 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment to Focus: Guiding Latent Action Models in the Presence of Distractors
Feb 02, 2026Latent Action Models (LAMs) learn to extract action-relevant representations solely from raw observations, enabling reinforcement learning from unlabelled videos and significantly scaling available training data. However, LAMs face a critical challenge in disentangling action-relevant features from action-correlated noise (e.g., background motion). Failing to filter these distractors causes LAMs to capture spurious correlations and build sub-optimal latent action spaces. In this paper, we introduce MaskLAM -- a lightweight modification to LAM training to mitigate this issue by incorporating visual agent segmentation. MaskLAM utilises segmentation masks from pretrained foundation models to weight the LAM reconstruction loss, thereby prioritising salient information over background elements while requiring no architectural modifications. We demonstrate the effectiveness of our method on continuous-control MuJoCo tasks, modified with action-correlated background noise. Our approach yields up to a 4x increase in accrued rewards compared to standard baselines and a 3x improvement in the latent action quality, as evidenced by linear probe evaluation.
The impact of deep learning aid on the workload and interpretation accuracy of radiologists on chest computed tomography: a cross-over reader study
Jun 12, 2024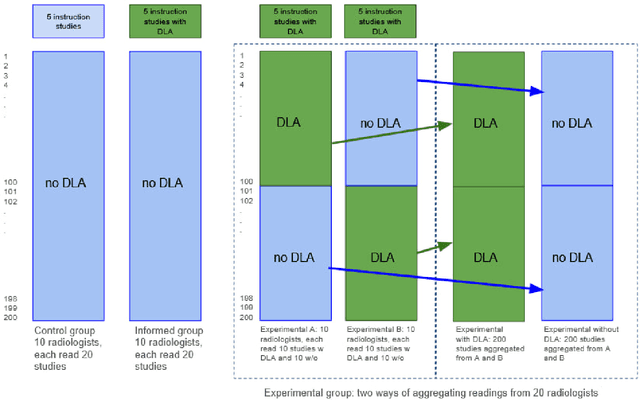
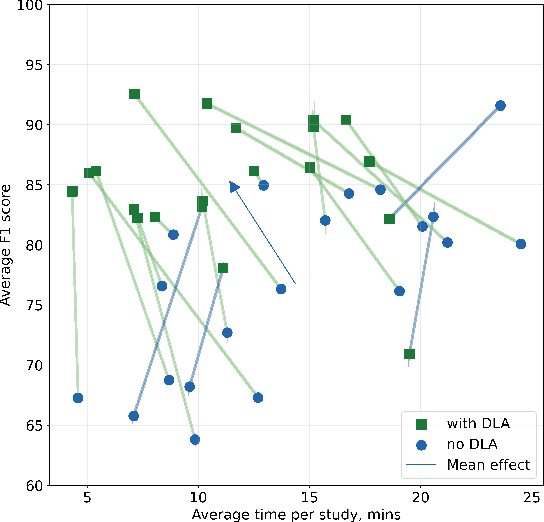
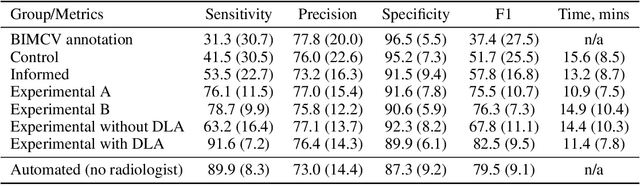
Interpretation of chest computed tomography (CT) is time-consuming. Previous studies have measured the time-saving effect of using a deep-learning-based aid (DLA) for CT interpretation. We evaluated the joint impact of a multi-pathology DLA on the time and accuracy of radiologists' reading. 40 radiologists were randomly split into three experimental arms: control (10), who interpret studies without assistance; informed group (10), who were briefed about DLA pathologies, but performed readings without it; and the experimental group (20), who interpreted half studies with DLA, and half without. Every arm used the same 200 CT studies retrospectively collected from BIMCV-COVID19 dataset; each radiologist