 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel alignment using inter-modal bridges
May 18, 2025Foundation models have demonstrated remarkable performance across modalities such as language and vision. However, model reuse across distinct modalities (e.g., text and vision) remains limited due to the difficulty of aligning internal representations. Existing methods require extensive paired training data or are constrained to specific domains. We introduce a semi-supervised approach for model alignment via conditional flow matching. The conditional flow between latent spaces of different modalities (e.g., text-to-image or biological-to-artificial neuronal activity) can be learned in two settings: ($1$) solving a (balanced or unbalanced) optimal transport problem with an inter-space bridge cost, and ($2$) performing memory-efficient alignment using labelled exemplars. Despite being constrained by the original models' capacity, our method--under both settings--matches downstream task performance of end-to-end trained models on object recognition and image generation tasks across MNIST, ImageNet, and \cite{majaj2015simple} datasets, particularly when labelled training data is scarce ($<20\%$). Our method provides a data-efficient solution for inter-modal model alignment with minimal supervision.
Active Inference as a Model of Agency
Jan 23, 2024



Is there a canonical way to think of agency beyond reward maximisation? In this paper, we show that any type of behaviour complying with physically sound assumptions about how macroscopic biological agents interact with the world canonically integrates exploration and exploitation in the sense of minimising risk and ambiguity about states of the world. This description, known as active inference, refines the free energy principle, a popular descriptive framework for action and perception originating in neuroscience. Active inference provides a normative Bayesian framework to simulate and model agency that is widely used in behavioural neuroscience, reinforcement learning (RL) and robotics. The usefulness of active inference for RL is three-fold. \emph{a}) Active inference provides a principled solution to the exploration-exploitation dilemma that usefully simulates biological agency. \emph{b}) It provides an explainable recipe to simulate behaviour, whence behaviour follows as an explainable mixture of exploration and exploitation under a generative world model, and all differences in behaviour are explicit in differences in world model. \emph{c}) This framework is universal in the sense that it is theoretically possible to rewrite any RL algorithm conforming to the descriptive assumptions of active inference as an active inference algorithm. Thus, active inference can be used as a tool to uncover and compare the commitments and assumptions of more specific models of agency.
Supervised structure learning
Nov 17, 2023



This paper concerns structure learning or discovery of discrete generative models. It focuses on Bayesian model selection and the assimilation of training data or content, with a special emphasis on the order in which data are ingested. A key move - in the ensuing schemes - is to place priors on the selection of models, based upon expected free energy. In this setting, expected free energy reduces to a constrained mutual information, where the constraints inherit from priors over outcomes (i.e., preferred outcomes). The resulting scheme is first used to perform image classification on the MNIST dataset to illustrate the basic idea, and then tested on a more challenging problem of discovering models with dynamics, using a simple sprite-based visual disentanglement paradigm and the Tower of Hanoi (cf., blocks world) problem. In these examples, generative models are constructed autodidactically to recover (i.e., disentangle) the factorial structure of latent states - and their characteristic paths or dynamics.
Hierarchical generative modelling for autonomous robots
Aug 15, 2023



Humans can produce complex whole-body motions when interacting with their surroundings, by planning, executing and combining individual limb movements. We investigated this fundamental aspect of motor control in the setting of autonomous robotic operations. We approach this problem by hierarchical generative modelling equipped with multi-level planning-for autonomous task completion-that mimics the deep temporal architecture of human motor control. Here, temporal depth refers to the nested time scales at which successive levels of a forward or generative model unfold, for example, delivering an object requires a global plan to contextualise the fast coordination of multiple local movements of limbs. This separation of temporal scales also motivates robotics and control. Specifically, to achieve versatile sensorimotor control, it is advantageous to hierarchically structure the planning and low-level motor control of individual limbs. We use numerical and physical simulation to conduct experiments and to establish the efficacy of this formulation. Using a hierarchical generative model, we show how a humanoid robot can autonomously complete a complex task that necessitates a holistic use of locomotion, manipulation, and grasping. Specifically, we demonstrate the ability of a humanoid robot that can retrieve and transport a box, open and walk through a door to reach the destination, approach and kick a football, while showing robust performance in presence of body damage and ground irregularities. Our findings demonstrated the effectiveness of using human-inspired motor control algorithms, and our method provides a viable hierarchical architecture for the autonomous completion of challenging goal-directed tasks.
