 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning under Noisy Temporal Self-Supervision for Colonoscopy Videos
May 12, 2026Learning robust representations of polyp tracklets is key to enabling multiple AI-assisted colonoscopy applications, from polyp characterization to automated reporting and retrieval. Supervised contrastive learning is an effective approach for learning such representations, but it typically relies on correct positive and negative definitions. Collecting these labels requires linking tracklets that depict the same underlying polyp entity throughout the video, which is costly and demands specialized clinical expertise. In this work, we leverage the sequential workflow of colonoscopy procedures to derive self-supervised associations from temporal structure. Since temporally derived associations are not guaranteed to be correct, we introduce a noise-aware contrastive loss to account for noisy associations. We demonstrate the effectiveness of the learned representations across multiple downstream tasks, including polyp retrieval and re-identification, size estimation, and histology classification. Our method outperforms prior self-supervised and supervised baselines, and matches or exceeds recent foundation models across all tasks, using a lightweight encoder trained on only 27 videos. Code is available at https://github.com/lparolari/ntssl.
Self-Supervision Enhances Instance-based Multiple Instance Learning Methods in Digital Pathology: A Benchmark Study
May 02, 2025Multiple Instance Learning (MIL) has emerged as the best solution for Whole Slide Image (WSI) classification. It consists of dividing each slide into patches, which are treated as a bag of instances labeled with a global label. MIL includes two main approaches: instance-based and embedding-based. In the former, each patch is classified independently, and then the patch scores are aggregated to predict the bag label. In the latter, bag classification is performed after aggregating patch embeddings. Even if instance-based methods are naturally more interpretable, embedding-based MILs have usually been preferred in the past due to their robustness to poor feature extractors. However, recently, the quality of feature embeddings has drastically increased using self-supervised learning (SSL). Nevertheless, many authors continue to endorse the superiority of embedding-based MIL. To investigate this further, we conduct 710 experiments across 4 datasets, comparing 10 MIL strategies, 6 self-supervised methods with 4 backbones, 4 foundation models, and various pathology-adapted techniques. Furthermore, we introduce 4 instance-based MIL methods never used before in the pathology domain. Through these extensive experiments, we show that with a good SSL feature extractor, simple instance-based MILs, with very few parameters, obtain similar or better performance than complex, state-of-the-art (SOTA) embedding-based MIL methods, setting new SOTA results on the BRACS and Camelyon16 datasets. Since simple instance-based MIL methods are naturally more interpretable and explainable to clinicians, our results suggest that more effort should be put into well-adapted SSL methods for WSI rather than into complex embedding-based MIL methods.
Dense Self-Supervised Learning for Medical Image Segmentation
Jul 29, 2024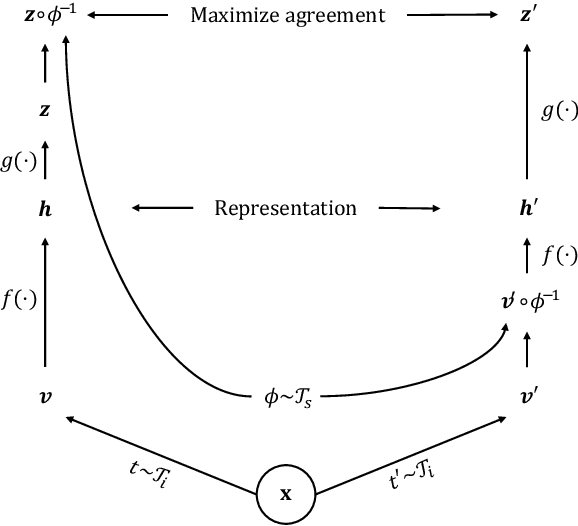

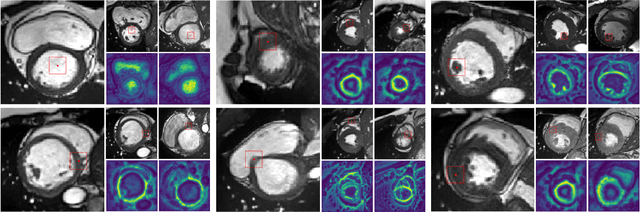

Deep learning has revolutionized medical image segmentation, but it relies heavily on high-quality annotations. The time, cost and expertise required to label images at the pixel-level for each new task has slowed down widespread adoption of the paradigm. We propose Pix2Rep, a self-supervised learning (SSL) approach for few-shot segmentation, that reduces the manual annotation burden by learning powerful pixel-level representations directly from unlabeled images. Pix2Rep is a novel pixel-level loss and pre-training paradigm for contrastive SSL on whole images. It is applied to generic encoder-decoder deep learning backbones (e.g., U-Net). Whereas most SSL methods enforce invariance of the learned image-level representations under intensity and spatial image augmentations, Pix2Rep enforces equivariance of the pixel-level representations. We demonstrate the framework on a task of cardiac MRI segmentation. Results show improved performance compared to existing semi- and self-supervised approaches; and a 5-fold reduction in the annotation burden for equivalent performance versus a fully supervised U-Net baseline. This includes a 30% (resp. 31%) DICE improvement for one-shot segmentation under linear-probing (resp. fine-tuning). Finally, we also integrate the novel Pix2Rep concept with the Barlow Twins non-contrastive SSL, which leads to even better segmentation performance.
