 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges for Responsible AI Design and Workflow Integration in Healthcare: A Case Study of Automatic Feeding Tube Qualification in Radiology
May 08, 2024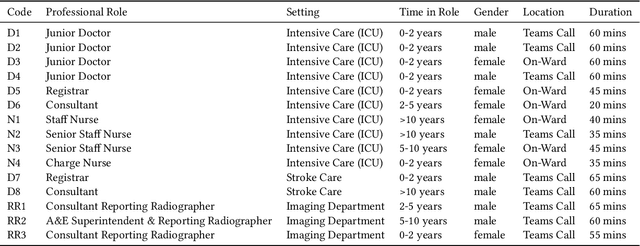


Nasogastric tubes (NGTs) are feeding tubes that are inserted through the nose into the stomach to deliver nutrition or medication. If not placed correctly, they can cause serious harm, even death to patients. Recent AI developments demonstrate the feasibility of robustly detecting NGT placement from Chest X-ray images to reduce risks of sub-optimally or critically placed NGTs being missed or delayed in their detection, but gaps remain in clinical practice integration. In this study, we present a human-centered approach to the problem and describe insights derived following contextual inquiry and in-depth interviews with 15 clinical stakeholders. The interviews helped understand challenges in existing workflows, and how best to align technical capabilities with user needs and expectations. We discovered the trade-offs and complexities that need consideration when choosing suitable workflow stages, target users, and design configurations for different AI proposals. We explored how to balance AI benefits and risks for healthcare staff and patients within broader organizational and medical-legal constraints. We also identified data issues related to edge cases and data biases that affect model training and evaluation; how data documentation practices influence data preparation and labelling; and how to measure relevant AI outcomes reliably in future evaluations. We discuss how our work informs design and development of AI applications that are clinically useful, ethical, and acceptable in real-world healthcare services.
RadEdit: stress-testing biomedical vision models via diffusion image editing
Dec 21, 2023Biomedical imaging datasets are often small and biased, meaning that real-world performance of predictive models can be substantially lower than expected from internal testing. This work proposes using generative image editing to simulate dataset shifts and diagnose failure modes of biomedical vision models; this can be used in advance of deployment to assess readiness, potentially reducing cost and patient harm. Existing editing methods can produce undesirable changes, with spurious correlations learned due to the co-occurrence of disease and treatment interventions, limiting practical applicability. To address this, we train a text-to-image diffusion model on multiple chest X-ray datasets and introduce a new editing method RadEdit that uses multiple masks, if present, to constrain changes and ensure consistency in the edited images. We consider three types of dataset shifts: acquisition shift, manifestation shift, and population shift, and demonstrate that our approach can diagnose failures and quantify model robustness without additional data collection, complementing more qualitative tools for explainable AI.
TRIALSCOPE: A Unifying Causal Framework for Scaling Real-World Evidence Generation with Biomedical Language Models
Nov 06, 2023The rapid digitization of real-world data offers an unprecedented opportunity for optimizing healthcare delivery and accelerating biomedical discovery. In practice, however, such data is most abundantly available in unstructured forms, such as clinical notes in electronic medical records (EMRs), and it is generally plagued by confounders. In this paper, we present TRIALSCOPE, a unifying framework for distilling real-world evidence from population-level observational data. TRIALSCOPE leverages biomedical language models to structure clinical text at scale, employs advanced probabilistic modeling for denoising and imputation, and incorporates state-of-the-art causal inference techniques to combat common confounders. Using clinical trial specification as generic representation, TRIALSCOPE provides a turn-key solution to generate and reason with clinical hypotheses using observational data. In extensive experiments and analyses on a large-scale real-world dataset with over one million cancer patients from a large US healthcare network, we show that TRIALSCOPE can produce high-quality structuring of real-world data and generates comparable results to marquee cancer trials. In addition to facilitating in-silicon clinical trial design and optimization, TRIALSCOPE may be used to empower synthetic controls, pragmatic trials, post-market surveillance, as well as support fine-grained patient-like-me reasoning in precision diagnosis and treatment.
Compositional Zero-Shot Domain Transfer with Text-to-Text Models
Mar 23, 2023Label scarcity is a bottleneck for improving task performance in specialised domains. We propose a novel compositional transfer learning framework (DoT5 - domain compositional zero-shot T5) for zero-shot domain transfer. Without access to in-domain labels, DoT5 jointly learns domain knowledge (from MLM of unlabelled in-domain free text) and task knowledge (from task training on more readily available general-domain data) in a multi-task manner. To improve the transferability of task training, we design a strategy named NLGU: we simultaneously train NLG for in-domain label-to-data generation which enables data augmentation for self-finetuning and NLU for label prediction. We evaluate DoT5 on the biomedical domain and the resource-lean subdomain of radiology, focusing on NLI, text summarisation and embedding learning. DoT5 demonstrates the effectiveness of compositional transfer learning through multi-task learning. In particular, DoT5 outperforms the current SOTA in zero-shot transfer by over 7 absolute points in accuracy on RadNLI. We validate DoT5 with ablations and a case study demonstrating its ability to solve challenging NLI examples requiring in-domain expertise.
Learning to Exploit Temporal Structure for Biomedical Vision-Language Processing
Jan 11, 2023


