 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Hard Negatives Required: Concept Centric Learning Leads to Compositionality without Degrading Zero-shot Capabilities of Contrastive Models
Mar 26, 2026Contrastive vision-language (V&L) models remain a popular choice for various applications. However, several limitations have emerged, most notably the limited ability of V&L models to learn compositional representations. Prior methods often addressed this limitation by generating custom training data to obtain hard negative samples. Hard negatives have been shown to improve performance on compositionality tasks, but are often specific to a single benchmark, do not generalize, and can cause substantial degradation of basic V&L capabilities such as zero-shot or retrieval performance, rendering them impractical. In this work we follow a different approach. We identify two root causes that limit compositionality performance of V&Ls: 1) Long training captions do not require a compositional representation; and 2) The final global pooling in the text and image encoders lead to a complete loss of the necessary information to learn binding in the first place. As a remedy, we propose two simple solutions: 1) We obtain short concept centric caption parts using standard NLP software and align those with the image; and 2) We introduce a parameter-free cross-modal attention-pooling to obtain concept centric visual embeddings from the image encoder. With these two changes and simple auxiliary contrastive losses, we obtain SOTA performance on standard compositionality benchmarks, while maintaining or improving strong zero-shot and retrieval capabilities. This is achieved without increasing inference cost. We release the code for this work at https://github.com/SamsungLabs/concept_centric_clip.
D2DF2WOD: Learning Object Proposals for Weakly-Supervised Object Detection via Progressive Domain Adaptation
Dec 02, 2022



Weakly-supervised object detection (WSOD) models attempt to leverage image-level annotations in lieu of accurate but costly-to-obtain object localization labels. This oftentimes leads to substandard object detection and localization at inference time. To tackle this issue, we propose D2DF2WOD, a Dual-Domain Fully-to-Weakly Supervised Object Detection framework that leverages synthetic data, annotated with precise object localization, to supplement a natural image target domain, where only image-level