Is MC Dropout Bayesian?
Oct 08, 2021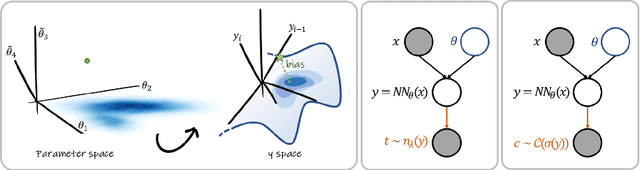

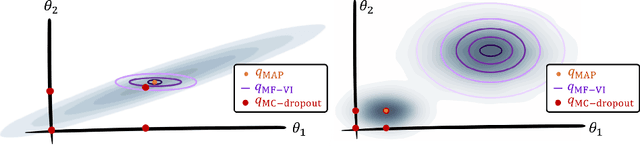

MC Dropout is a mainstream "free lunch" method in medical imaging for approximate Bayesian computations (ABC). Its appeal is to solve out-of-the-box the daunting task of ABC and uncertainty quantification in Neural Networks (NNs); to fall within the variational inference (VI) framework; and to propose a highly multimodal, faithful predictive posterior. We question the properties of MC Dropout for approximate inference, as in fact MC Dropout changes the Bayesian model; its predictive posterior assigns $0$ probability to the true model on closed-form benchmarks; the multimodality of its predictive posterior is not a property of the true predictive posterior but a design artefact. To address the need for VI on arbitrary models, we share a generic VI engine within the pytorch framework. The code includes a carefully designed implementation of structured (diagonal plus low-rank) multivariate normal variational families, and mixtures thereof. It is intended as a go-to no-free-lunch approach, addressing shortcomings of mean-field VI with an adjustable trade-off between expressivity and computational complexity.
The Pitfalls of Sample Selection: A Case Study on Lung Nodule Classification
Aug 11, 2021
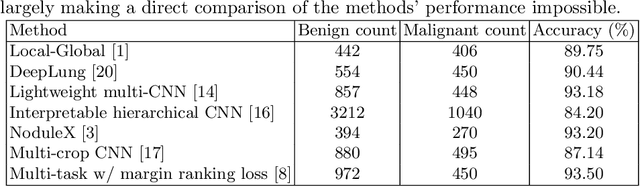
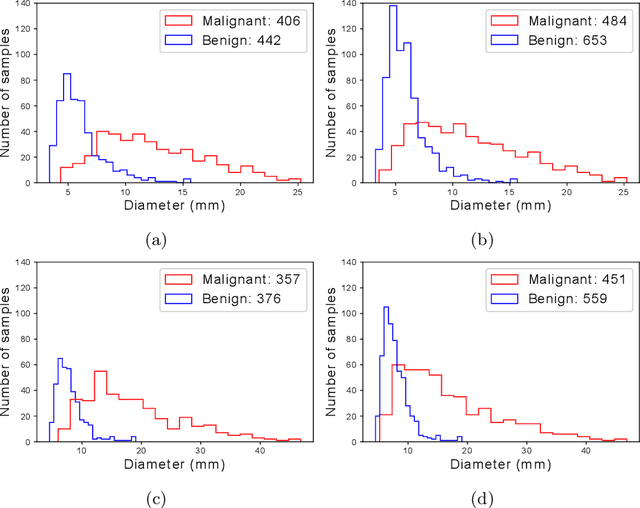
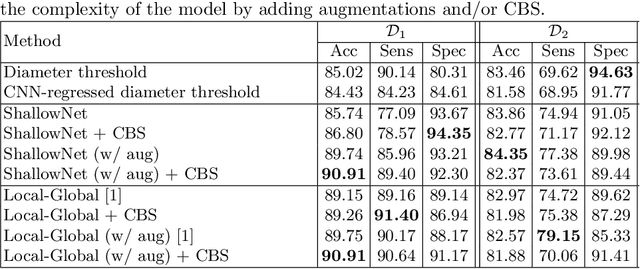
Using publicly available data to determine the performance of methodological contributions is important as it facilitates reproducibility and allows scrutiny of the published results. In lung nodule classification, for example, many works report results on the publicly available LIDC dataset. In theory, this should allow a direct comparison of the performance of proposed methods and assess the impact of individual contributions. When analyzing seven recent works, however, we find that each employs a different data selection process, leading to largely varying total number of samples and ratios between benign and malignant cases. As each subset will have different characteristics with varying difficulty for classification, a direct comparison between the proposed methods is thus