 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Scaling Laws for Radiology Foundation Models
Sep 16, 2025Foundation vision encoders such as CLIP and DINOv2, trained on web-scale data, exhibit strong transfer performance across tasks and datasets. However, medical imaging foundation models remain constrained by smaller datasets, limiting our understanding of how data scale and pretraining paradigms affect performance in this setting. In this work, we systematically study continual pretraining of two vision encoders, MedImageInsight (MI2) and RAD-DINO representing the two major encoder paradigms CLIP and DINOv2, on up to 3.5M chest x-rays from a single institution, holding compute and evaluation protocols constant. We evaluate on classification (radiology findings, lines and tubes), segmentation (lines and tubes), and radiology report generation. While prior work has primarily focused on tasks related to radiology findings, we include lines and tubes tasks to counterbalance this bias and evaluate a model's ability to extract features that preserve continuity along elongated structures. Our experiments show that MI2 scales more effectively for finding-related tasks, while RAD-DINO is stronger on tube-related tasks. Surprisingly, continually pretraining MI2 with both reports and structured labels using UniCL improves performance, underscoring the value of structured supervision at scale. We further show that for some tasks, as few as 30k in-domain samples are sufficient to surpass open-weights foundation models. These results highlight the utility of center-specific continual pretraining, enabling medical institutions to derive significant performance gains by utilizing in-domain data.
MAIRA-Seg: Enhancing Radiology Report Generation with Segmentation-Aware Multimodal Large Language Models
Nov 18, 2024



There is growing interest in applying AI to radiology report generation, particularly for chest X-rays (CXRs). This paper investigates whether incorporating pixel-level information through segmentation masks can improve fine-grained image interpretation of multimodal large language models (MLLMs) for radiology report generation. We introduce MAIRA-Seg, a segmentation-aware MLLM framework designed to utilize semantic segmentation masks alongside CXRs for generating radiology reports. We train expert segmentation models to obtain mask pseudolabels for radiology-specific structures in CXRs. Subsequently, building on the architectures of MAIRA, a CXR-specialised model for report generation, we integrate a trainable segmentation tokens extractor that leverages these mask pseudolabels, and employ mask-aware prompting to generate draft radiology reports. Our experiments on the publicly available MIMIC-CXR dataset show that MAIRA-Seg outperforms non-segmentation baselines. We also investigate set-of-marks prompting with MAIRA and find that MAIRA-Seg consistently demonstrates comparable or superior performance. The results confirm that using segmentation masks enhances the nuanced reasoning of MLLMs, potentially contributing to better clinical outcomes.
MAIRA-2: Grounded Radiology Report Generation
Jun 06, 2024



Radiology reporting is a complex task that requires detailed image understanding, integration of multiple inputs, including comparison with prior imaging, and precise language generation. This makes it ideal for the development and use of generative multimodal models. Here, we extend report generation to include the localisation of individual findings on the image - a task we call grounded report generation. Prior work indicates that grounding is important for clarifying image understanding and interpreting AI-generated text. Therefore, grounded reporting stands to improve the utility and transparency of automated report drafting. To enable evaluation of grounded reporting, we propose a novel evaluation framework - RadFact - leveraging the reasoning capabilities of large language models (LLMs). RadFact assesses the factuality of individual generated sentences, as well as correctness of generated spatial localisations when present. We introduce MAIRA-2, a large multimodal model combining a radiology-specific image encoder with a LLM, and trained for the new task of grounded report generation on chest X-rays. MAIRA-2 uses more comprehensive inputs than explored previously: the current frontal image, the current lateral image, the prior frontal image and prior report, as well as the Indication, Technique and Comparison sections of the current report. We demonstrate that these additions significantly improve report quality and reduce hallucinations, establishing a new state of the art on findings generation (without grounding) on MIMIC-CXR while demonstrating the feasibility of grounded reporting as a novel and richer task.
RAD-DINO: Exploring Scalable Medical Image Encoders Beyond Text Supervision
Jan 19, 2024Language-supervised pre-training has proven to be a valuable method for extracting semantically meaningful features from images, serving as a foundational element in multimodal systems within the computer vision and medical imaging domains. However, resulting features are limited by the information contained within the text. This is particularly problematic in medical imaging, where radiologists' written findings focus on specific observations; a challenge compounded by the scarcity of paired imaging-text data due to concerns over leakage of personal health information. In this work, we fundamentally challenge the prevailing reliance on language supervision for learning general purpose biomedical imaging encoders. We introduce RAD-DINO, a biomedical image encoder pre-trained solely on unimodal biomedical imaging data that obtains similar or greater performance than state-of-the-art biomedical language supervised models on a diverse range of benchmarks. Specifically, the quality of learned representations is evaluated on standard imaging tasks (classification and semantic segmentation), and a vision-language alignment task (text report generation from images). To further demonstrate the drawback of language supervision, we show that features from RAD-DINO correlate with other medical records (e.g., sex or age) better than language-supervised models, which are generally not mentioned in radiology reports. Finally, we conduct a series of ablations determining the factors in RAD-DINO's performance; notably, we observe that RAD-DINO's downstream performance scales well with the quantity and diversity of training data, demonstrating that image-only supervision is a scalable approach for training a foundational biomedical image encoder.
RadEdit: stress-testing biomedical vision models via diffusion image editing
Dec 21, 2023Biomedical imaging datasets are often small and biased, meaning that real-world performance of predictive models can be substantially lower than expected from internal testing. This work proposes using generative image editing to simulate dataset shifts and diagnose failure modes of biomedical vision models; this can be used in advance of deployment to assess readiness, potentially reducing cost and patient harm. Existing editing methods can produce undesirable changes, with spurious correlations learned due to the co-occurrence of disease and treatment interventions, limiting practical applicability. To address this, we train a text-to-image diffusion model on multiple chest X-ray datasets and introduce a new editing method RadEdit that uses multiple masks, if present, to constrain changes and ensure consistency in the edited images. We consider three types of dataset shifts: acquisition shift, manifestation shift, and population shift, and demonstrate that our approach can diagnose failures and quantify model robustness without additional data collection, complementing more qualitative tools for explainable AI.
MAIRA-1: A specialised large multimodal model for radiology report generation
Nov 22, 2023



