 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniFusion: Vision-Language Model as Unified Encoder in Image Generation
Oct 14, 2025
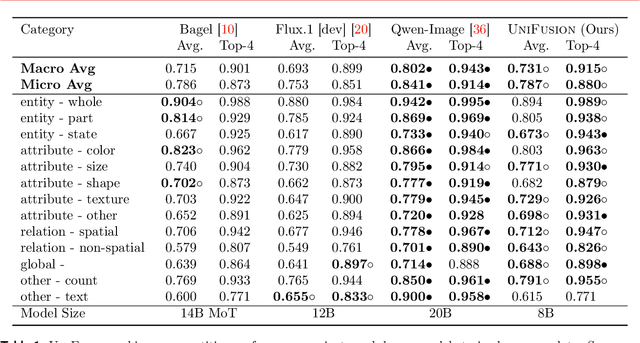

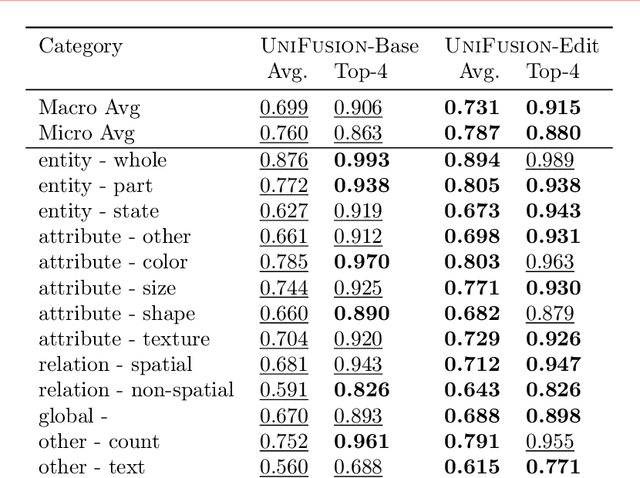
Although recent advances in visual generation have been remarkable, most existing architectures still depend on distinct encoders for images and text. This separation constrains diffusion models' ability to perform cross-modal reasoning and knowledge transfer. Prior attempts to bridge this gap often use the last layer information from VLM, employ multiple visual encoders, or train large unified models jointly for text and image generation, which demands substantial computational resources and large-scale data, limiting its accessibility.We present UniFusion, a diffusion-based generative model conditioned on a frozen large vision-language model (VLM) that serves as a unified multimodal encoder. At the core of UniFusion is the Layerwise Attention Pooling (LAP) mechanism that extracts both high level semantics and low level details from text and visual tokens of a frozen VLM to condition a diffusion generative model. We demonstrate that LAP outperforms other shallow fusion architectures on text-image alignment for generation and faithful transfer of visual information from VLM to the diffusion model which is key for editing. We propose VLM-Enabled Rewriting Injection with Flexibile Inference (VERIFI), which conditions a diffusion transformer (DiT) only on the text tokens generated by the VLM during in-model prompt rewriting. VERIFI combines the alignment of the conditioning distribution with the VLM's reasoning capabilities for increased capabilities and flexibility at inference. In addition, finetuning on editing task not only improves text-image alignment for generation, indicative of cross-modality knowledge transfer, but also exhibits tremendous generalization capabilities. Our model when trained on single image editing, zero-shot generalizes to multiple image references further motivating the unified encoder design of UniFusion.
Towards Enhanced Controllability of Diffusion Models
Mar 15, 2023Denoising Diffusion models have shown remarkable capabilities in generating realistic, high-quality and diverse images. However, the extent of controllability during generation is underexplored. Inspired by techniques based on GAN latent space for image manipulation, we train a diffusion model conditioned on two latent codes, a spatial content mask and a flattened style embedding. We rely on the inductive bias of the progressive denoising process of diffusion models to encode pose/layout information in the spatial structure mask and semantic/style information in the style code. We propose two generic sampling techniques for improving controllability. We extend composable diffusion models to allow for some dependence between conditional inputs, to improve the quality of generations while also providing control over the amount of guidance from each latent code and their joint distribution. We also propose timestep dependent weight scheduling for content and style latents to further improve the translations. We observe better controllability compared to existing methods and show that without explicit training objectives, diffusion models can be used for effective image manipulation and image translation.
Controlled and Conditional Text to Image Generation with Diffusion Prior
Feb 23, 2023Denoising Diffusion models have shown remarkable performance in generating diverse, high quality images from text. Numerous techniques have been proposed on top of or in alignment with models like Stable Diffusion and Imagen that generate images directly from text. A lesser explored approach is DALLE-2's two step process comprising a Diffusion Prior that generates a CLIP image embedding from text and a Diffusion Decoder that generates an image from a CLIP image embedding. We explore the capabilities of the Diffusion Prior and the advantages of an intermediate CLIP representation. We observe that Diffusion Prior can be used in a memory and compute efficient way to constrain the generation to a specific domain without altering the larger Diffusion Decoder. Moreover, we show that the Diffusion Prior can be trained with additional conditional information such as color histogram to further control the generation. We show quantitatively and qualitatively that the proposed approaches perform better than prompt engineering for domain specific generation and existing baselines for color conditioned generation. We believe that our observations and results will instigate further research into the diffusion prior and uncover more of its capabilities.
PRedItOR: Text Guided Image Editing with Diffusion Prior
Feb 15, 2023



