 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy the Brain Consolidates: Predictive Forgetting for Optimal Generalisation
Mar 05, 2026Standard accounts of memory consolidation emphasise the stabilisation of stored representations, but struggle to explain representational drift, semanticisation, or the necessity of offline replay. Here we propose that high-capacity neocortical networks optimise stored representations for generalisation by reducing complexity via predictive forgetting, i.e. the selective retention of experienced information that predicts future outcomes or experience. We show that predictive forgetting formally improves information-theoretic generalisation bounds on stored representations. Under high-fidelity encoding constraints, such compression is generally unattainable in a single pass; high-capacity networks therefore benefit from temporally separated, iterative refinement of stored traces without re-accessing sensory input. We demonstrate this capacity dependence with simulations in autoencoder-based neocortical models, biologically plausible predictive coding circuits, and Transformer-based language models, and derive quantitative predictions for consolidation-dependent changes in neural representational geometry. These results identify a computational role for off-line consolidation beyond stabilisation, showing that outcome-conditioned compression optimises the retention-generalisation trade-off.
A Brain-like Synergistic Core in LLMs Drives Behaviour and Learning
Jan 11, 2026The independent evolution of intelligence in biological and artificial systems offers a unique opportunity to identify its fundamental computational principles. Here we show that large language models spontaneously develop synergistic cores -- components where information integration exceeds individual parts -- remarkably similar to those in the human brain. Using principles of information decomposition across multiple LLM model families and architectures, we find that areas in middle layers exhibit synergistic processing while early and late layers rely on redundancy, mirroring the informational organisation in biological brains. This organisation emerges through learning and is absent in randomly initialised networks. Crucially, ablating synergistic components causes disproportionate behavioural changes and performance loss, aligning with theoretical predictions about the fragility of synergy. Moreover, fine-tuning synergistic regions through reinforcement learning yields significantly greater performance gains than training redundant components, yet supervised fine-tuning shows no such advantage. This convergence suggests that synergistic information processing is a fundamental property of intelligence, providing targets for principled model design and testable predictions for biological intelligence.
Bottlenecked Transformers: Periodic KV Cache Abstraction for Generalised Reasoning
May 22, 2025Despite their impressive capabilities, Large Language Models struggle with generalisation beyond their training distribution, often exhibiting sophisticated pattern interpolation rather than true abstract reasoning (extrapolation). In this work, we approach this limitation through the lens of Information Bottleneck (IB) theory, which posits that model generalisation emerges from an optimal balance between input compression and retention of predictive information in latent representations. We prove using IB theory that decoder-only Transformers are inherently constrained in their ability to form task-optimal sequence representations. We then use this result to demonstrate that periodic global transformation of the internal sequence-level representations (KV cache) is a necessary computational step for improving Transformer generalisation in reasoning tasks. Based on these theoretical insights, we propose a modification to the Transformer architecture, in the form of an additional module that globally rewrites the KV cache at periodic intervals, shifting its capacity away from memorising input prefixes and toward encoding features most useful for predicting future tokens. Our model delivers substantial gains on mathematical reasoning benchmarks, outperforming both vanilla Transformers with up to 3.5x more parameters, as well as heuristic-driven pruning mechanisms for cache compression. Our approach can be seen as a principled generalisation of existing KV-cache compression methods; whereas such methods focus solely on compressing input representations, they often do so at the expense of retaining predictive information, and thus their capabilities are inherently bounded by those of an unconstrained model. This establishes a principled framework to manipulate Transformer memory using information theory, addressing fundamental reasoning limitations that scaling alone cannot overcome.
Human-like Episodic Memory for Infinite Context LLMs
Jul 12, 2024



Large language models (LLMs) have shown remarkable capabilities, but still struggle with processing extensive contexts, limiting their ability to maintain coherence and accuracy over long sequences. In contrast, the human brain excels at organising and retrieving episodic experiences across vast temporal scales, spanning a lifetime. In this work, we introduce EM-LLM, a novel approach that integrates key aspects of human episodic memory and event cognition into LLMs, enabling them to effectively handle practically infinite context lengths while maintaining computational efficiency. EM-LLM organises sequences of tokens into coherent episodic events using a combination of Bayesian surprise and graph-theoretic boundary refinement in an on-line fashion. When needed, these events are retrieved through a two-stage memory process, combining similarity-based and temporally contiguous retrieval for efficient and human-like access to relevant information. Experiments on the LongBench dataset demonstrate EM-LLM's superior performance, outperforming the state-of-the-art InfLLM model with an overall relative improvement of 4.3% across various tasks, including a 33% improvement on the PassageRetrieval task. Furthermore, our analysis reveals strong correlations between EM-LLM's event segmentation and human-perceived events, suggesting a bridge between this artificial system and its biological counterpart. This work not only advances LLM capabilities in processing extended contexts but also provides a computational framework for exploring human memory mechanisms, opening new avenues for interdisciplinary research in AI and cognitive science.