On efficient computation in active inference
Jul 02, 2023



Despite being recognized as neurobiologically plausible, active inference faces difficulties when employed to simulate intelligent behaviour in complex environments due to its computational cost and the difficulty of specifying an appropriate target distribution for the agent. This paper introduces two solutions that work in concert to address these limitations. First, we present a novel planning algorithm for finite temporal horizons with drastically lower computational complexity. Second, inspired by Z-learning from control theory literature, we simplify the process of setting an appropriate target distribution for new and existing active inference planning schemes. Our first approach leverages the dynamic programming algorithm, known for its computational efficiency, to minimize the cost function used in planning through the Bellman-optimality principle. Accordingly, our algorithm recursively assesses the expected free energy of actions in the reverse temporal order. This improves computational efficiency by orders of magnitude and allows precise model learning and planning, even under uncertain conditions. Our method simplifies the planning process and shows meaningful behaviour even when specifying only the agent's final goal state. The proposed solutions make defining a target distribution from a goal state straightforward compared to the more complicated task of defining a temporally informed target distribution. The effectiveness of these methods is tested and demonstrated through simulations in standard grid-world tasks. These advances create new opportunities for various applications.
Modelling non-reinforced preferences using selective attention
Jul 25, 2022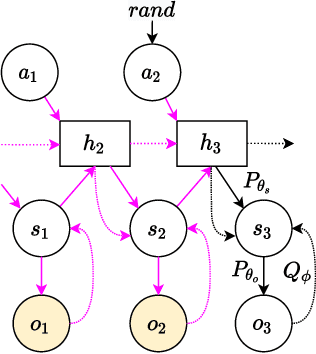
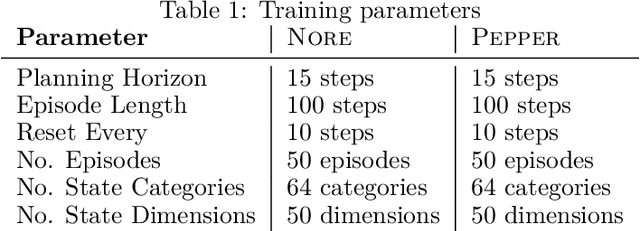
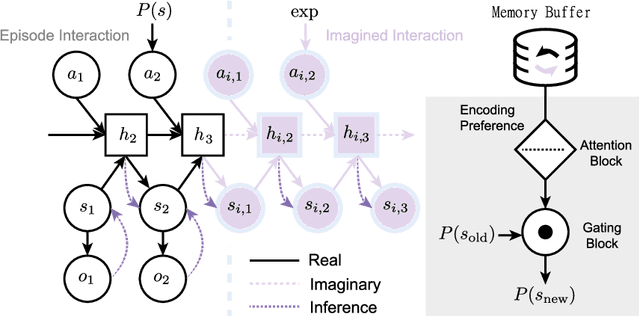
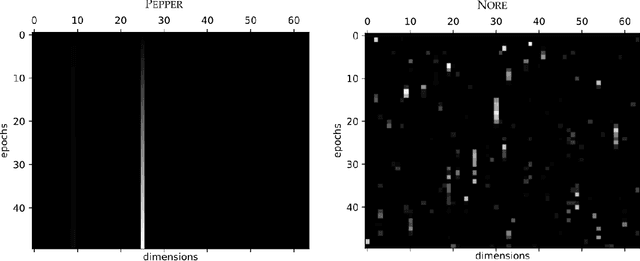
How can artificial agents learn non-reinforced preferences to continuously adapt their behaviour to a changing environment? We decompose this question into two challenges: ($i$) encoding diverse memories and ($ii$) selectively attending to these for preference formation. Our proposed \emph{no}n-\emph{re}inforced preference learning mechanism using selective attention, \textsc{Nore}, addresses both by leveraging the agent's world model to collect a diverse set of experiences which are interleaved with imagined roll-outs to encode memories. These memories are selectively attended to, using attention and gating blocks, to update agent's preferences. We validate \textsc{Nore} in a modified OpenAI Gym FrozenLake environment (without any external signal) with and without volatility under a fixed model of the environment -- and compare its behaviour to \textsc{Pepper}, a Hebbian preference learning mechanism. We demonstrate that \textsc{Nore} provides a straightforward framework to induce exploratory preferences in the absence of external signals.
