 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled and Conditional Text to Image Generation with Diffusion Prior
Feb 23, 2023Denoising Diffusion models have shown remarkable performance in generating diverse, high quality images from text. Numerous techniques have been proposed on top of or in alignment with models like Stable Diffusion and Imagen that generate images directly from text. A lesser explored approach is DALLE-2's two step process comprising a Diffusion Prior that generates a CLIP image embedding from text and a Diffusion Decoder that generates an image from a CLIP image embedding. We explore the capabilities of the Diffusion Prior and the advantages of an intermediate CLIP representation. We observe that Diffusion Prior can be used in a memory and compute efficient way to constrain the generation to a specific domain without altering the larger Diffusion Decoder. Moreover, we show that the Diffusion Prior can be trained with additional conditional information such as color histogram to further control the generation. We show quantitatively and qualitatively that the proposed approaches perform better than prompt engineering for domain specific generation and existing baselines for color conditioned generation. We believe that our observations and results will instigate further research into the diffusion prior and uncover more of its capabilities.
Towards Zero-shot Cross-lingual Image Retrieval and Tagging
Sep 15, 2021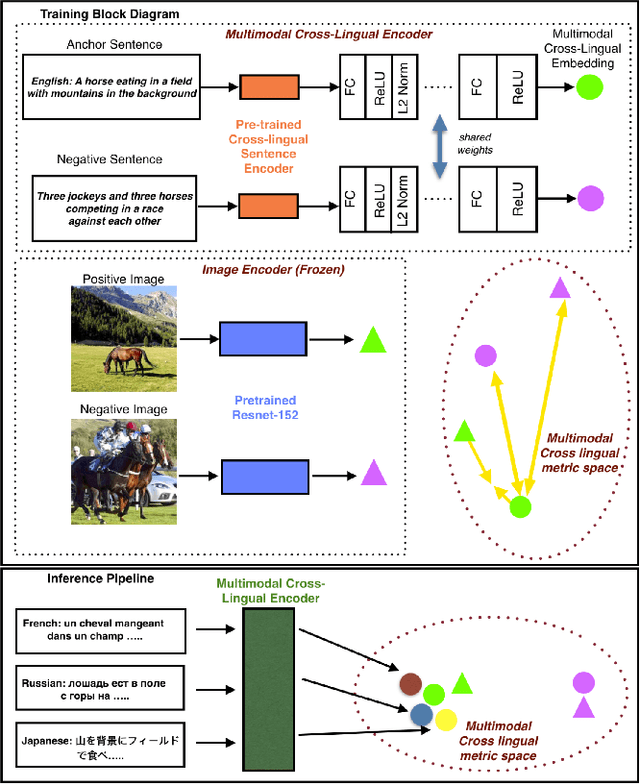
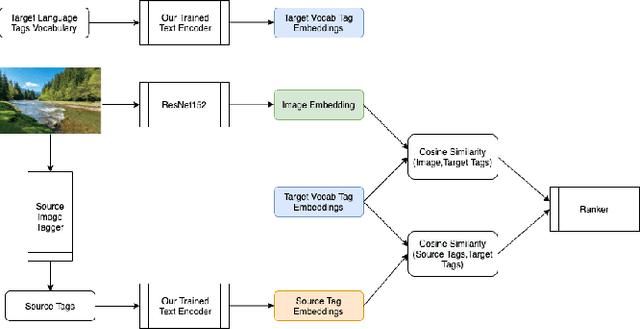
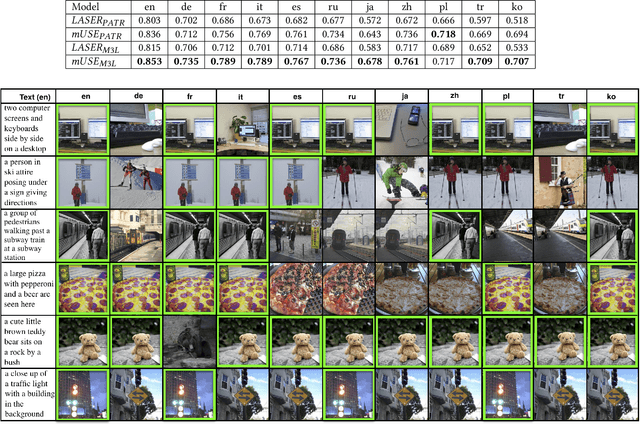
There has been a recent spike in interest in multi-modal Language and Vision problems. On the language side, most of these models primarily focus on English since most multi-modal datasets are monolingual. We try to bridge this gap with a zero-shot approach for learning multi-modal representations using cross-lingual pre-training on the text side. We present a simple yet practical approach for building a cross-lingual image retrieval model which trains on a monolingual training dataset but can be used in a zero-shot cross-lingual fashion during inference. We also introduce a new objective function which tightens the text embedding clusters by pushing dissimilar texts away from each other. For evaluation, we introduce a new 1K multi-lingual MSCOCO2014 caption test dataset (XTD10) in 7 languages that we collected using a crowdsourcing platform. We use this as the test set for zero-shot model performance across languages. We also demonstrate how a cross-lingual model can be used for downstream tasks like multi-lingual image tagging in a zero shot manner. XTD10 dataset is made publicly available here: https://github.com/adobe-research/Cross-lingual-Test-Dataset-XTD10.