 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-attribute Pizza Generator: Cross-domain Attribute Control with Conditional StyleGAN
Oct 22, 2021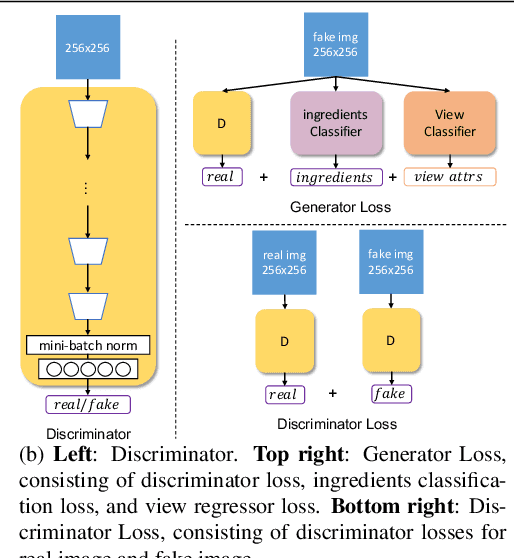
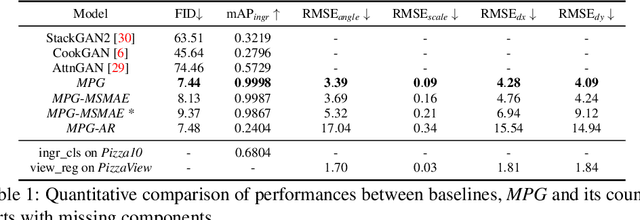
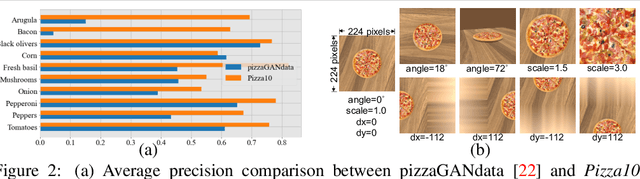
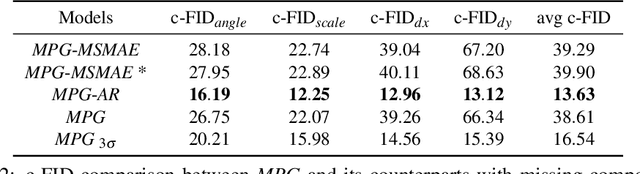
Multi-attribute conditional image generation is a challenging problem in computervision. We propose Multi-attribute Pizza Generator (MPG), a conditional Generative Neural Network (GAN) framework for synthesizing images from a trichotomy of attributes: content, view-geometry, and implicit visual style. We design MPG by extending the state-of-the-art StyleGAN2, using a new conditioning technique that guides the intermediate feature maps to learn multi-scale multi-attribute entangled representationsof controlling attributes. Because of the complex nature of the multi-attribute image generation problem, we regularize the image generation by predicting the explicit conditioning attributes (ingredients and view). To synthesize a pizza image with view attributesoutside the range of natural training images, we design a CGI pizza dataset PizzaView using 3D pizza models and employ it to train a view attribute regressor to regularize the generation process, bridging the real and CGI training datasets. To verify the efficacy of MPG, we test it on Pizza10, a carefully annotated multi-ingredient pizza image dataset. MPG can successfully generate photo-realistic pizza images with desired ingredients and view attributes, beyond the range of those observed in real-world training data.