Diffusion models have shown remarkable capabilities in generating high quality and creative images conditioned on text. An interesting application of such models is structure preserving text guided image editing. Existing approaches rely on text conditioned diffusion models such as Stable Diffusion or Imagen and require compute intensive optimization of text embeddings or fine-tuning the model weights for text guided image editing. We explore text guided image editing with a Hybrid Diffusion Model (HDM) architecture similar to DALLE-2. Our architecture consists of a diffusion prior model that generates CLIP image embedding conditioned on a text prompt and a custom Latent Diffusion Model trained to generate images conditioned on CLIP image embedding. We discover that the diffusion prior model can be used to perform text guided conceptual edits on the CLIP image embedding space without any finetuning or optimization. We combine this with structure preserving edits on the image decoder using existing approaches such as reverse DDIM to perform text guided image editing. Our approach, PRedItOR does not require additional inputs, fine-tuning, optimization or objectives and shows on par or better results than baselines qualitatively and quantitatively. We provide further analysis and understanding of the diffusion prior model and believe this opens up new possibilities in diffusion models research.
Cross-Modal Coherence for Text-to-Image Retrieval
Sep 22, 2021

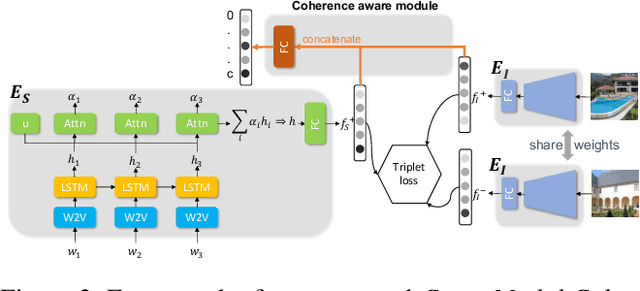

Common image-text joint understanding techniques presume that images and the associated text can universally be characterized by a single implicit model. However, co-occurring images and text can be related in qualitatively different ways, and explicitly modeling it could improve the performance of current joint understanding models. In this paper, we train a Cross-Modal Coherence Modelfor text-to-image retrieval task. Our analysis shows that models trained with image--text coherence relations can retrieve images originally paired with target text more often than coherence-agnostic models. We also show via human evaluation that images retrieved by the proposed coherence-aware model are preferred over a coherence-agnostic baseline by a huge margin. Our findings provide insights into the ways that different modalities communicate and the role of coherence relations in capturing commonsense inferences in text and imagery.
GitEvolve: Predicting the Evolution of GitHub Repositories
Oct 09, 2020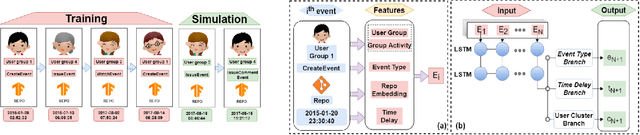
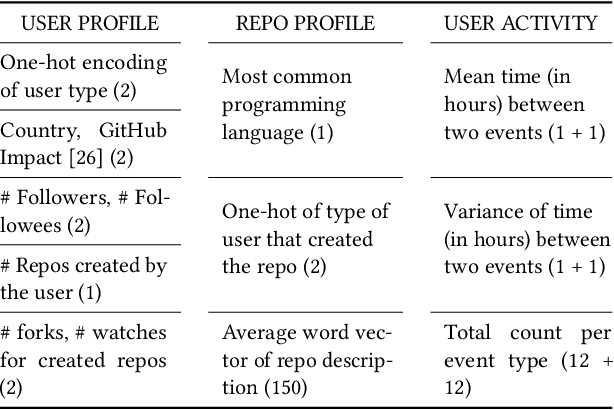
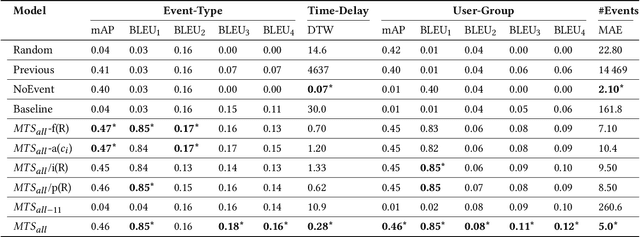
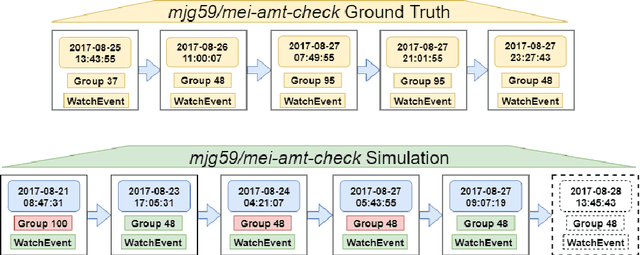
Software development is becoming increasingly open and collaborative with the advent of platforms such as GitHub. Given its crucial role, there is a need to better understand and model the dynamics of GitHub as a social platform. Previous work has mostly considered the dynamics of traditional social networking sites like Twitter and Facebook. We propose GitEvolve, a system to predict the evolution of GitHub repositories and the different ways by which users interact with them. To this end, we develop an end-to-end multi-task sequential deep neural network that given some seed events, simultaneously predicts which user-group is next going to interact with a given repository, what the type of the interaction is, and when it happens. To facilitate learning, we use graph based representation learning to encode relationship between repositories. We map users to groups by modelling common interests to better predict popularity and to generalize to unseen users during inference. We introduce an artificial event type to better model varying levels of activity of repositories in the dataset. The proposed multi-task architecture is generic and can be extended to model information diffusion in other social networks. In a series of experiments, we demonstrate the effectiveness of the proposed model, using multiple metrics and baselines. Qualitative analysis of the model's ability to predict popularity and forecast trends proves its applicability.