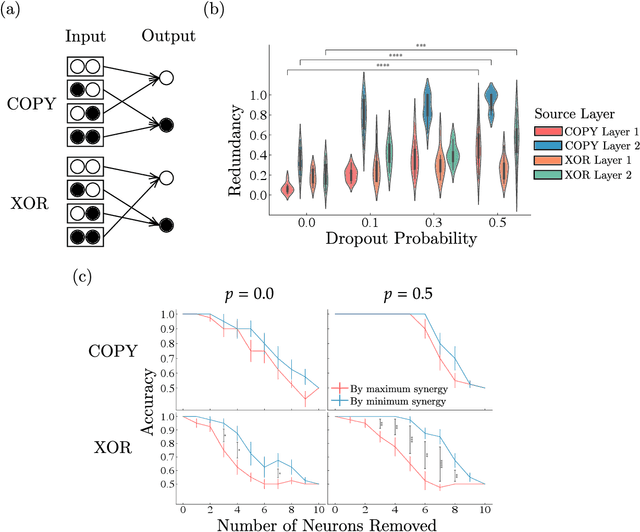
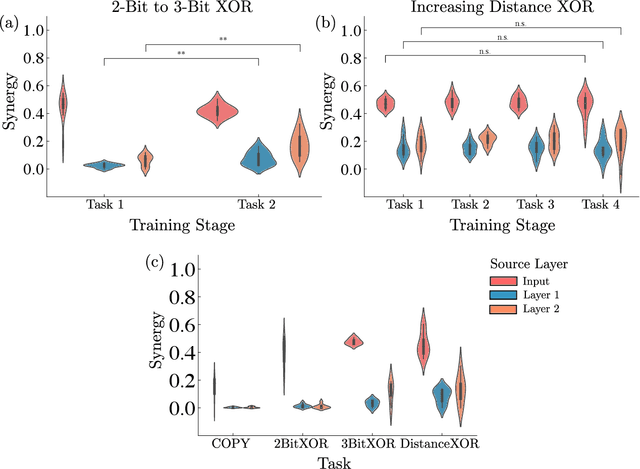
Striking progress has recently been made in understanding human cognition by analyzing how its neuronal underpinnings are engaged in different modes of information processing. Specifically, neural information can be decomposed into synergistic, redundant, and unique features, with synergistic components being particularly aligned with complex cognition. However, two fundamental questions remain unanswered: (a) precisely how and why a cognitive system can become highly synergistic; and (b) how these informational states map onto artificial neural networks in various learning modes. To address these questions, here we employ an information-decomposition framework to investigate the information processing strategies adopted by simple artificial neural networks performing a variety of cognitive tasks in both supervised and reinforcement learning settings. Our results show that synergy increases as neural networks learn multiple diverse tasks. Furthermore, performance in tasks requiring integration of multiple information sources critically relies on synergistic neurons. Finally, randomly turning off neurons during training through dropout increases network redundancy, corresponding to an increase in robustness. Overall, our results suggest that while redundant information is required for robustness to perturbations in the learning process, synergistic information is used to combine information from multiple modalities -- and more generally for flexible and efficient learning. These findings open the door to new ways of investigating how and why learning systems employ specific information-processing strategies, and support the principle that the capacity for general-purpose learning critically relies in the system's information dynamics.
Fixed $β$-VAE Encoding for Curious Exploration in Complex 3D Environments
May 18, 2021

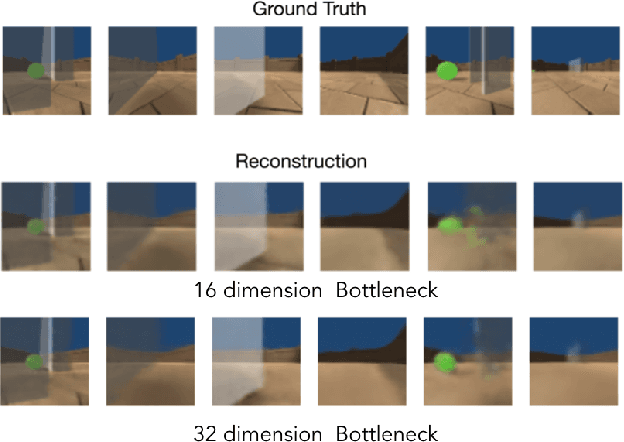
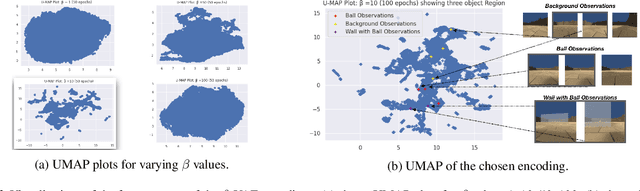
Curiosity is a general method for augmenting an environment reward with an intrinsic reward, which encourages exploration and is especially useful in sparse reward settings. As curiosity is calculated using next state prediction error, the type of state encoding used has a large impact on performance. Random features and inverse-dynamics features are generally preferred over VAEs based on previous results from Atari and other mostly 2D environments. However, unlike VAEs, they may not encode sufficient information for optimal behaviour, which becomes increasingly important as environments become more complex. In this paper, we use the sparse reward 3D physics environment Animal-AI, to demonstrate how a fixed $\beta$-VAE encoding can be used effectively with curiosity. We combine this with curriculum learning to solve the previously unsolved exploration intensive detour tasks while achieving 22\% gain in sample efficiency on the training curriculum against the next best encoding. We also corroborate the results on Atari Breakout, with our custom encoding outperforming random features and inverse-dynamics features.