Cross-Modal Coherence for Text-to-Image Retrieval
Sep 22, 2021

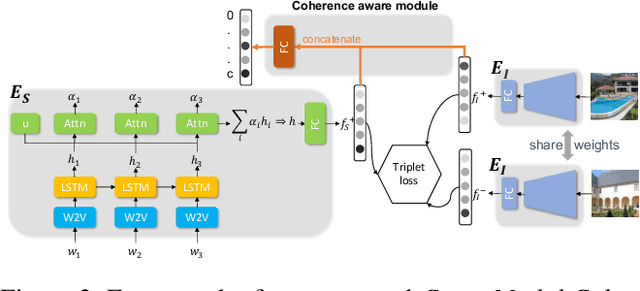

Common image-text joint understanding techniques presume that images and the associated text can universally be characterized by a single implicit model. However, co-occurring images and text can be related in qualitatively different ways, and explicitly modeling it could improve the performance of current joint understanding models. In this paper, we train a Cross-Modal Coherence Modelfor text-to-image retrieval task. Our analysis shows that models trained with image--text coherence relations can retrieve images originally paired with target text more often than coherence-agnostic models. We also show via human evaluation that images retrieved by the proposed coherence-aware model are preferred over a coherence-agnostic baseline by a huge margin. Our findings provide insights into the ways that different modalities communicate and the role of coherence relations in capturing commonsense inferences in text and imagery.
MPG: A Multi-ingredient Pizza Image Generator with Conditional StyleGANs
Dec 04, 2020
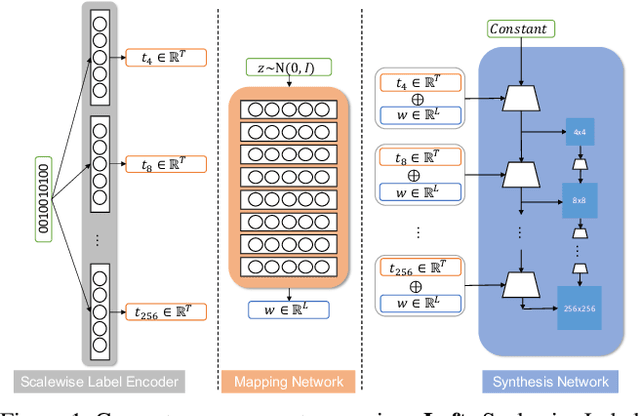
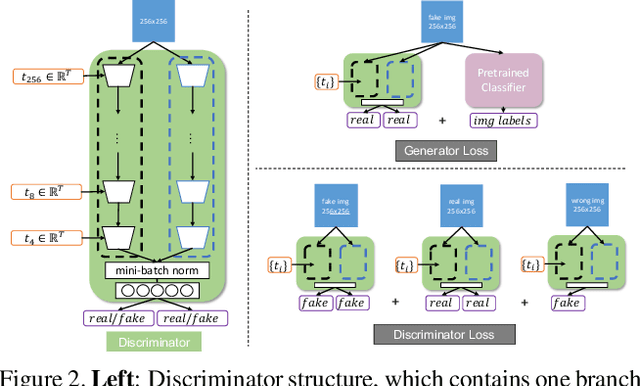
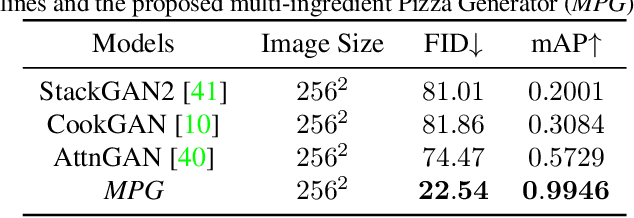
Multilabel conditional image generation is a challenging problem in computer vision. In this work we propose Multi-ingredient Pizza Generator (MPG), a conditional Generative Neural Network (GAN) framework for synthesizing multilabel images. We design MPG based on a state-of-the-art GAN structure called StyleGAN2, in which we develop a new conditioning technique by enforcing intermediate feature maps to learn scalewise label information. Because of the complex nature of the multilabel image generation problem, we also regularize synthetic image by predicting the corresponding ingredients as well as encourage the discriminator to distinguish between matched image and mismatched image. To verify the efficacy of MPG, we test it on Pizza10, which is a carefully annotated multi-ingredient pizza image dataset. MPG can successfully generate photo-realist pizza images with desired ingredients. The framework can be easily extend to other multilabel image generation scenarios.