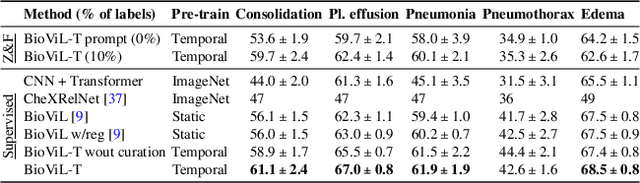
Self-supervised learning in vision-language processing exploits semantic alignment between imaging and text modalities. Prior work in biomedical VLP has mostly relied on the alignment of single image and report pairs even though clinical notes commonly refer to prior images. This does not only introduce poor alignment between the modalities but also a missed opportunity to exploit rich self-supervision through existing temporal content in the data. In this work, we explicitly account for prior images and reports when available during both training and fine-tuning. Our approach, named BioViL-T, uses a CNN-Transformer hybrid multi-image encoder trained jointly with a text model. It is designed to be versatile to arising challenges such as pose variations and missing input images across time. The resulting model excels on downstream tasks both in single- and multi-image setups, achieving state-of-the-art performance on (I) progression classification, (II) phrase grounding, and (III) report generation, whilst offering consistent improvements on disease classification and sentence-similarity tasks. We release a novel multi-modal temporal benchmark dataset, MS-CXR-T, to quantify the quality of vision-language representations in terms of temporal semantics. Our experimental results show the advantages of incorporating prior images and reports to make most use of the data.
Repairing Neural Networks by Leaving the Right Past Behind
Jul 11, 2022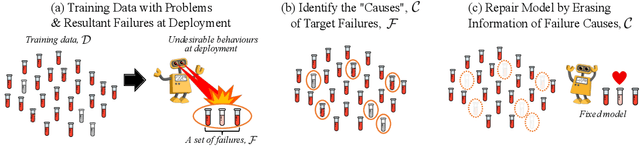
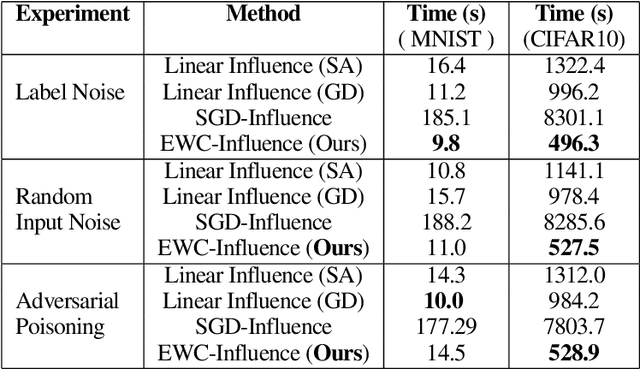
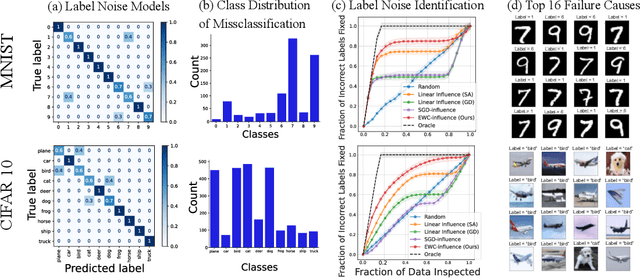
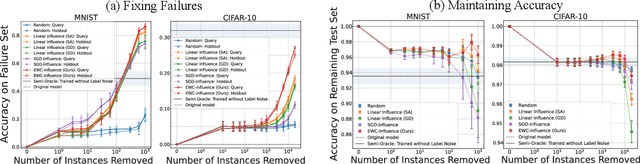
Prediction failures of machine learning models often arise from deficiencies in training data, such as incorrect labels, outliers, and selection biases. However, such data points that are responsible for a given failure mode are generally not known a priori, let alone a mechanism for repairing the failure. This work draws on the Bayesian view of continual learning, and develops a generic framework for both, identifying training examples that have given rise to the target failure, and fixing the model through erasing information about them. This framework naturally allows leveraging recent advances in continual learning to this new problem of model repairment, while subsuming the existing works on influence functions and data deletion as specific instances. Experimentally, the proposed approach outperforms the baselines for both identification of detrimental training data and fixing model failures in a generalisable manner.
Making the Most of Text Semantics to Improve Biomedical Vision--Language Processing
Apr 21, 2022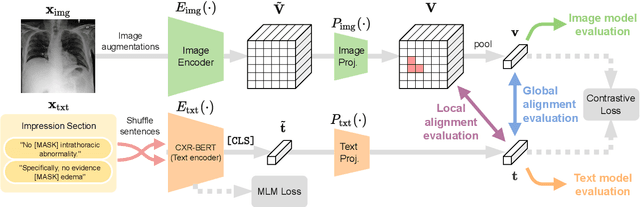