not always possible, nor fair. We study the particular effect of truthing when aggregating labels from multiple experts. We show that specific choices can have severe impact on the data distribution where it may be possible to achieve superior performance on one sample distribution but not on another. While we show that we can further improve on the state-of-the-art on one sample selection, we also find that on a more challenging sample selection, on the same database, the more advanced models underperform with respect to very simple baseline methods, highlighting that the selected data distribution may play an even more important role than the model architecture. This raises concerns about the validity of claimed methodological contributions. We believe the community should be aware of these pitfalls and make recommendations on how these can be avoided in future work.
The Effect of the Loss on Generalization: Empirical Study on Synthetic Lung Nodule Data
Aug 10, 2021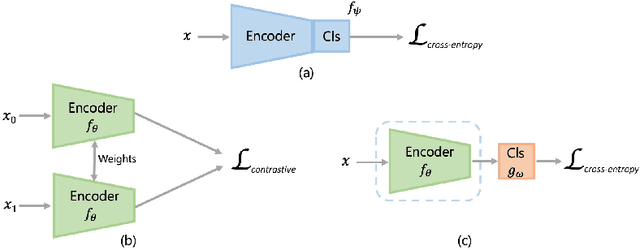
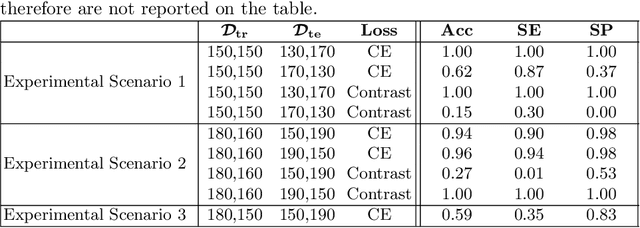
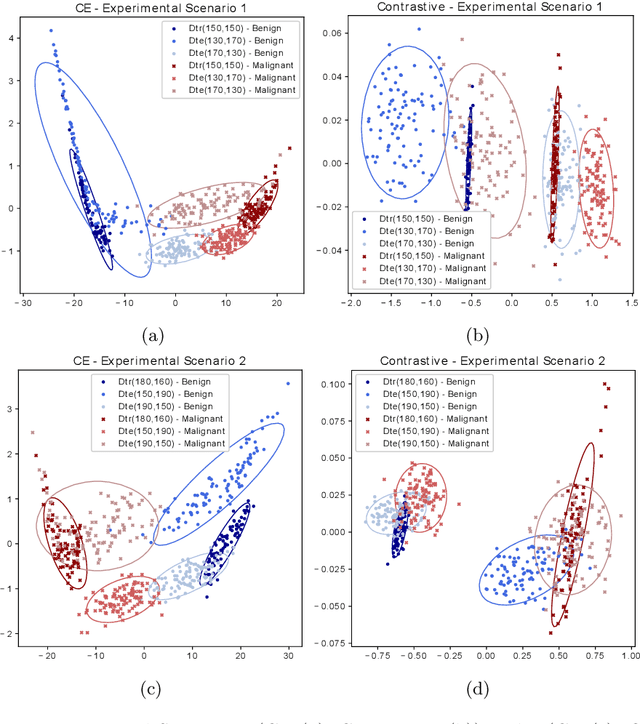

Convolutional Neural Networks (CNNs) are widely used for image classification in a variety of fields, including medical imaging. While most studies deploy cross-entropy as the loss function in such tasks, a growing number of approaches have turned to a family of contrastive learning-based losses. Even though performance metrics such as accuracy, sensitivity and specificity are regularly used for the evaluation of CNN classifiers, the features that these classifiers actually learn are rarely identified and their effect on the classification performance on out-of-distribution test samples is insufficiently explored. In this paper, motivated by the real-world task of lung nodule classification, we investigate the features that a CNN learns when trained and tested on different distributions of a synthetic dataset with controlled modes of variation. We show that different loss functions lead to different features being learned and consequently affect the generalization ability of the classifier on unseen data. This study provides some important insights into the design of deep learning solutions for medical imaging tasks.