Reclaiming saliency: rhythmic precision-modulated action and perception
Mar 23, 2022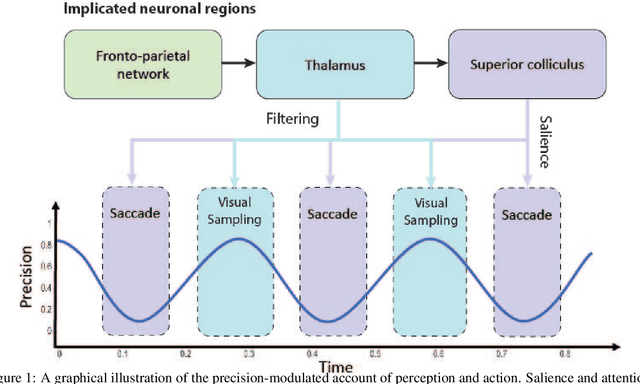
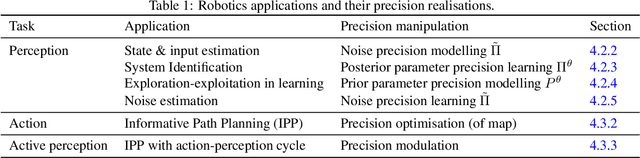

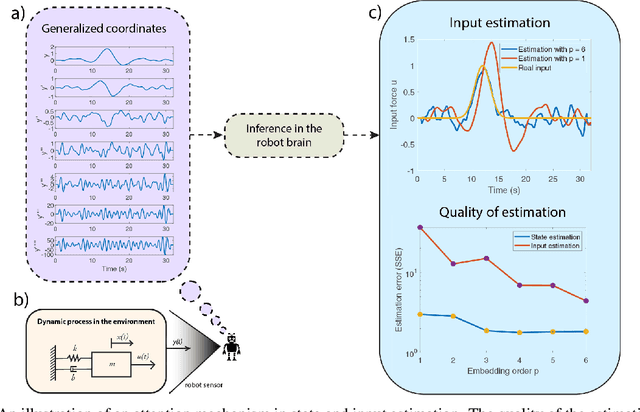
Computational models of visual attention in artificial intelligence and robotics have been inspired by the concept of a saliency map. These models account for the mutual information between the (current) visual information and its estimated causes. However, they fail to consider the circular causality between perception and action. In other words, they do not consider where to sample next, given current beliefs. Here, we reclaim salience as an active inference process that relies on two basic principles: uncertainty minimisation and rhythmic scheduling. For this, we make a distinction between attention and salience. Briefly, we associate attention with precision control, i.e., the confidence with which beliefs can be updated given sampled sensory data, and salience with uncertainty minimisation that underwrites the selection of future sensory data. Using this, we propose a new account of attention based on rhythmic precision-modulation and discuss its potential in robotics, providing numerical experiments that showcase advantages of precision-modulation for state and noise estimation, system identification and action selection for informative path planning.
Active inference, Bayesian optimal design, and expected utility
Sep 21, 2021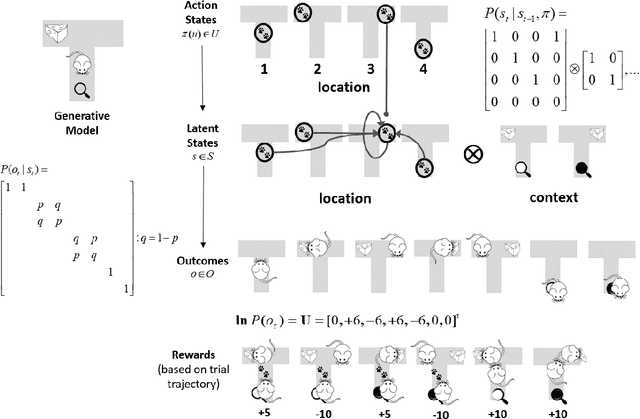
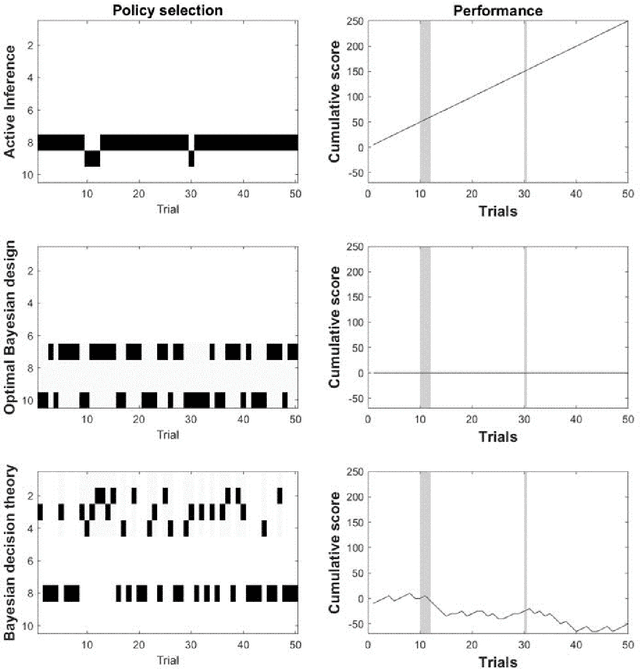
Active inference, a corollary of the free energy principle, is a formal way of describing the behavior of certain kinds of random dynamical systems that have the appearance of sentience. In this chapter, we describe how active inference combines Bayesian decision theory and optimal Bayesian design principles under a single imperative to minimize expected free energy. It is this aspect of active inference that allows for the natural