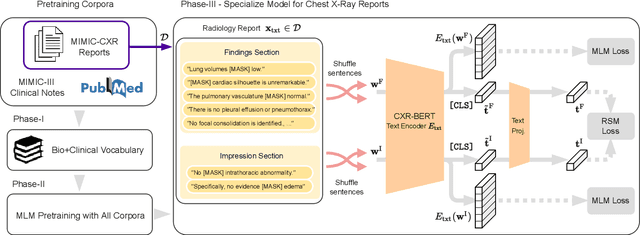

Multi-modal data abounds in biomedicine, such as radiology images and reports. Interpreting this data at scale is essential for improving clinical care and accelerating clinical research. Biomedical text with its complex semantics poses additional challenges in vision-language modelling compared to the general domain, and previous work has used insufficiently adapted models that lack domain-specific language understanding. In this paper, we show that principled textual semantic modelling can substantially improve contrastive learning in self-supervised vision--language processing. We release a language model that achieves state-of-the-art results in radiology natural language inference through its improved vocabulary and novel language pretraining objective leveraging semantics and discourse characteristics in radiology reports. Further, we propose a self-supervised joint vision--language approach with a focus on better text modelling. It establishes new state of the art results on a wide range of publicly available benchmarks, in part by leveraging our new domain-specific language model. We release a new dataset with locally-aligned phrase grounding annotations by radiologists to facilitate the study of complex semantic modelling in biomedical vision--language processing. A broad evaluation, including on this new dataset, shows that our contrastive learning approach, aided by textual-semantic modelling, outperforms prior methods in segmentation tasks, despite only using a global-alignment objective.
Active label cleaning: Improving dataset quality under resource constraints
Sep 01, 2021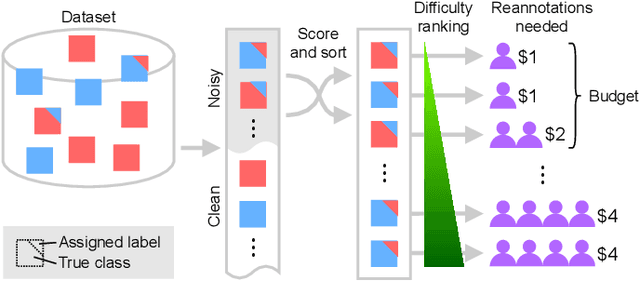
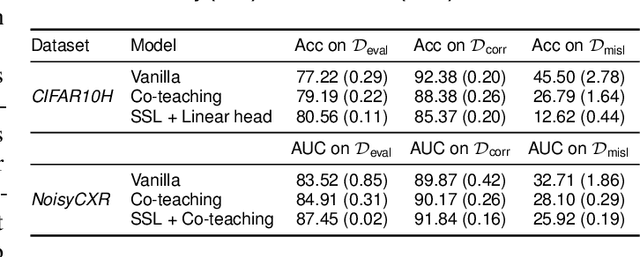
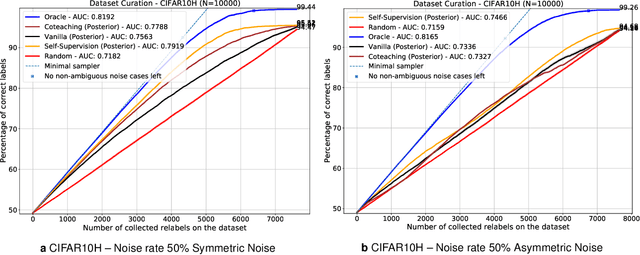
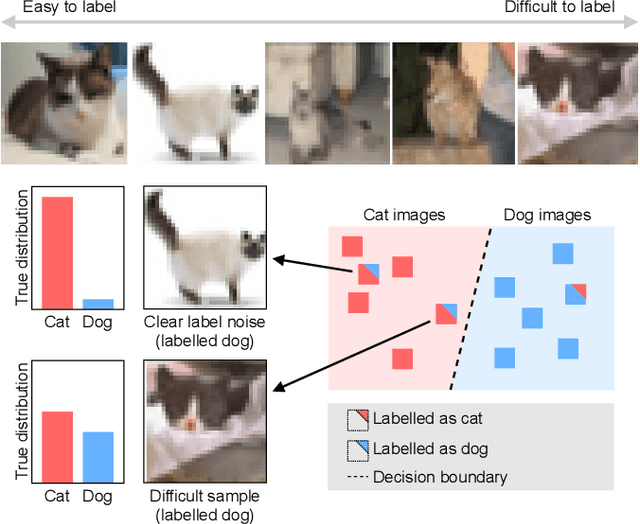
Imperfections in data annotation, known as label noise, are detrimental to the training of machine learning models and have an often-overlooked confounding effect on the assessment of model performance. Nevertheless, employing experts to remove label noise by fully re-annotating large datasets is infeasible in resource-constrained settings, such as healthcare. This work advocates for a data-driven approach to prioritising samples for re-annotation - which we term "active label cleaning". We propose to rank instances according to estimated label correctness and labelling difficulty of each sample, and introduce a simulation framework to evaluate relabelling efficacy. Our experiments on natural images and on a new medical imaging benchmark show that cleaning noisy labels mitigates their negative impact on model training, evaluation, and selection. Crucially, the proposed active label cleaning enables correcting labels up to 4 times more effectively than typical random selection in realistic conditions, making better use of experts' valuable time for improving dataset quality.
Hierarchical Analysis of Visual COVID-19 Features from Chest Radiographs
Jul 14, 2021