Bayesian analysis of the prevalence bias: learning and predicting from imbalanced data
Jul 31, 2021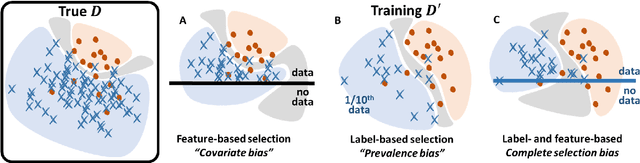
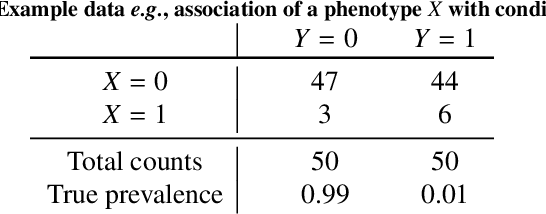

Datasets are rarely a realistic approximation of the target population. Say, prevalence is misrepresented, image quality is above clinical standards, etc. This mismatch is known as sampling bias. Sampling biases are a major hindrance for machine learning models. They cause significant gaps between model performance in the lab and in the real world. Our work is a solution to prevalence bias. Prevalence bias is the discrepancy between the prevalence of a pathology and its sampling rate in the training dataset, introduced upon collecting data or due to the practioner rebalancing the training batches. This paper lays the theoretical and computational framework for training models, and for prediction, in the presence of prevalence bias. Concretely a bias-corrected loss function, as well as bias-corrected predictive rules, are derived under the principles of Bayesian risk minimization. The loss exhibits a direct connection to the information gain. It offers a principled alternative to heuristic training losses and complements test-time procedures based on selecting an operating point from summary curves. It integrates seamlessly in the current paradigm of (deep) learning using stochastic backpropagation and naturally with Bayesian models.
Geometric Deep Learning for Post-Menstrual Age Prediction based on the Neonatal White Matter Cortical Surface
Aug 13, 2020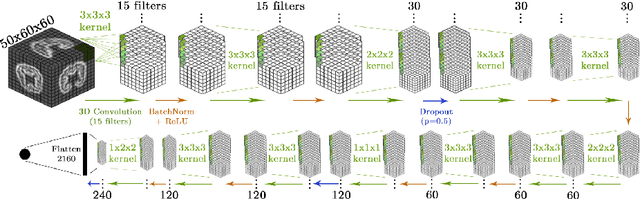
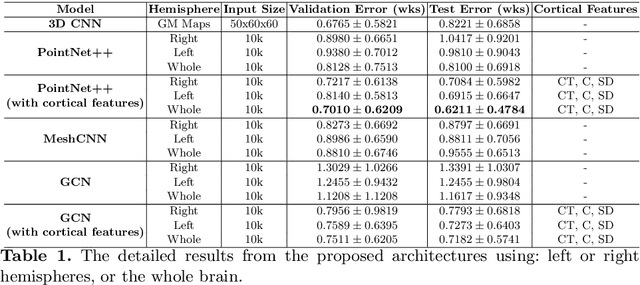

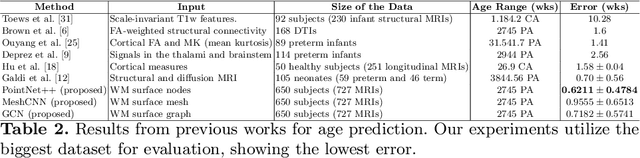
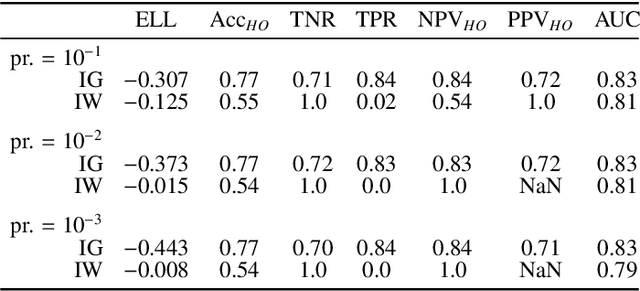
Accurate estimation of the age in neonates is essential for measuring neurodevelopmental, medical, and growth outcomes. In this paper, we propose a novel approach to predict the post-menstrual age (PA) at scan, using techniques from geometric deep learning, based on the neonatal white matter cortical surface. We utilize and compare multiple specialized neural network architectures that predict the age using different geometric representations of the cortical surface; we compare