labels are available. In its warm-up domain adaptation stage, the model learns a fully-supervised object detector (FSOD) to improve the precision of the object proposals in the target domain, and at the same time learns target-domain-specific and detection-aware proposal features. In its main WSOD stage, a WSOD model is specifically tuned to the target domain. The feature extractor and the object proposal generator of the WSOD model are built upon the fine-tuned FSOD model. We test D2DF2WOD on five dual-domain image benchmarks. The results show that our method results in consistently improved object detection and localization compared with state-of-the-art methods.
FS-DETR: Few-Shot DEtection TRansformer with prompting and without re-training
Oct 10, 2022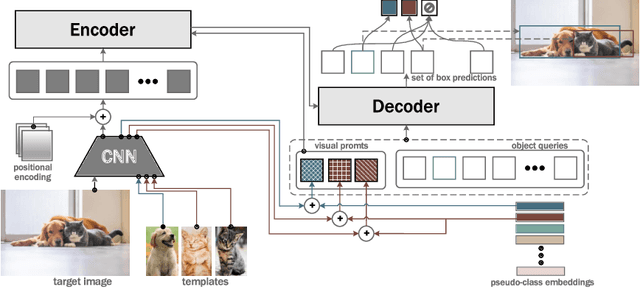
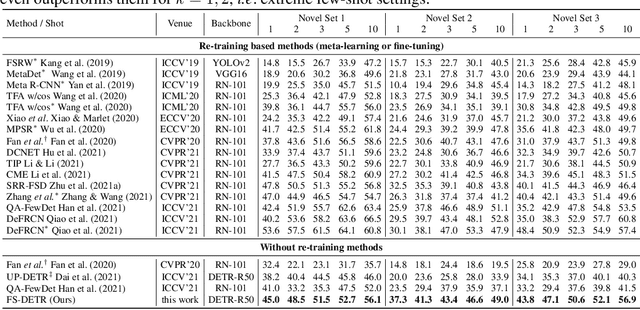
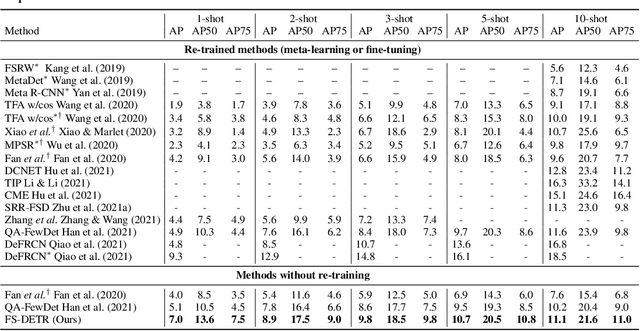
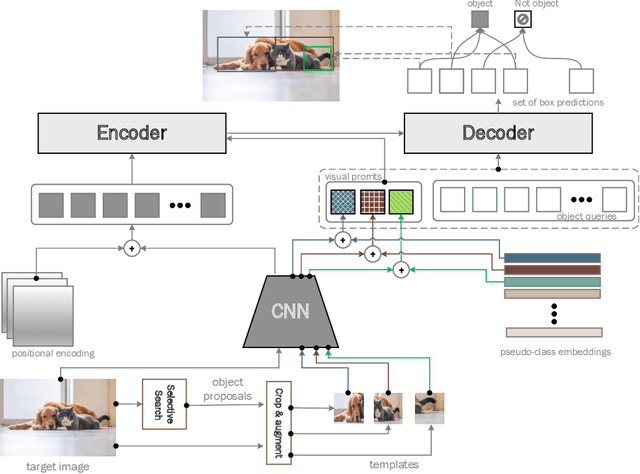
This paper is on Few-Shot Object Detection (FSOD), where given a few templates (examples) depicting a novel class (not seen during training), the goal is to detect all of its occurrences within a set of images. From a practical perspective, an FSOD system must fulfil the following desiderata: (a) it must be used as is, without requiring any fine-tuning at test time, (b) it must be able to process an arbitrary number of novel objects concurrently while supporting an arbitrary number of examples from each class and (c) it must achieve accuracy comparable to a closed system. While there are (relatively) few systems that support (a), to our knowledge, there is no system supporting (b) and (c). In this work, we make the following contributions: We introduce, for the first time, a simple, yet powerful, few-shot detection transformer (FS-DETR) that can address both desiderata (a) and (b). Our system builds upon the DETR framework, extending it based on two key ideas: (1) feed the provided visual templates of the novel classes as visual prompts during test time, and (2) ``stamp'' these prompts with pseudo-class embeddings, which are then predicted at the output of the decoder. Importantly, we show that our system is not only more flexible than existing methods, but also, making a step towards satisfying desideratum (c), it is more accurate, matching and outperforming the current state-of-the-art on the most well-established benchmarks (PASCAL VOC & MSCOCO) for FSOD. Code will be made available.