emergence of information-seeking behavior. When removing prior outcomes preferences from expected free energy, active inference reduces to optimal Bayesian design, i.e., information gain maximization. Conversely, active inference reduces to Bayesian decision theory in the absence of ambiguity and relative risk, i.e., expected utility maximization. Using these limiting cases, we illustrate how behaviors differ when agents select actions that optimize expected utility, expected information gain, and expected free energy. Our T-maze simulations show optimizing expected free energy produces goal-directed information-seeking behavior while optimizing expected utility induces purely exploitive behavior and maximizing information gain engenders intrinsically motivated behavior.
Active Inference for Stochastic Control
Aug 27, 2021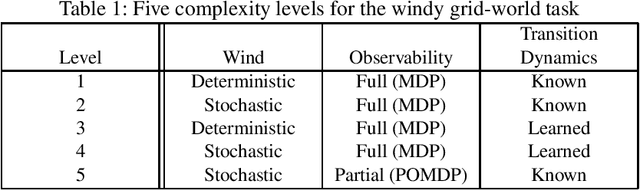
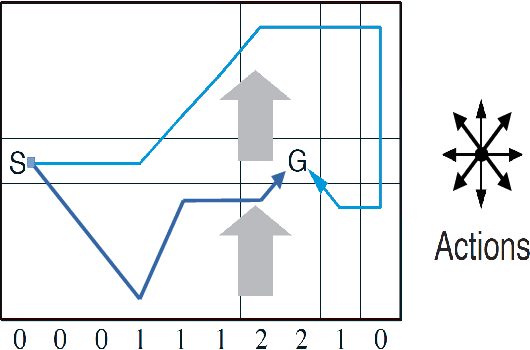

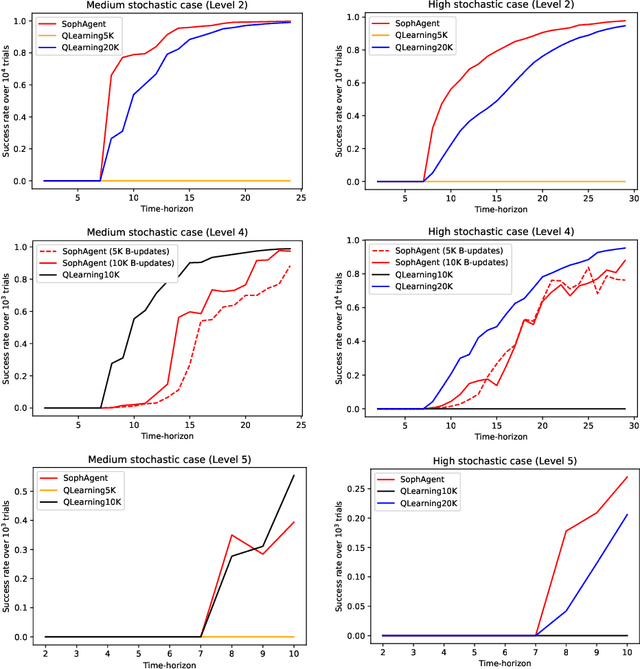
Active inference has emerged as an alternative approach to control problems given its intuitive (probabilistic) formalism. However, despite its theoretical utility, computational implementations have largely been restricted to low-dimensional, deterministic settings. This paper highlights that this is a consequence of the inability to adequately model stochastic transition dynamics, particularly when an extensive policy (i.e., action trajectory) space must be evaluated during planning. Fortunately, recent advancements propose a modified planning algorithm for finite temporal horizons. We build upon this work to assess the utility of active inference for a stochastic control setting. For this, we simulate the classic windy grid-world task with additional complexities, namely: 1) environment stochasticity; 2) learning of transition dynamics; and 3) partial observability. Our results demonstrate the advantage of using active inference, compared to reinforcement learning, in both deterministic and stochastic settings.