MeshCNN, Pointnet++, GraphCNN, and a volumetric benchmark. The dataset is part of the Developing Human Connectome Project (dHCP), and is a cohort of healthy and premature neonates. We evaluate our approach on 650 subjects (727scans) with PA ranging from 27 to 45 weeks. Our results show accurate prediction of the estimated PA, with mean error less than one week.
Explainable Shape Analysis through Deep Hierarchical Generative Models: Application to Cardiac Remodeling
Jun 28, 2019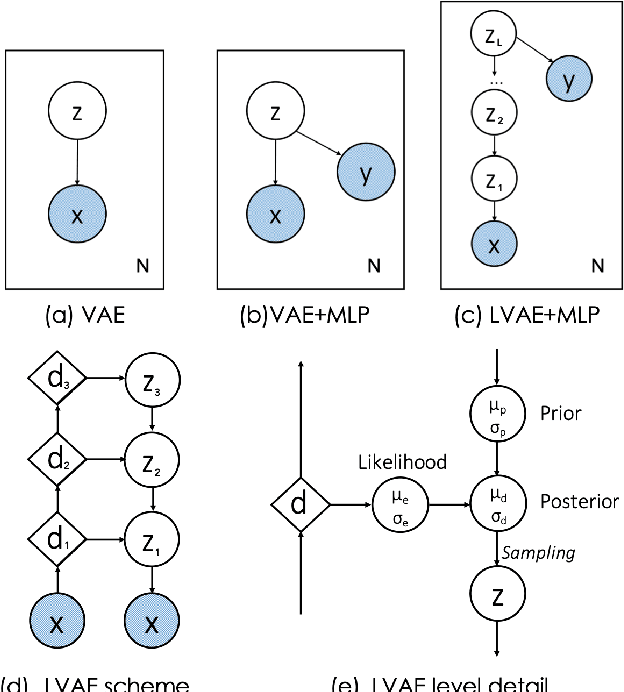
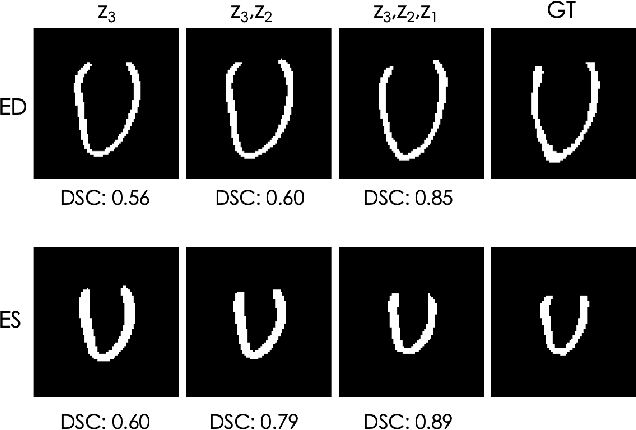


Quantification of anatomical shape changes still relies on scalar global indexes which are largely insensitive to regional or asymmetric modifications. Accurate assessment of pathology-driven anatomical remodeling is a crucial step for the diagnosis and treatment of heart conditions. Deep learning approaches have recently achieved wide success in the analysis of medical images, but they lack interpretability in the feature extraction and decision processes. In this work, we propose a new interpretable deep learning model for shape analysis. In particular, we exploit deep generative networks to model a population of anatomical segmentations through a hierarchy of conditional latent variables. At the highest level of this hierarchy, a two-dimensional latent space is simultaneously optimised to discriminate distinct clinical conditions, enabling the direct visualisation of the classification space. Moreover, the anatomical variability encoded by this discriminative latent space can be visualised in the segmentation space thanks to the generative properties of the model, making the classification task transparent. This approach yielded high accuracy in the categorisation of healthy and remodelled hearts when tested on unseen segmentations from our own multi-centre dataset as well as in an external validation set. More importantly, it enabled the visualisation in three-dimensions of the most discriminative anatomical features between the two conditions. The proposed approach scales effectively to large populations, facilitating high-throughput analysis of normal anatomy and pathology in large-scale studies of volumetric imaging.