SOS! Self-supervised Learning Over Sets Of Handled Objects In Egocentric Action Recognition
Apr 10, 2022
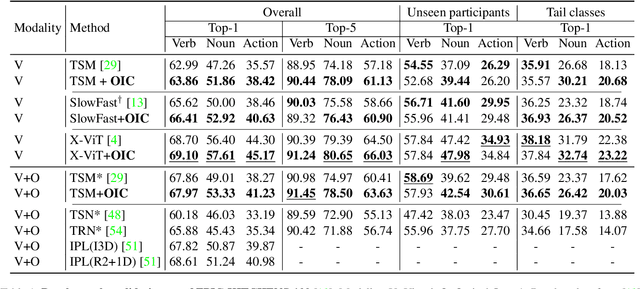

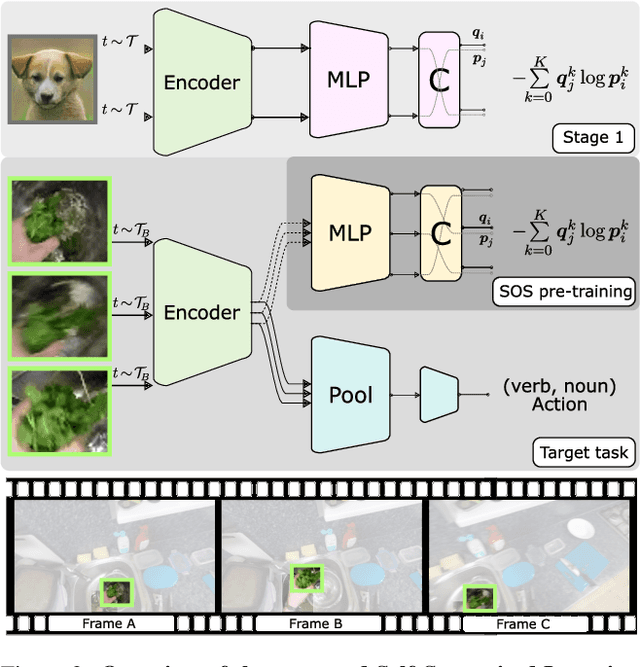
Learning an egocentric action recognition model from video data is challenging due to distractors (e.g., irrelevant objects) in the background. Further integrating object information into an action model is hence beneficial. Existing methods often leverage a generic object detector to identify and represent the objects in the scene. However, several important issues remain. Object class annotations of good quality for the target domain (dataset) are still required for learning good object representation. Besides, previous methods deeply couple the existing action models and need to retrain them jointly with object representation, leading to costly and inflexible integration. To overcome both limitations, we introduce Self-Supervised Learning Over Sets (SOS), an approach to pre-train a generic Objects In Contact (OIC) representation model from video object regions detected by an off-the-shelf hand-object contact detector. Instead of augmenting object regions individually as in conventional self-supervised learning, we view the action process as a means of natural data transformations with unique spatio-temporal continuity and exploit the inherent relationships among per-video object sets. Extensive experiments on two datasets, EPIC-KITCHENS-100 and EGTEA, show that our OIC significantly boosts the performance of multiple state-of-the-art video classification models.
Multi-attribute Pizza Generator: Cross-domain Attribute Control with Conditional StyleGAN
Oct 22, 2021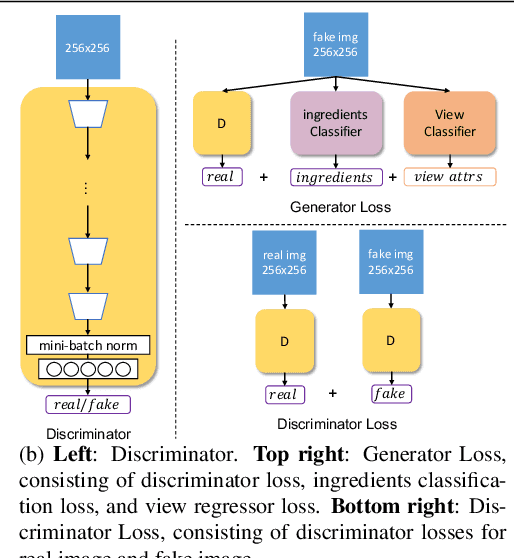
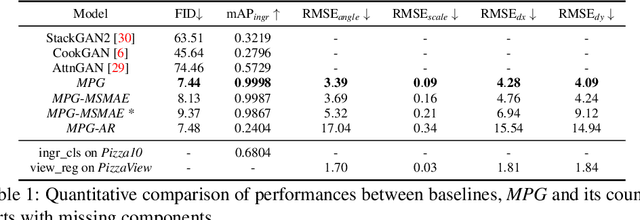
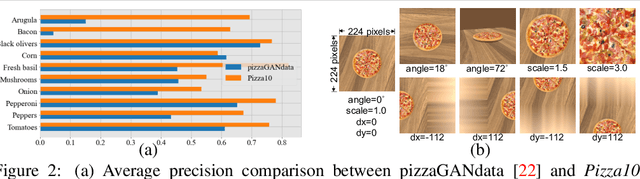
Multi-attribute conditional image generation is a challenging problem in computervision. We propose Multi-attribute Pizza Generator (MPG), a conditional Generative Neural Network (GAN) framework for synthesizing images from a trichotomy of attributes: content, view-geometry, and implicit visual style. We design MPG by extending the state-of-the-art StyleGAN2, using a new conditioning technique that guides the intermediate feature maps to learn multi-scale multi-attribute entangled representationsof controlling attributes. Because of the complex nature of the multi-attribute image generation problem, we regularize the image generation by predicting the explicit conditioning attributes (ingredients and view). To synthesize a pizza image with view attributesoutside the range of natural training images, we design a CGI pizza dataset PizzaView using 3D pizza models and employ it to train a view attribute regressor to regularize the generation process, bridging the real and CGI training datasets. To verify the efficacy of MPG, we test it on Pizza10, a carefully annotated multi-ingredient pizza image dataset. MPG can successfully generate photo-realistic pizza images with desired ingredients and view attributes, beyond the range of those observed in real-world training data.