When in Doubt, Think Slow: Iterative Reasoning with Latent Imagination
Feb 23, 2024



In an unfamiliar setting, a model-based reinforcement learning agent can be limited by the accuracy of its world model. In this work, we present a novel, training-free approach to improving the performance of such agents separately from planning and learning. We do so by applying iterative inference at decision-time, to fine-tune the inferred agent states based on the coherence of future state representations. Our approach achieves a consistent improvement in both reconstruction accuracy and task performance when applied to visual 3D navigation tasks. We go on to show that considering more future states further improves the performance of the agent in partially-observable environments, but not in a fully-observable one. Finally, we demonstrate that agents with less training pre-evaluation benefit most from our approach.
Sample as You Infer: Predictive Coding With Langevin Dynamics
Nov 22, 2023



We present a novel algorithm for parameter learning in generic deep generative models that builds upon the predictive coding (PC) framework of computational neuroscience. Our approach modifies the standard PC algorithm to bring performance on-par and exceeding that obtained from standard variational auto-encoder (VAE) training. By injecting Gaussian noise into the PC inference procedure we re-envision it as an overdamped Langevin sampling, which facilitates optimisation with respect to a tight evidence lower bound (ELBO). We improve the resultant encoder-free training method by incorporating an encoder network to provide an amortised warm-start to our Langevin sampling and test three different objectives for doing so. Finally, to increase robustness to the sampling step size and reduce sensitivity to curvature, we validate a lightweight and easily computable form of preconditioning, inspired by Riemann Manifold Langevin and adaptive optimizers from the SGD literature. We compare against VAEs by training like-for-like generative models using our technique against those trained with standard reparameterisation-trick-based ELBOs. We observe our method out-performs or matches performance across a number of metrics, including sample quality, while converging in a fraction of the number of SGD training iterations.
Predictive Coding as a Neuromorphic Alternative to Backpropagation: A Critical Evaluation
Apr 05, 2023Backpropagation has rapidly become the workhorse credit assignment algorithm for modern deep learning methods. Recently, modified forms of predictive coding (PC), an algorithm with origins in computational neuroscience, have been shown to result in approximately or exactly equal parameter updates to those under backpropagation. Due to this connection, it has been suggested that PC can act as an alternative to backpropagation with desirable properties that may facilitate implementation in neuromorphic systems. Here, we explore these claims using the different contemporary PC variants proposed in the literature. We obtain time complexity bounds for these PC variants which we show are lower-bounded by backpropagation. We also present key properties of these variants that have implications for neurobiological plausibility and their interpretations, particularly from the perspective of standard PC as a variational Bayes algorithm for latent probabilistic models. Our findings shed new light on the connection between the two learning frameworks and suggest that, in its current forms, PC may have more limited potential as a direct replacement of backpropagation than previously envisioned.
Curvature-Sensitive Predictive Coding with Approximate Laplace Monte Carlo
Mar 09, 2023



Predictive coding (PC) accounts of perception now form one of the dominant computational theories of the brain, where they prescribe a general algorithm for inference and learning over hierarchical latent probabilistic models. Despite this, they have enjoyed little export to the broader field of machine learning, where comparative generative modelling techniques have flourished. In part, this has been due to the poor performance of models trained with PC when evaluated by both sample quality and marginal likelihood. By adopting the perspective of PC as a variational Bayes algorithm under the Laplace approximation, we identify the source of these deficits to lie in the exclusion of an associated Hessian term in the PC objective function, which would otherwise regularise the sharpness of the probability landscape and prevent over-certainty in the approximate posterior. To remedy this, we make three primary contributions: we begin by suggesting a simple Monte Carlo estimated evidence lower bound which relies on sampling from the Hessian-parameterised variational posterior. We then derive a novel block diagonal approximation to the full Hessian matrix that has lower memory requirements and favourable mathematical properties. Lastly, we present an algorithm that combines our method with standard PC to reduce memory complexity further. We evaluate models trained with our approach against the standard PC framework on image benchmark datasets. Our approach produces higher log-likelihoods and qualitatively better samples that more closely capture the diversity of the data-generating distribution.