We present a radiology-specific multimodal model for the task for generating radiological reports from chest X-rays (CXRs). Our work builds on the idea that large language model(s) can be equipped with multimodal capabilities through alignment with pre-trained vision encoders. On natural images, this has been shown to allow multimodal models to gain image understanding and description capabilities. Our proposed model (MAIRA-1) leverages a CXR-specific image encoder in conjunction with a fine-tuned large language model based on Vicuna-7B, and text-based data augmentation, to produce reports with state-of-the-art quality. In particular, MAIRA-1 significantly improves on the radiologist-aligned RadCliQ metric and across all lexical metrics considered. Manual review of model outputs demonstrates promising fluency and accuracy of generated reports while uncovering failure modes not captured by existing evaluation practices. More information and resources can be found on the project website: https://aka.ms/maira.
Exploring the Limits of Synthetic Creation of Solar EUV Images via Image-to-Image Translation
Aug 19, 2022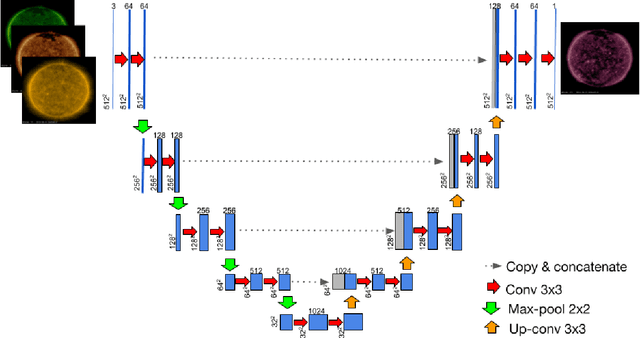
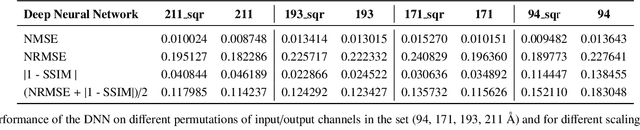

The Solar Dynamics Observatory (SDO), a NASA multi-spectral decade-long mission that has been daily producing terabytes of observational data from the Sun, has been recently used as a use-case to demonstrate the potential of machine learning methodologies and to pave the way for future deep-space mission planning. In particular, the idea of using image-to-image translation to virtually produce extreme ultra-violet channels has been proposed in several recent studies, as a way to both enhance missions with less available channels and to alleviate the challenges due to the low downlink rate in deep space. This paper investigates the potential and the limitations of such a deep learning approach by focusing on the permutation of four channels and an encoder--decoder based architecture, with particular attention to how morphological traits and brightness of the solar surface affect the neural network predictions. In this work we want to answer the question: can synthetic images of the solar corona produced via image-to-image translation be used for scientific studies of the Sun? The analysis highlights that the neural network produces high-quality images over three orders of magnitude in count rate (pixel intensity) and can generally reproduce the covariance across channels within a 1% error. However the model performance drastically diminishes in correspondence of extremely high energetic events like flares, and we argue that the reason is related to the rareness of such events posing a challenge to model training.
Unsupervised Change Detection of Extreme Events Using ML On-Board
Nov 04, 2021
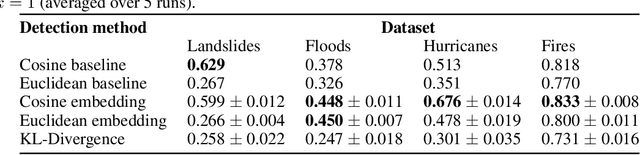