CHEF: Cross-modal Hierarchical Embeddings for Food Domain Retrieval
Feb 04, 2021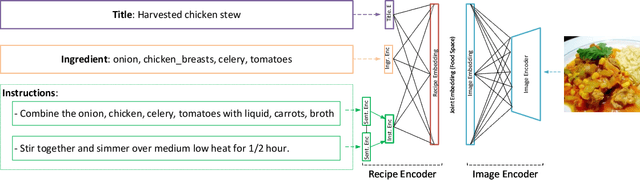
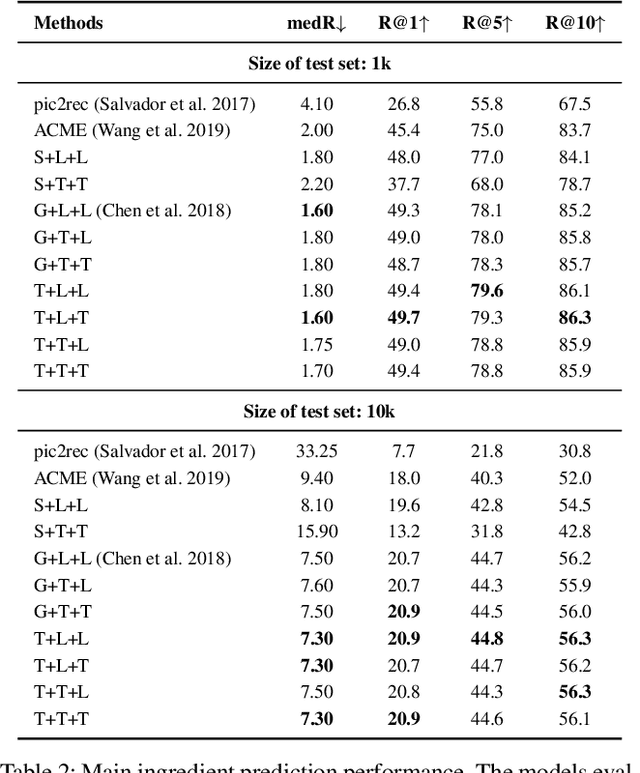
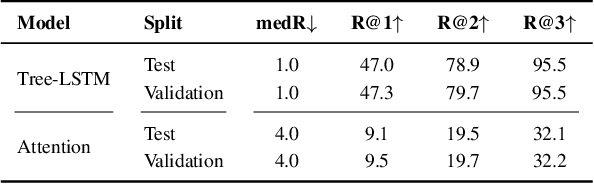

Despite the abundance of multi-modal data, such as image-text pairs, there has been little effort in understanding the individual entities and their different roles in the construction of these data instances. In this work, we endeavour to discover the entities and their corresponding importance in cooking recipes automaticall} as a visual-linguistic association problem. More specifically, we introduce a novel cross-modal learning framework to jointly model the latent representations of images and text in the food image-recipe association and retrieval tasks. This model allows one to discover complex functional and hierarchical relationships between images and text, and among textual parts of a recipe including title, ingredients and cooking instructions. Our experiments show that by making use of efficient tree-structured Long Short-Term Memory as the text encoder in our computational cross-modal retrieval framework, we are not only able to identify the main ingredients and cooking actions in the recipe descriptions without explicit supervision, but we can also learn more meaningful feature representations of food recipes, appropriate for challenging cross-modal retrieval and recipe adaption tasks.