Episodic Memory for Learning Subjective-Timescale Models
Oct 03, 2020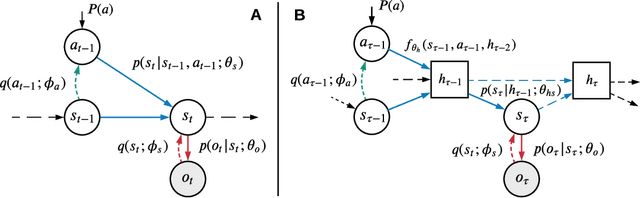
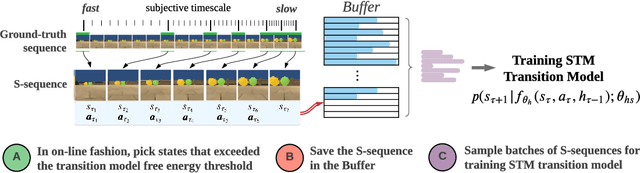
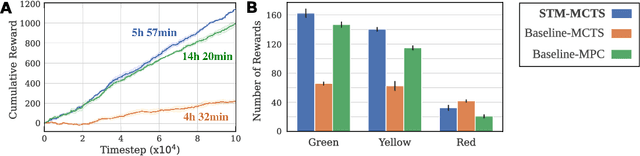
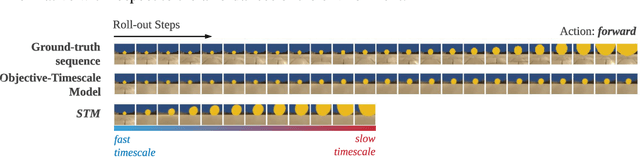
In model-based learning, an agent's model is commonly defined over transitions between consecutive states of an environment even though planning often requires reasoning over multi-step timescales, with intermediate states either unnecessary, or worse, accumulating prediction error. In contrast, intelligent behaviour in biological organisms is characterised by the ability to plan over varying temporal scales depending on the context. Inspired by the recent works on human time perception, we devise a novel approach to learning a transition dynamics model, based on the sequences of episodic memories that define the agent's subjective timescale - over which it learns world dynamics and over which future planning is performed. We implement this in the framework of active inference and demonstrate that the resulting subjective-timescale model (STM) can systematically vary the temporal extent of its predictions while preserving the same computational efficiency. Additionally, we show that STM predictions are more likely to introduce future salient events (for example new objects coming into view), incentivising exploration of new areas of the environment. As a result, STM produces more informative action-conditioned roll-outs that assist the agent in making better decisions. We validate significant improvement in our STM agent's performance in the Animal-AI environment against a baseline system, trained using the environment's objective-timescale dynamics.
The Animal-AI Environment: Training and Testing Animal-Like Artificial Cognition
Sep 18, 2019


Recent advances in artificial intelligence have been strongly driven by the use of game environments for training and evaluating agents. Games are often accessible and versatile, with well-defined state-transitions and goals allowing for intensive training and experimentation. However, agents trained in a particular environment are usually tested on the same or slightly varied distributions, and solutions do not necessarily imply any understanding. If we want AI systems that can model and understand their environment, we need environments that explicitly test for this. Inspired by the extensive literature on animal cognition, we present an environment that keeps all the positive elements of standard gaming environments, but is explicitly designed for the testing of animal-like artificial cognition.