 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePicture-to-Amount (PITA): Predicting Relative Ingredient Amounts from Food Images
Paper and Code
Oct 17, 2020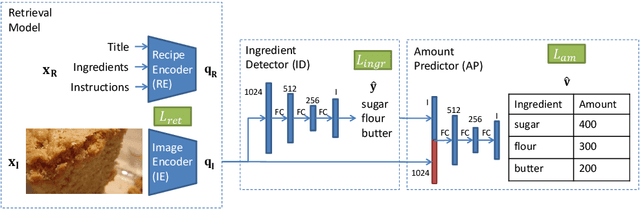
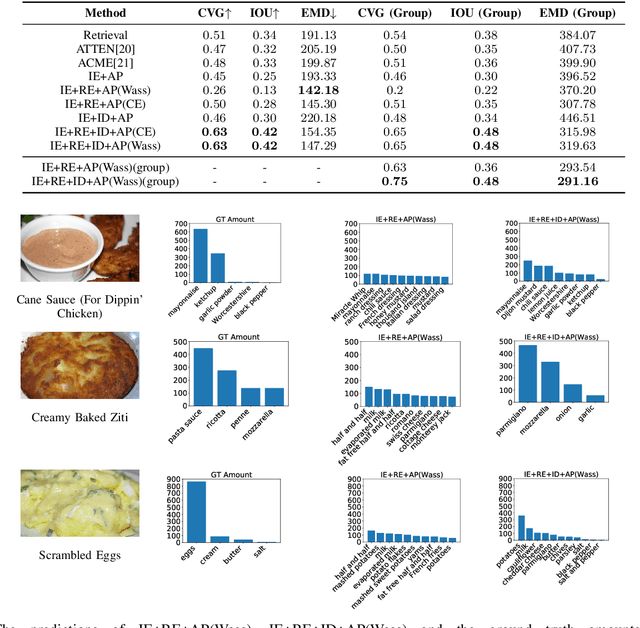

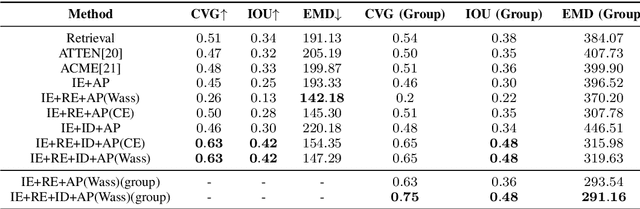
Increased awareness of the impact of food consumption on health and lifestyle today has given rise to novel data-driven food analysis systems. Although these systems may recognize the ingredients, a detailed analysis of their amounts in the meal, which is paramount for estimating the correct nutrition, is usually ignored. In this paper, we study the novel and challenging problem of predicting the relative amount of each ingredient from a food image. We propose PITA, the Picture-to-Amount deep learning architecture to solve the problem. More specifically, we predict the ingredient amounts using a domain-driven Wasserstein loss from image-to-recipe cross-modal embeddings learned to align the two views of food data. Experiments on a dataset of recipes collected from the Internet show the model generates promising results and improves the baselines on this challenging task. A demo of our system and our data is availableat: foodai.cs.rutgers.edu.