Cross-modal Retrieval and Synthesis (X-MRS): Closing the modality gap in shared subspace
Dec 21, 2020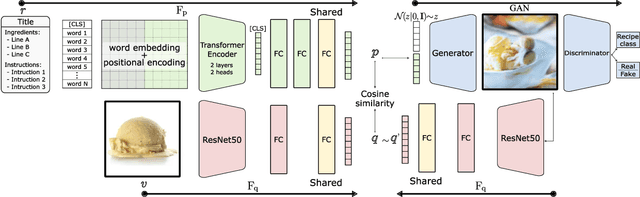
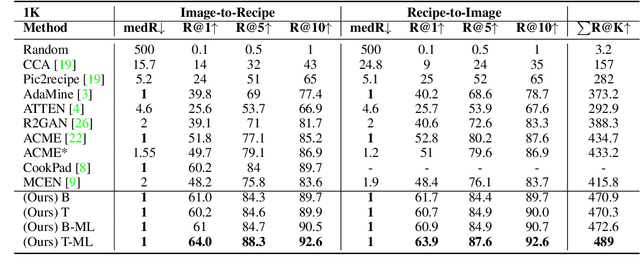
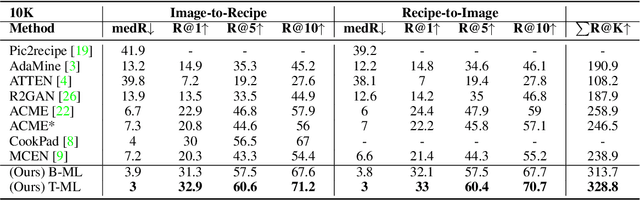

Computational food analysis (CFA), a broad set of methods that attempt to automate food understanding, naturally requires analysis of multi-modal evidence of a particular food or dish, e.g. images, recipe text, preparation video, nutrition labels, etc. A key to making CFA possible is multi-modal shared subspace learning, which in turn can be used for cross-modal retrieval and/or synthesis, particularly, between food images and their corresponding textual recipes. In this work we propose a simple yet novel architecture for shared subspace learning, which is used to tackle the food image-to-recipe retrieval problem. Our proposed method employs an effective transformer based multilingual recipe encoder coupled with a traditional image embedding architecture. Experimental analysis on the public Recipe1M dataset shows that the subspace learned via the proposed method outperforms the current state-of-the-arts (SoTA) in food retrieval by a large margin, obtaining recall@1 of 0.64. Furthermore, in order to demonstrate the representational power of the learned subspace, we propose a generative food image synthesis model conditioned on the embeddings of recipes. Synthesized images can effectively reproduce the visual appearance of paired samples, achieving R@1 of 0.68 in the image-to-recipe retrieval experiment, thus effectively capturing the semantics of the textual recipe.