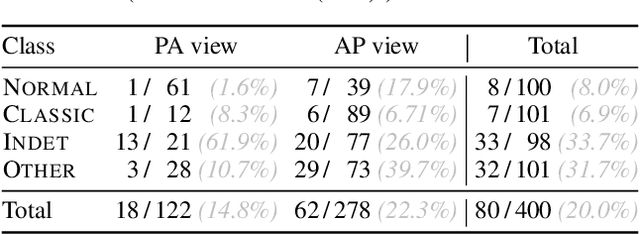

Chest radiography has been a recommended procedure for patient triaging and resource management in intensive care units (ICUs) throughout the COVID-19 pandemic. The machine learning efforts to augment this workflow have been long challenged due to deficiencies in reporting, model evaluation, and failure mode analysis. To address some of those shortcomings, we model radiological features with a human-interpretable class hierarchy that aligns with the radiological decision process. Also, we propose the use of a data-driven error analysis methodology to uncover the blind spots of our model, providing further transparency on its clinical utility. For example, our experiments show that model failures highly correlate with ICU imaging conditions and with the inherent difficulty in distinguishing certain types of radiological features. Also, our hierarchical interpretation and analysis facilitates the comparison with respect to radiologists' findings and inter-variability, which in return helps us to better assess the clinical applicability of models.
Alleviating Privacy Attacks via Causal Learning
Sep 27, 2019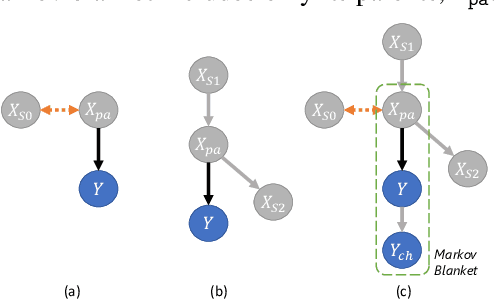



Machine learning models, especially deep neural networks have been shown to reveal membership information of inputs in the training data. Such membership inference attacks are a serious privacy concern, for example, patients providing medical records to build a model that detects HIV would not want their identity to be leaked. Further, we show that the attack accuracy amplifies when the model is used to predict samples that come from a different distribution than the training set, which is often the case in real world applications. Therefore, we propose the use of causal learning approaches where a model learns the causal relationship between the input features and the outcome. Causal models are known to be invariant to the training distribution and hence generalize well to shifts between samples from the same distribution and across different distributions. First, we prove that models learned using causal structure provide stronger differential privacy guarantees than associational models under reasonable assumptions. Next, we show that causal models trained on sufficiently large samples are robust to membership inference attacks across different distributions of datasets and those trained on smaller sample sizes always have lower attack accuracy than corresponding associational models. Finally, we confirm our theoretical claims with experimental evaluation on $4$ datasets with moderately complex Bayesian networks. We observe that neural network-based associational models exhibit up to 80% attack accuracy under different test distributions and sample sizes whereas causal models exhibit attack accuracy close to a random guess. Our results confirm the value of the generalizability of causal models in reducing susceptibility to privacy attacks.