provided readings for 20 CT studies. We compared interpretation time, and accuracy of participants diagnostic report with respect to 12 pathological findings. Mean reading time per study was 15.6 minutes [SD 8.5] in the control arm, 13.2 minutes [SD 8.7] in the informed arm, 14.4 [SD 10.3] in the experimental arm without DLA, and 11.4 minutes [SD 7.8] in the experimental arm with DLA. Mean sensitivity and specificity were 41.5 [SD 30.4], 86.8 [SD 28.3] in the control arm; 53.5 [SD 22.7], 92.3 [SD 9.4] in the informed non-assisted arm; 63.2 [SD 16.4], 92.3 [SD 8.2] in the experimental arm without DLA; and 91.6 [SD 7.2], 89.9 [SD 6.0] in the experimental arm with DLA. DLA speed up interpretation time per study by 2.9 minutes (CI95 [1.7, 4.3], p<0.0005), increased sensitivity by 28.4 (CI95 [23.4, 33.4], p<0.0005), and decreased specificity by 2.4 (CI95 [0.6, 4.3], p=0.13). Of 20 radiologists in the experimental arm, 16 have improved reading time and sensitivity, two improved their time with a marginal drop in sensitivity, and two participants improved sensitivity with increased time. Overall, DLA introduction decreased reading time by 20.6%.
Long-horizon video prediction using a dynamic latent hierarchy
Jan 09, 2023The task of video prediction and generation is known to be notoriously difficult, with the research in this area largely limited to short-term predictions. Though plagued with noise and stochasticity, videos consist of features that are organised in a spatiotemporal hierarchy, different features possessing different temporal dynamics. In this paper, we introduce Dynamic Latent Hierarchy (DLH) -- a deep hierarchical latent model that represents videos as a hierarchy of latent states that evolve over separate and fluid timescales. Each latent state is a mixture distribution with two components, representing the immediate past and the predicted future, causing the model to learn transitions only between sufficiently dissimilar states, while clustering temporally persistent states closer together. Using this unique property, DLH naturally discovers the spatiotemporal structure of a dataset and learns disentangled representations across its hierarchy. We hypothesise that this simplifies the task of modeling temporal dynamics of a video, improves the