Picture-to-Amount (PITA): Predicting Relative Ingredient Amounts from Food Images
Oct 17, 2020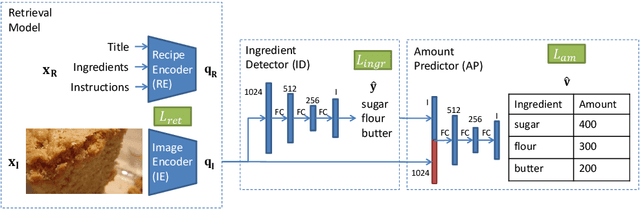
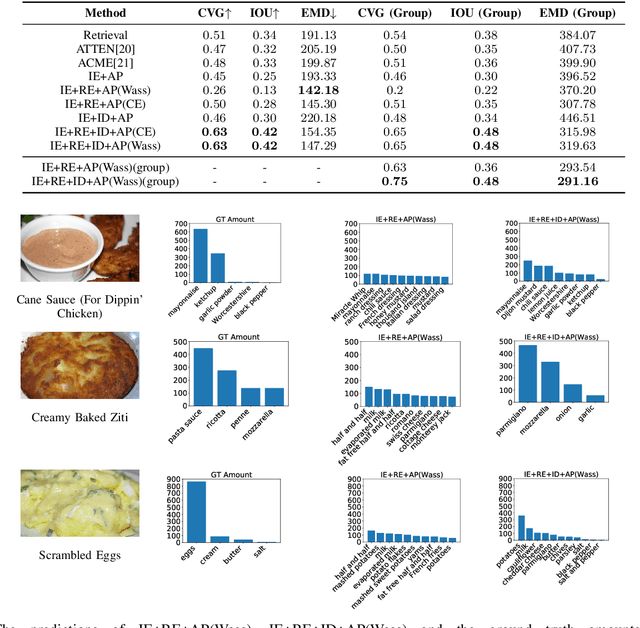

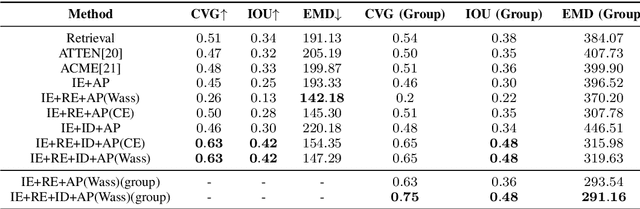
Increased awareness of the impact of food consumption on health and lifestyle today has given rise to novel data-driven food analysis systems. Although these systems may recognize the ingredients, a detailed analysis of their amounts in the meal, which is paramount for estimating the correct nutrition, is usually ignored. In this paper, we study the novel and challenging problem of predicting the relative amount of each ingredient from a food image. We propose PITA, the Picture-to-Amount deep learning architecture to solve the problem. More specifically, we predict the ingredient amounts using a domain-driven Wasserstein loss from image-to-recipe cross-modal embeddings learned to align the two views of food data. Experiments on a dataset of recipes collected from the Internet show the model generates promising results and improves the baselines on this challenging task. A demo of our system and our data is availableat: foodai.cs.rutgers.edu.
