 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Disentangled Latent Factors from Paired Data in Cross-Modal Retrieval: An Implicit Identifiable VAE Approach
Paper and Code
Dec 01, 2020
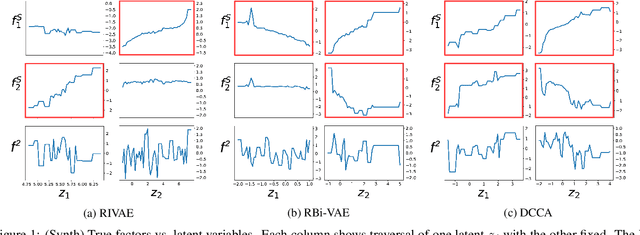


We deal with the problem of learning the underlying disentangled latent factors that are shared between the paired bi-modal data in cross-modal retrieval. Our assumption is that the data in both modalities are complex, structured, and high dimensional (e.g., image and text), for which the conventional deep auto-encoding latent variable models such as the Variational Autoencoder (VAE) often suffer from difficulty of accurate decoder training or realistic synthesis. A suboptimally trained decoder can potentially harm the model's capability of identifying the true factors. In this paper we propose a novel idea of the implicit decoder, which completely removes the ambient data decoding module from a latent variable model, via implicit encoder inversion that is achieved by Jacobian regularization of the low-dimensional embedding function. Motivated from the recent Identifiable VAE (IVAE) model, we modify it to incorporate the query modality data as conditioning auxiliary input, which allows us to prove that the true parameters of the model can be identified under some regularity conditions. Tested on various datasets where the true factors are fully/partially available, our model is shown to identify the factors accurately, significantly outperforming conventional encoder-decoder latent variable models. We also test our model on the Recipe1M, the large-scale food image/recipe dataset, where the learned factors by our approach highly coincide with the most pronounced food factors that are widely agreed on, including savoriness, wateriness, and greenness.