Long-horizon video prediction using a dynamic latent hierarchy
Jan 09, 2023The task of video prediction and generation is known to be notoriously difficult, with the research in this area largely limited to short-term predictions. Though plagued with noise and stochasticity, videos consist of features that are organised in a spatiotemporal hierarchy, different features possessing different temporal dynamics. In this paper, we introduce Dynamic Latent Hierarchy (DLH) -- a deep hierarchical latent model that represents videos as a hierarchy of latent states that evolve over separate and fluid timescales. Each latent state is a mixture distribution with two components, representing the immediate past and the predicted future, causing the model to learn transitions only between sufficiently dissimilar states, while clustering temporally persistent states closer together. Using this unique property, DLH naturally discovers the spatiotemporal structure of a dataset and learns disentangled representations across its hierarchy. We hypothesise that this simplifies the task of modeling temporal dynamics of a video, improves the learning of long-term dependencies, and reduces error accumulation. As evidence, we demonstrate that DLH outperforms state-of-the-art benchmarks in video prediction, is able to better represent stochasticity, as well as to dynamically adjust its hierarchical and temporal structure. Our paper shows, among other things, how progress in representation learning can translate into progress in prediction tasks.
Modelling non-reinforced preferences using selective attention
Jul 25, 2022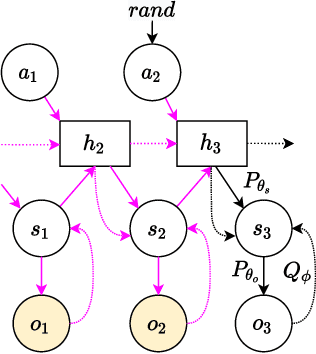
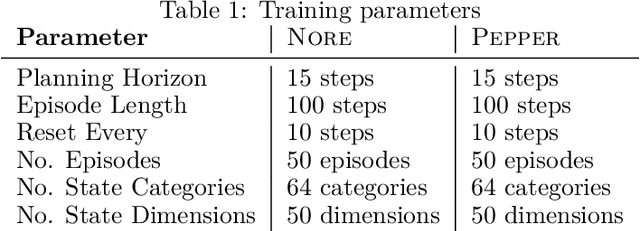
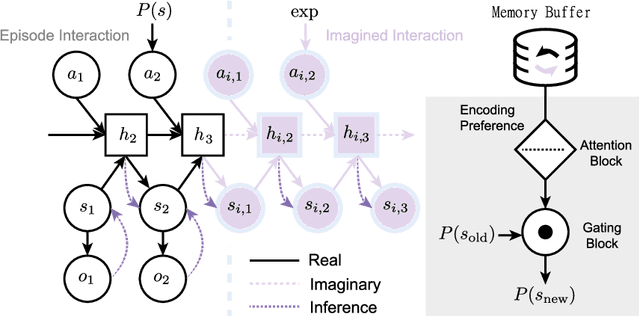
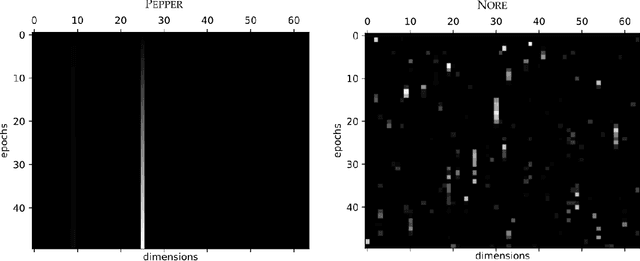
How can artificial agents learn non-reinforced preferences to continuously adapt their behaviour to a changing environment? We decompose this question into two challenges: ($i$) encoding diverse memories and ($ii$) selectively attending to these for preference formation. Our proposed \emph{no}n-\emph{re}inforced preference learning mechanism using selective attention, \textsc{Nore}, addresses both by leveraging the agent's world model to collect a diverse set of experiences which are interleaved with imagined roll-outs to encode memories. These memories are selectively attended to, using attention and gating blocks, to update agent's preferences. We validate \textsc{Nore} in a modified OpenAI Gym FrozenLake environment (without any external signal) with and without volatility under a fixed model of the environment -- and compare its behaviour to \textsc{Pepper}, a Hebbian preference learning mechanism. We demonstrate that \textsc{Nore} provides a straightforward framework to induce exploratory preferences in the absence of external signals.