CookGAN: Meal Image Synthesis from Ingredients
Feb 25, 2020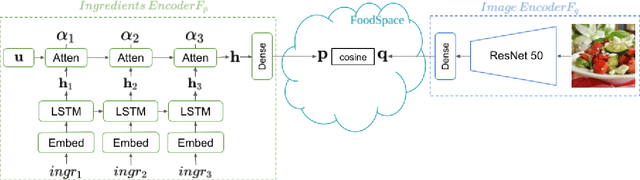
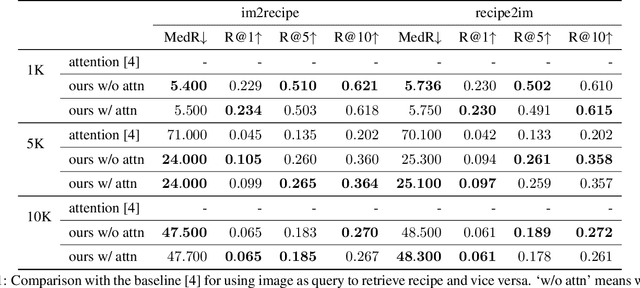
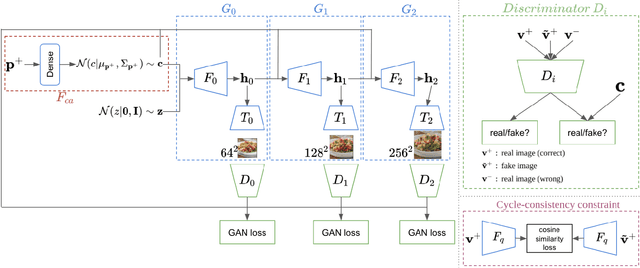
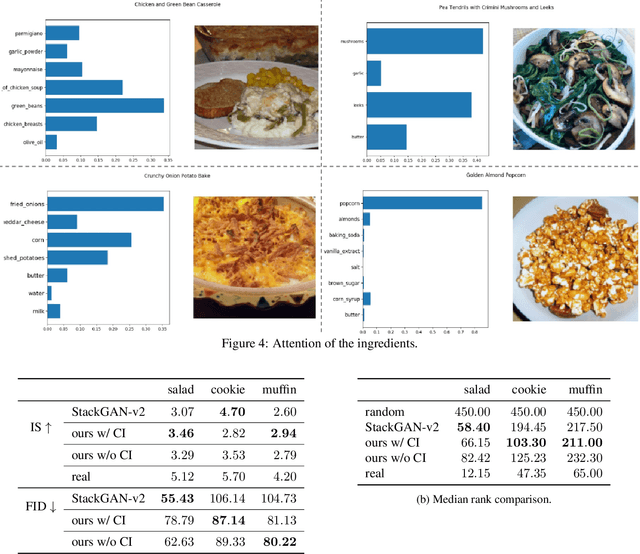
In this work we propose a new computational framework, based on generative deep models, for synthesis of photo-realistic food meal images from textual list of its ingredients. Previous works on synthesis of images from text typically rely on pre-trained text models to extract text features, followed by generative neural networks (GAN) aimed to generate realistic images conditioned on the text features. These works mainly focus on generating spatially compact and well-defined categories of objects, such as birds or flowers, but meal images are significantly more complex, consisting of multiple ingredients whose appearance and spatial qualities are further modified by cooking methods. To generate real-like meal images from ingredients, we propose Cook Generative Adversarial Networks (CookGAN), CookGAN first builds an attention-based ingredients-image association model, which is then used to condition a generative neural network tasked with synthesizing meal images. Furthermore, a cycle-consistent constraint is added to further improve image quality and control appearance. Experiments show our model is able to generate meal images corresponding to the ingredients.
The Art of Food: Meal Image Synthesis from Ingredients
May 09, 2019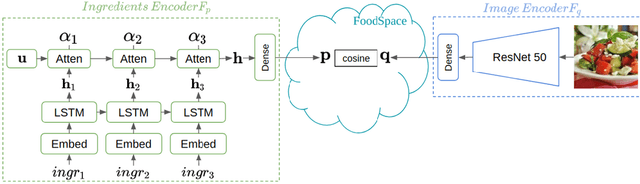
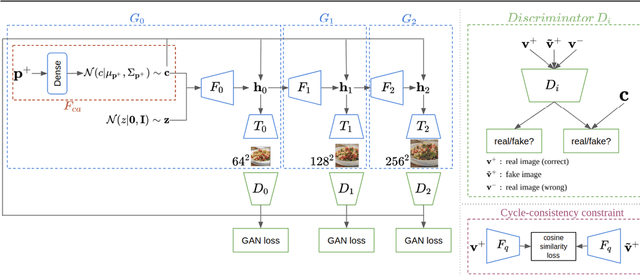


In this work we propose a new computational framework, based on generative deep models, for synthesis of photo-realistic food meal images from textual descriptions of its ingredients. Previous works on synthesis of images from text typically rely on pre-trained text models to extract text features, followed by a generative neural networks (GANs) aimed to generate realistic images conditioned on the text features. These works mainly focus on generating spatially compact and well-defined categories of objects, such as birds or flowers. In contrast, meal images are significantly more complex, consisting of multiple ingredients whose appearance and spatial qualities are further modified by cooking methods. We propose a method that first builds an attention-based ingredients-image association model, which is then used to condition a generative neural network tasked with synthesizing meal images. Furthermore, a cycle-consistent constraint is added to further improve image quality and control appearance. Extensive experiments show our model is able to generate meal image corresponding to the ingredients, which could be used to augment existing dataset for solving other computational food analysis problems.