Semi-Supervised Learning via Compact Latent Space Clustering
Jul 29, 2018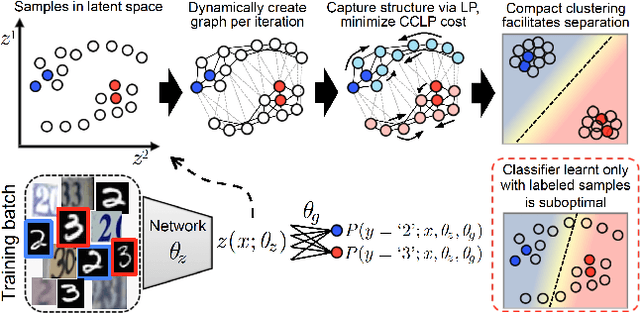
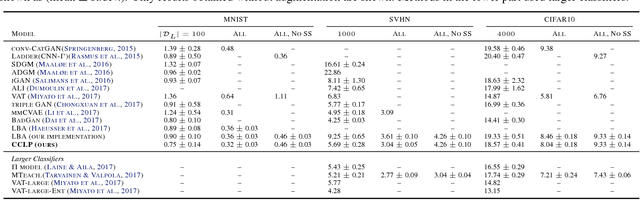
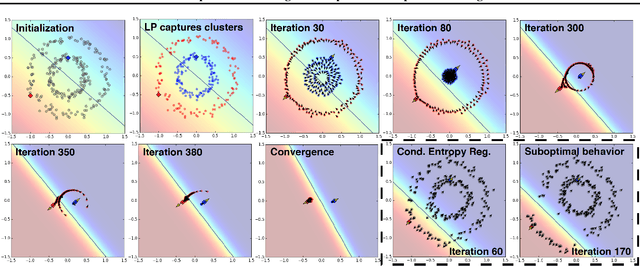
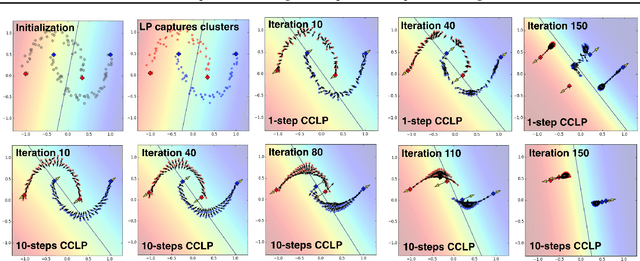
We present a novel cost function for semi-supervised learning of neural networks that encourages compact clustering of the latent space to facilitate separation. The key idea is to dynamically create a graph over embeddings of labeled and unlabeled samples of a training batch to capture underlying structure in feature space, and use label propagation to estimate its high and low density regions. We then devise a cost function based on Markov chains on the graph that regularizes the latent space to form a single compact cluster per class, while avoiding to disturb existing clusters during optimization. We evaluate our approach on three benchmarks and compare to state-of-the art with promising results. Our approach combines the benefits of graph-based regularization with efficient, inductive inference, does not require modifications to a network architecture, and can thus be easily applied to existing networks to enable an effective use of unlabeled data.