learning of long-term dependencies, and reduces error accumulation. As evidence, we demonstrate that DLH outperforms state-of-the-art benchmarks in video prediction, is able to better represent stochasticity, as well as to dynamically adjust its hierarchical and temporal structure. Our paper shows, among other things, how progress in representation learning can translate into progress in prediction tasks.
Modelling non-reinforced preferences using selective attention
Jul 25, 2022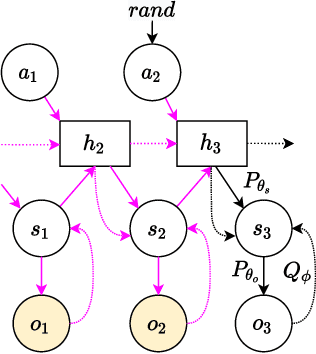
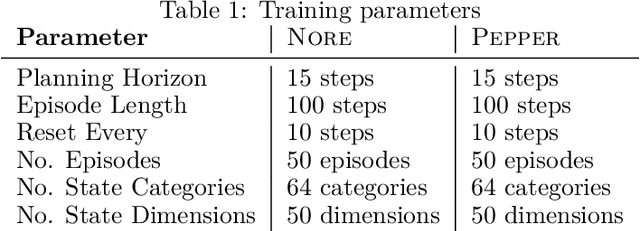
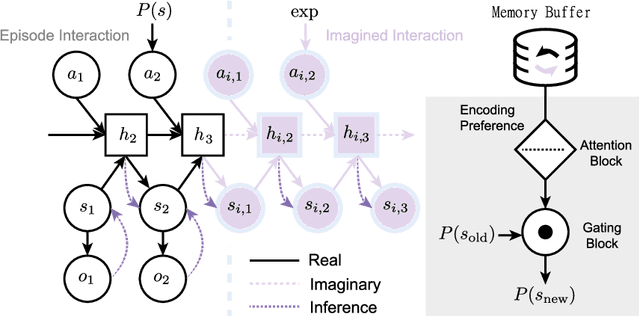
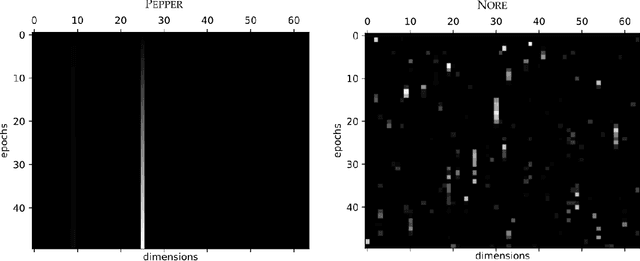
How can artificial agents learn non-reinforced preferences to continuously adapt their behaviour to a changing environment? We decompose this question into two challenges: ($i$) encoding diverse memories and ($ii$) selectively attending to these for preference formation. Our proposed \emph{no}n-\emph{re}inforced preference learning mechanism using selective attention, \textsc{Nore}, addresses both by leveraging the agent's world model to collect a diverse set of experiences which are interleaved with imagined roll-outs to encode memories. These memories are selectively attended to, using attention and gating blocks, to update agent's preferences. We validate \textsc{Nore} in a modified OpenAI Gym FrozenLake environment (without any external signal) with and without volatility under a fixed model of the environment -- and compare its behaviour to \textsc{Pepper}, a Hebbian preference learning mechanism. We demonstrate that \textsc{Nore} provides a straightforward framework to induce exploratory preferences in the absence of external signals.
Interpretable Vertebral Fracture Quantification via Anchor-Free Landmarks Localization
Apr 14, 2022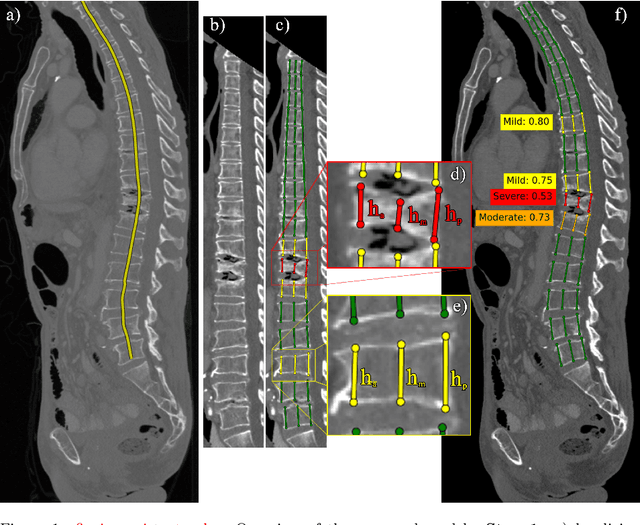
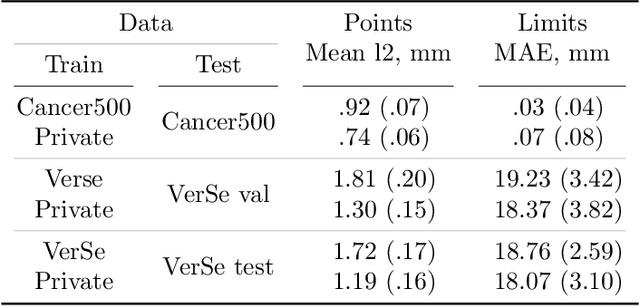
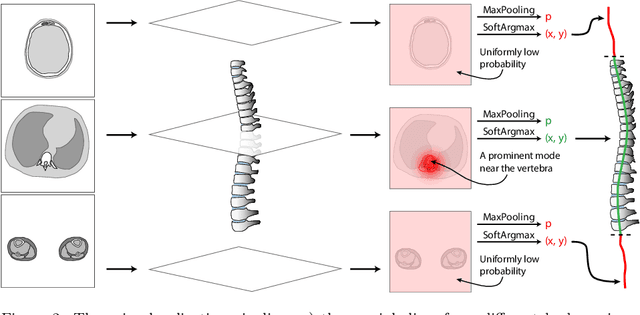
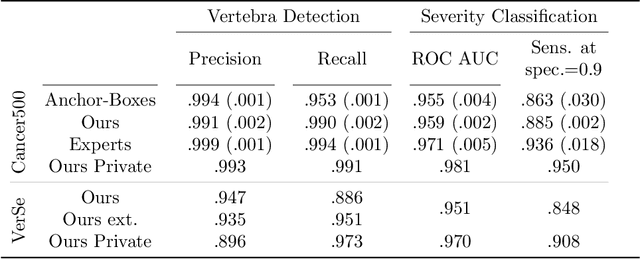