Sketch-Based Face Editing in Videos Using Identity Deformation Transfer
May 31, 2018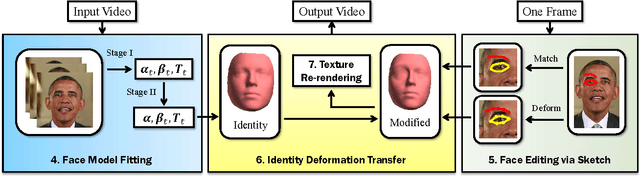
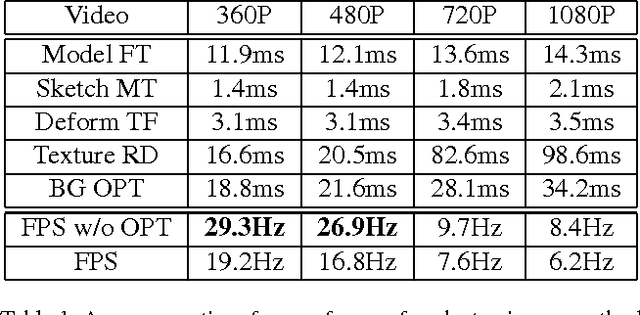
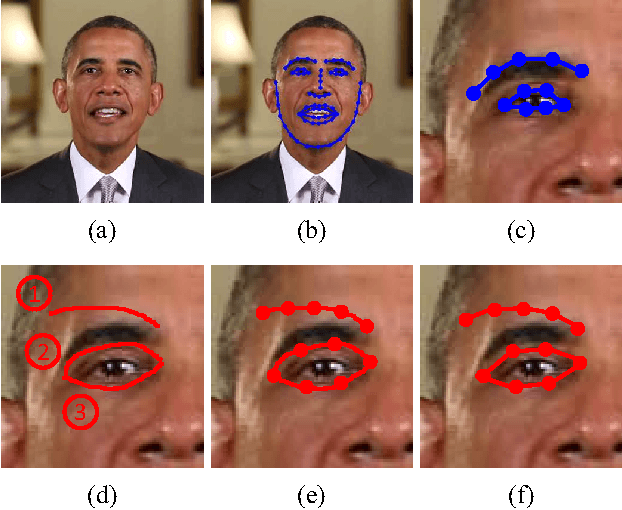

We address the problem of using hand-drawn sketches to edit the facial identity, such as enlarging the shape or modifying the position of eyes or mouth, in the entire video. This task is formulated as a 3D face model reconstruction and deformation problem. We first introduce a two-stage real-time 3D face model fitting schema to recover the facial identity and expressions from the video. User's editing intention is recognized from input sketches as a set of facial modifications. Then a novel identity deformation algorithm is proposed to transfer these facial deformations from 2D space to the 3D facial identity directly, while preserving the facial expressions. After an optional stage for further refining the 3D face model, these changes are propagated to the whole video with the modified identity. Both the user study and experimental results demonstrate that our sketching framework can help users effectively edit facial identities in videos, while high consistency and fidelity are ensured at the same time.