MPG: A Multi-ingredient Pizza Image Generator with Conditional StyleGANs
Dec 04, 2020
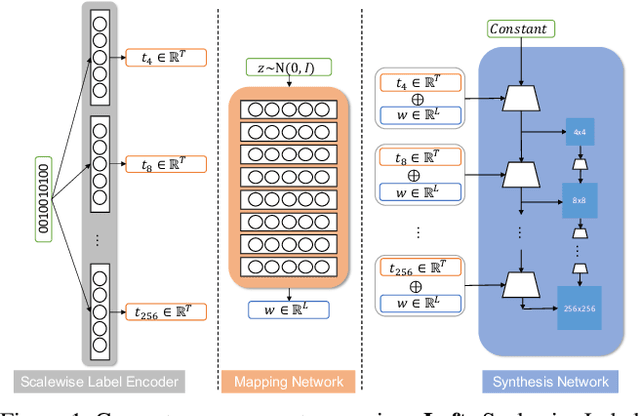
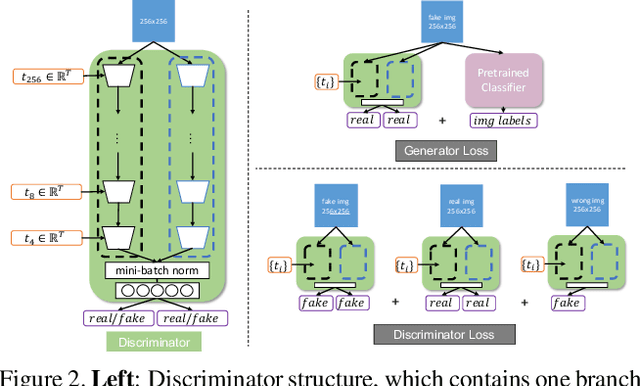
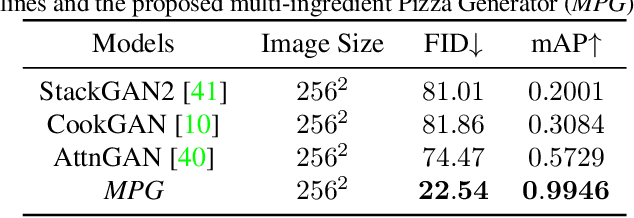
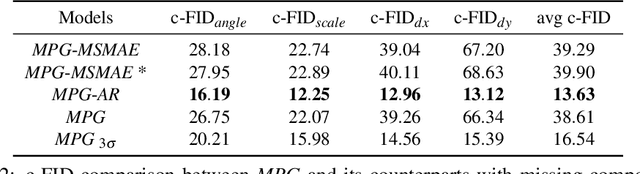
Multilabel conditional image generation is a challenging problem in computer vision. In this work we propose Multi-ingredient Pizza Generator (MPG), a conditional Generative Neural Network (GAN) framework for synthesizing multilabel images. We design MPG based on a state-of-the-art GAN structure called StyleGAN2, in which we develop a new conditioning technique by enforcing intermediate feature maps to learn scalewise label information. Because of the complex nature of the multilabel image generation problem, we also regularize synthetic image by predicting the corresponding ingredients as well as encourage the discriminator to distinguish between matched image and mismatched image. To verify the efficacy of MPG, we test it on Pizza10, which is a carefully annotated multi-ingredient pizza image dataset. MPG can successfully generate photo-realist pizza images with desired ingredients. The framework can be easily extend to other multilabel image generation scenarios.
Learning Disentangled Latent Factors from Paired Data in Cross-Modal Retrieval: An Implicit Identifiable VAE Approach
Dec 01, 2020
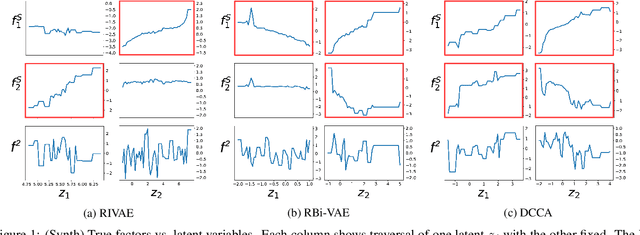


We deal with the problem of learning the underlying disentangled latent factors that are shared between the paired bi-modal data in cross-modal retrieval. Our assumption is that the data in both modalities are complex, structured, and high dimensional (e.g., image and text), for which the conventional deep auto-encoding latent variable models such as the Variational Autoencoder (VAE) often suffer from difficulty of accurate decoder training or realistic synthesis. A suboptimally trained decoder can potentially harm the model's capability of identifying the true factors. In this paper we propose a novel idea of the implicit decoder, which completely removes the ambient data decoding module from a latent variable model, via implicit encoder inversion that is achieved by Jacobian regularization of the low-dimensional embedding function. Motivated from the recent Identifiable VAE (IVAE) model, we modify it to incorporate the query modality data as conditioning auxiliary input, which allows us to prove that the true parameters of the model can be identified under some regularity conditions. Tested on various datasets where the true factors are fully/partially available, our model is shown to identify the factors accurately, significantly outperforming conventional encoder-decoder latent variable models. We also test our model on the Recipe1M, the large-scale food image/recipe dataset, where the learned factors by our approach highly coincide with the most pronounced food factors that are widely agreed on, including savoriness, wateriness, and greenness.