Vertebral body compression fractures are early signs of osteoporosis. Though these fractures are visible on Computed Tomography (CT) images, they are frequently missed by radiologists in clinical settings. Prior research on automatic methods of vertebral fracture classification proves its reliable quality; however, existing methods provide hard-to-interpret outputs and sometimes fail to process cases with severe abnormalities such as highly pathological vertebrae or scoliosis. We propose a new two-step algorithm to localize the vertebral column in 3D CT images and then detect individual vertebrae and quantify fractures in 2D simultaneously. We train neural networks for both steps using a simple 6-keypoints based annotation scheme, which corresponds precisely to the current clinical recommendation. Our algorithm has no exclusion criteria, processes 3D CT in 2 seconds on a single GPU, and provides an interpretable and verifiable output. The method approaches expert-level performance and demonstrates state-of-the-art results in vertebrae 3D localization (the average error is 1 mm), vertebrae 2D detection (precision and recall are 0.99), and fracture identification (ROC AUC at the patient level is up to 0.96). Our anchor-free vertebra detection network shows excellent generalizability on a new domain by achieving ROC AUC 0.95, sensitivity 0.85, specificity 0.9 on a challenging VerSe dataset with many unseen vertebra types.
Bayesian sense of time in biological and artificial brains
Jan 14, 2022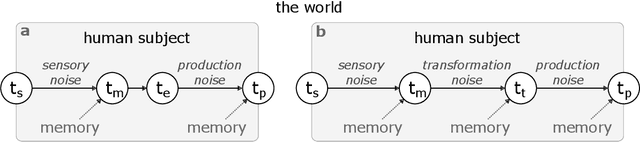
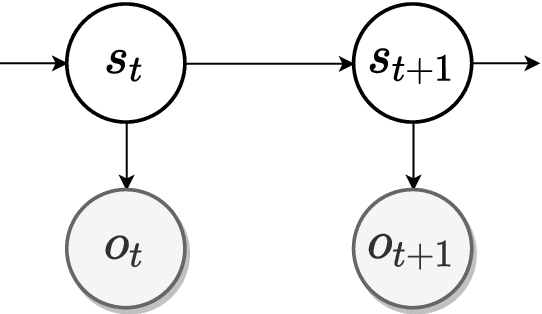
Enquiries concerning the underlying mechanisms and the emergent properties of a biological brain have a long history of theoretical postulates and experimental findings. Today, the scientific community tends to converge to a single interpretation of the brain's cognitive underpinnings -- that it is a Bayesian inference machine. This contemporary view has naturally been a strong driving force in recent developments around computational and cognitive neurosciences. Of particular interest is the brain's ability to process the passage of time -- one of the fundamental dimensions of our experience. How can we explain empirical data on human time perception using the Bayesian brain hypothesis? Can we replicate human estimation biases using Bayesian models? What insights can the agent-based machine learning models provide for the study of this subject? In this chapter, we review some of the recent advancements in the field of time perception and discuss the role of Bayesian processing in the construction of temporal models.