Bayesian brains and the Rényi divergence
Jul 12, 2021
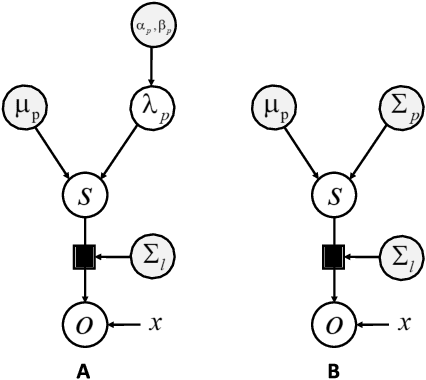
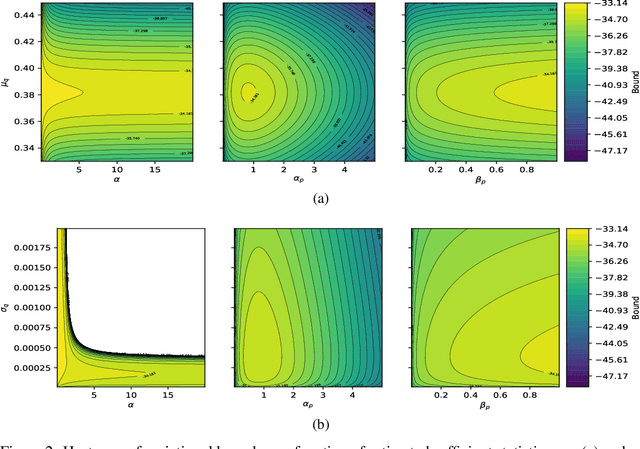
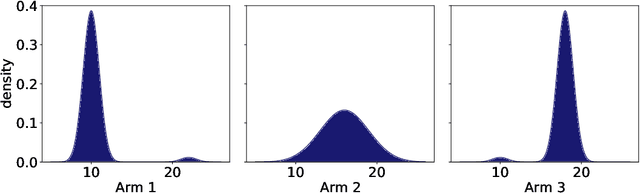
Under the Bayesian brain hypothesis, behavioural variations can be attributed to different priors over generative model parameters. This provides a formal explanation for why individuals exhibit inconsistent behavioural preferences when confronted with similar choices. For example, greedy preferences are a consequence of confident (or precise) beliefs over certain outcomes. Here, we offer an alternative account of behavioural variability using R\'enyi divergences and their associated variational bounds. R\'enyi bounds are analogous to the variational free energy (or evidence lower bound) and can be derived under the same assumptions. Importantly, these bounds provide a formal way to establish behavioural differences through an $\alpha$ parameter, given fixed priors. This rests on changes in $\alpha$ that alter the bound (on a continuous scale), inducing different posterior estimates and consequent variations in behaviour. Thus, it looks as if individuals have different priors, and have reached different conclusions. More specifically, $\alpha \to 0^{+}$ optimisation leads to mass-covering variational estimates and increased variability in choice behaviour. Furthermore, $\alpha \to + \infty$ optimisation leads to mass-seeking variational posteriors and greedy preferences. We exemplify this formulation through simulations of the multi-armed bandit task. We note that these $\alpha$ parameterisations may be especially relevant, i.e., shape preferences, when the true posterior is not in the same family of distributions as the assumed (simpler) approximate density, which may be the case in many real-world scenarios. The ensuing departure from vanilla variational inference provides a potentially useful explanation for differences in behavioural preferences of biological (or artificial) agents under the assumption that the brain performs variational Bayesian inference.