Picture-to-Amount (PITA): Predicting Relative Ingredient Amounts from Food Images
Oct 17, 2020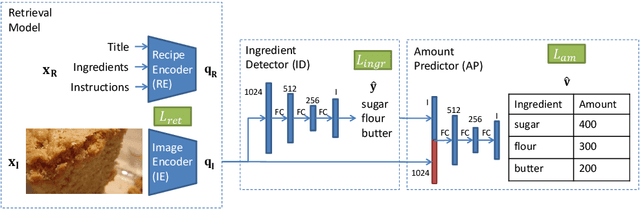
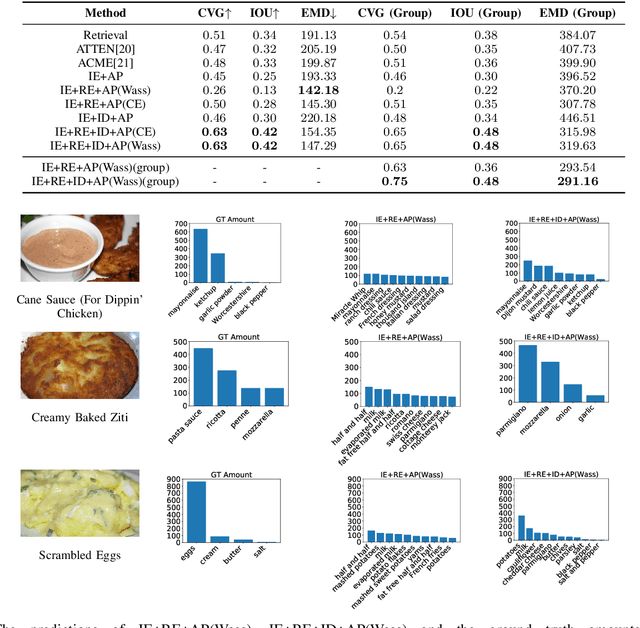

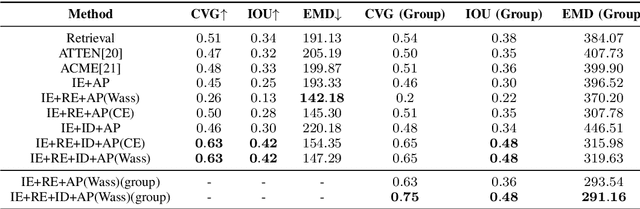
Increased awareness of the impact of food consumption on health and lifestyle today has given rise to novel data-driven food analysis systems. Although these systems may recognize the ingredients, a detailed analysis of their amounts in the meal, which is paramount for estimating the correct nutrition, is usually ignored. In this paper, we study the novel and challenging problem of predicting the relative amount of each ingredient from a food image. We propose PITA, the Picture-to-Amount deep learning architecture to solve the problem. More specifically, we predict the ingredient amounts using a domain-driven Wasserstein loss from image-to-recipe cross-modal embeddings learned to align the two views of food data. Experiments on a dataset of recipes collected from the Internet show the model generates promising results and improves the baselines on this challenging task. A demo of our system and our data is availableat: foodai.cs.rutgers.edu.