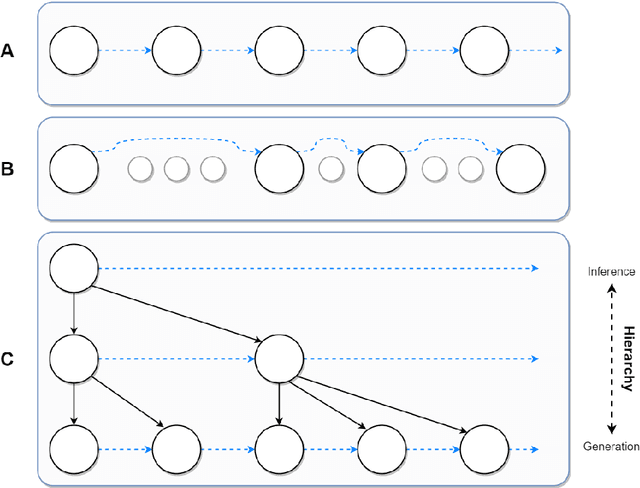
Variational Predictive Routing with Nested Subjective Timescales
Oct 21, 2021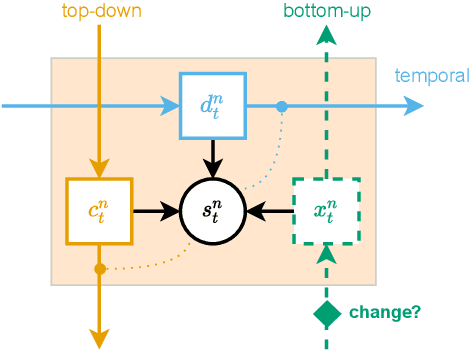
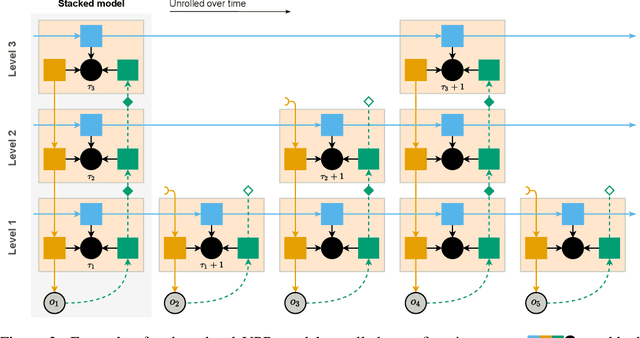
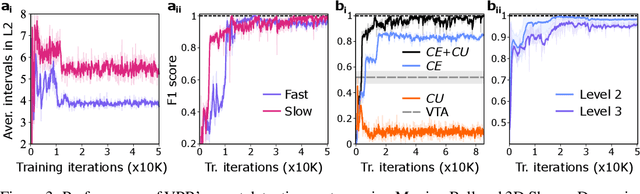
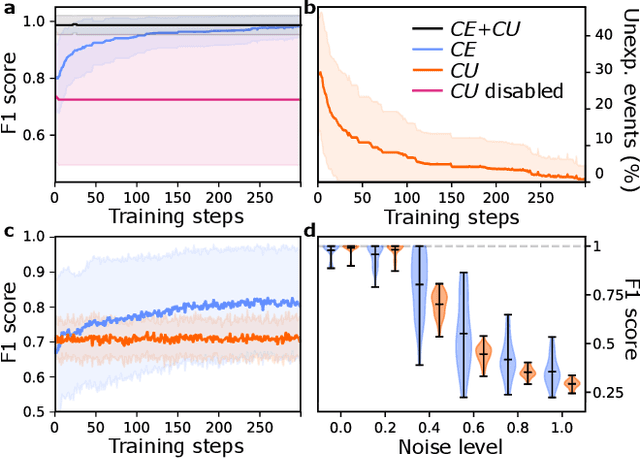
Discovery and learning of an underlying spatiotemporal hierarchy in sequential data is an important topic for machine learning. Despite this, little work has been done to explore hierarchical generative models that can flexibly adapt their layerwise representations in response to datasets with different temporal dynamics. Here, we present Variational Predictive Routing (VPR) - a neural probabilistic inference system that organizes latent representations of video features in a temporal hierarchy, based on their rates of change, thus modeling continuous data as a hierarchical renewal process. By employing an event detection mechanism that relies solely on the system's latent representations (without the need of a separate model), VPR is able to dynamically adjust its internal state following changes in the observed features, promoting an optimal organisation of representations across the levels of the model's latent hierarchy. Using several video datasets, we show that VPR is able to detect event boundaries, disentangle spatiotemporal features across its hierarchy, adapt to the dynamics of the data, and produce accurate time-agnostic rollouts of the future. Our approach integrates insights from neuroscience and introduces a framework with high potential for applications in model-based reinforcement learning, where flexible and informative state-space rollouts are of particular interest.