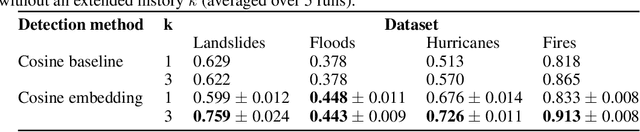
In this paper, we introduce RaVAEn, a lightweight, unsupervised approach for change detection in satellite data based on Variational Auto-Encoders (VAEs) with the specific purpose of on-board deployment. Applications such as disaster management enormously benefit from the rapid availability of satellite observations. Traditionally, data analysis is performed on the ground after all data is transferred - downlinked - to a ground station. Constraint on the downlink capabilities therefore affects any downstream application. In contrast, RaVAEn pre-processes the sampled data directly on the satellite and flags changed areas to prioritise for downlink, shortening the response time. We verified the efficacy of our system on a dataset composed of time series of catastrophic events - which we plan to release alongside this publication - demonstrating that RaVAEn outperforms pixel-wise baselines. Finally we tested our approach on resource-limited hardware for assessing computational and memory limitations.
Multi-Channel Auto-Calibration for the Atmospheric Imaging Assembly using Machine Learning
Feb 01, 2021
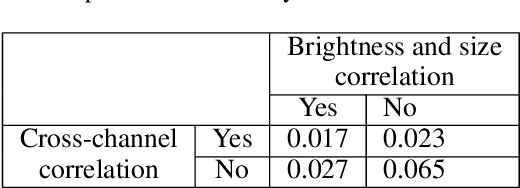

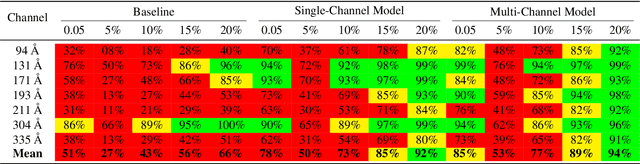
Solar activity plays a quintessential role in influencing the interplanetary medium and space-weather around the Earth. Remote sensing instruments onboard heliophysics space missions provide a pool of information about the Sun's activity via the measurement of its magnetic field and the emission of light from the multi-layered, multi-thermal, and dynamic solar atmosphere. Extreme UV (EUV) wavelength observations from space help in understanding the subtleties of the outer layers of the Sun, namely the chromosphere and the corona. Unfortunately, such instruments, like the Atmospheric Imaging Assembly (AIA) onboard NASA's Solar Dynamics Observatory (SDO), suffer from time-dependent degradation, reducing their sensitivity. Current state-of-the-art calibration techniques rely on periodic sounding rockets, which can be infrequent and rather unfeasible for deep-space missions. We present an alternative calibration approach based on convolutional neural networks (CNNs). We use SDO-AIA data for our analysis. Our results show that CNN-based models could comprehensively reproduce the sounding rocket experiments' outcomes within a reasonable degree of accuracy, indicating that it performs equally well compared with the current techniques. Furthermore, a comparison with a standard "astronomer's technique" baseline model reveals that the CNN approach significantly outperforms this baseline. Our approach establishes the framework for a novel technique to calibrate EUV instruments and advance our understanding of the cross-channel relation between different EUV channels.
Auto-Calibration of Remote Sensing Solar Telescopes with Deep Learning
Nov 10, 2019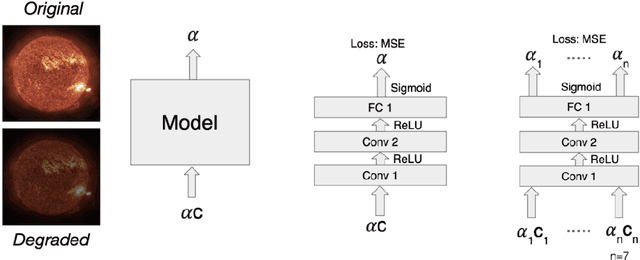
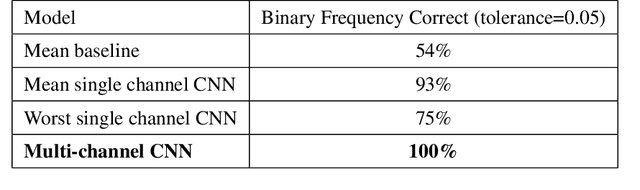

As a part of NASA's Heliophysics System Observatory (HSO) fleet of satellites,the Solar Dynamics Observatory (SDO) has continuously monitored the Sun since2010. Ultraviolet (UV) and Extreme UV (EUV) instruments in orbit, such asSDO's Atmospheric Imaging Assembly (AIA) instrument, suffer time-dependent degradation which reduces instrument sensitivity. Accurate calibration for (E)UV instruments currently depends on periodic sounding rockets, which are infrequent and not practical for heliophysics missions in deep space. In the present work, we develop a Convolutional Neural Network (CNN) that auto-calibrates SDO/AIA channels and corrects sensitivity degradation by exploiting spatial patterns in multi-wavelength observations to arrive at a self-calibration of (E)UV imaging instruments. Our results remove a major impediment to developing future HSOmissions of the same scientific caliber as SDO but in deep space, able to observe the Sun from more vantage points than just SDO's current geosynchronous orbit.This approach can be adopted to perform autocalibration of other imaging systems exhibiting similar forms of degradation