Exploration and preference satisfaction trade-off in reward-free learning
Jun 08, 2021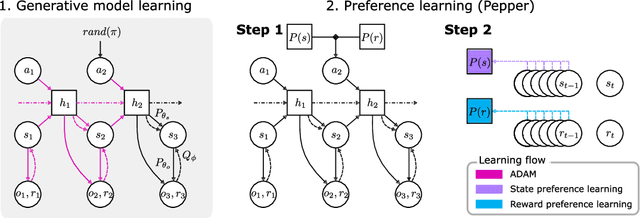

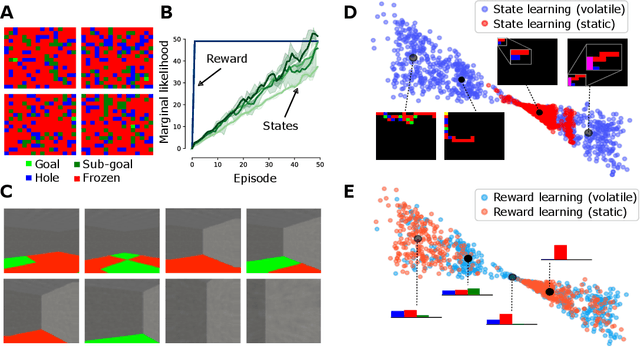

Biological agents have meaningful interactions with their environment despite the absence of a reward signal. In such instances, the agent can learn preferred modes of behaviour that lead to predictable states -- necessary for survival. In this paper, we pursue the notion that this learnt behaviour can be a consequence of reward-free preference learning that ensures an appropriate trade-off between exploration and preference satisfaction. For this, we introduce a model-based Bayesian agent equipped with a preference learning mechanism (pepper) using conjugate priors. These conjugate priors are used to augment the expected free energy planner for learning preferences over states (or outcomes) across time. Importantly, our approach enables the agent to learn preferences that encourage adaptive behaviour at test time. We illustrate this in the OpenAI Gym FrozenLake and the 3D mini-world environments -- with and without volatility. Given a constant environment, these agents learn confident (i.e., precise) preferences and act to satisfy them. Conversely, in a volatile setting, perpetual preference uncertainty maintains exploratory behaviour. Our experiments suggest that learnable (reward-free) preferences entail a trade-off between exploration and preference satisfaction. Pepper offers a straightforward framework suitable for designing adaptive agents when reward functions cannot be predefined as in real environments.
Episodic Memory for Learning Subjective-Timescale Models
Oct 03, 2020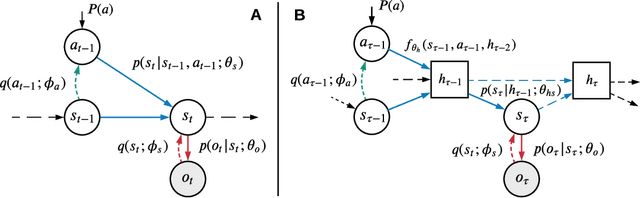
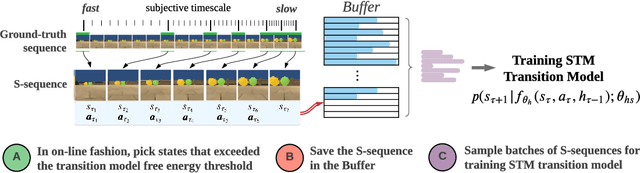
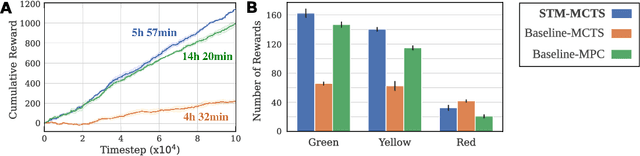
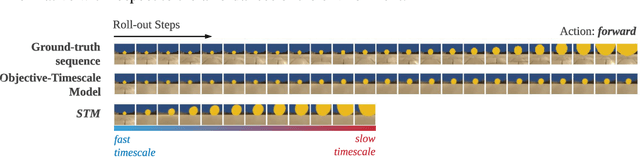
In model-based learning, an agent's model is commonly defined over transitions between consecutive states of an environment even though planning often requires reasoning over multi-step timescales, with intermediate states either unnecessary, or worse, accumulating prediction error. In contrast, intelligent behaviour in biological organisms is characterised by the ability to plan over varying temporal scales depending on the context. Inspired by the recent works on human time perception, we devise a novel approach to learning a transition dynamics model, based on the sequences of episodic memories that define the agent's subjective timescale - over which it learns world dynamics and over which future planning is performed. We implement this in the framework of active inference and demonstrate that the resulting subjective-timescale model (STM) can systematically vary the temporal extent of its predictions while preserving the same computational efficiency. Additionally, we show that STM predictions are more likely to introduce future salient events (for example new objects coming into view), incentivising exploration of new areas of the environment. As a result, STM produces more informative action-conditioned roll-outs that assist the agent in making better decisions. We validate significant improvement in our STM agent's performance in the Animal-AI environment against a baseline system, trained using the environment's objective-timescale dynamics.
Geometric Deep Learning for Post-Menstrual Age Prediction based on the Neonatal White Matter Cortical Surface
Aug 13, 2020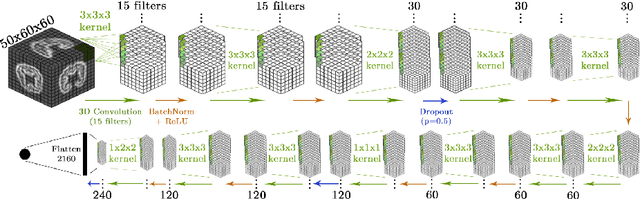
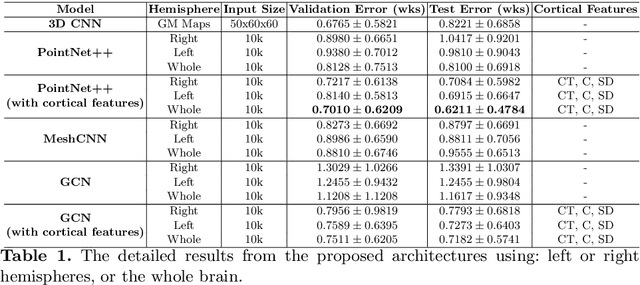

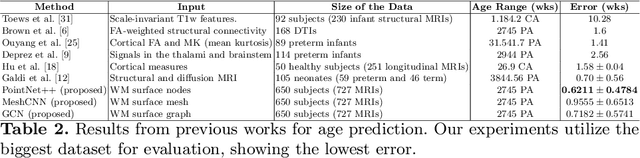
Accurate estimation of the age in neonates is essential for measuring neurodevelopmental, medical, and growth outcomes. In this paper, we propose a novel approach to predict the post-menstrual age (PA) at scan, using techniques from geometric deep learning, based on the neonatal white matter cortical surface. We utilize and compare multiple specialized neural network architectures that predict the age using different geometric representations of the cortical surface; we compare MeshCNN, Pointnet++, GraphCNN, and a volumetric benchmark. The dataset is part of the Developing Human Connectome Project (dHCP), and is a cohort of healthy and premature neonates. We evaluate our approach on 650 subjects (727scans) with PA ranging from 27 to 45 weeks. Our results show accurate prediction of the estimated PA, with mean error less than one week.