 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB-only Active 3D Scene Graph Generation for Indoor Mobile Robots
May 18, 2026Current approaches to 3D scene graph generation rely on dedicated depth sensors, such as LiDAR or RGB-D cameras, for metric 3D reconstruction. This limits deployment to specialized robotic platforms and excludes settings where only RGB cameras are available, such as fixed external infrastructure. Existing pipelines also typically operate on passively collected observation trajectories, rather than selecting viewpoints based on the partially built scene representation, and therefore fail to effectively exploit the semantic and spatial information encoded within the graph during exploration. This paper presents a fully visual framework for the active, incremental construction of 3D scene graphs from RGB input only, addressing both limitations. The proposed approach unifies perception and planning around a shared structured representation that captures object semantics, 3D geometry, relational context, and information from multiple viewpoints. Because the framework is hardware-agnostic and relies only on RGB observations, it can incorporate inputs from both onboard robot cameras and fixed external cameras within the same representation. Experiments on the Replica dataset show that the RGB-only pipeline achieves F1-score parity with baselines using ground-truth depth. Active exploration experiments on ReplicaCAD further show that semantic-driven viewpoint selection detects more than twice as many objects as a geometric frontier-based baseline under the same exploration budget. Finally, the external-camera setting demonstrates that complementary RGB views can effectively bootstrap the scene graph and improve contextual understanding at no additional exploration cost.
Fixed External Cameras as Common Prior Maps for Active 3D Scene Graph Generation
May 18, 2026Commonly available prior information, such as BIM models, floor plans, and remote sensing images, can provide valuable geometric and semantic context for autonomous robotic systems. In this paper, we treat observations from fixed external RGB cameras as Common Prior Maps (CPMs): wide-field views of the environment that initialize a semantic and geometric scene prior before any robot motion begins. We present an RGB-only framework for active, incremental 3D scene graph (3DSG) generation that seamlessly fuses observations from both onboard robot cameras and fixed external cameras within a single hardware-agnostic pipeline. By relying solely on RGB observations processed by a feed-forward 3D reconstruction model, the system treats all cameras - onboard or external - identically, requiring no hardware modifications. A graph-based active semantic exploration framework then directly leverages the partial scene graph to guide the robot toward regions of high semantic uncertainty, progressively completing and refining the prior. Experiments demonstrate that bootstrapping the scene graph with even a single external camera increases initial object recall by up to +79%, and that the richer context of the prior significantly improves the efficiency of subsequent active exploration.
3D Foundation Model-Based Loop Closing for Decentralized Collaborative SLAM
Feb 02, 2026Decentralized Collaborative Simultaneous Localization And Mapping (C-SLAM) techniques often struggle to identify map overlaps due to significant viewpoint variations among robots. Motivated by recent advancements in 3D foundation models, which can register images despite large viewpoint differences, we propose a robust loop closing approach that leverages these models to establish inter-robot measurements. In contrast to resource-intensive methods requiring full 3D reconstruction within a centralized map, our approach integrates foundation models into existing SLAM pipelines, yielding scalable and robust multi-robot mapping. Our contributions include: (1) integrating 3D foundation models to reliably estimate relative poses from monocular image pairs within decentralized C-SLAM; (2) introducing robust outlier mitigation techniques critical to the use of these relative poses; and (3) developing specialized pose graph optimization formulations that efficiently resolve scale ambiguities. We evaluate our method against state-of-the-art approaches, demonstrating improvements in localization and mapping accuracy, alongside significant gains in computational and memory efficiency. These results highlight the potential of our approach for deployment in large-scale multi-robot scenarios.
Introspection in Learned Semantic Scene Graph Localisation
Oct 08, 2025This work investigates how semantics influence localisation performance and robustness in a learned self-supervised, contrastive semantic localisation framework. After training a localisation network on both original and perturbed maps, we conduct a thorough post-hoc introspection analysis to probe whether the model filters environmental noise and prioritises distinctive landmarks over routine clutter. We validate various interpretability methods and present a comparative reliability analysis. Integrated gradients and Attention Weights consistently emerge as the most reliable probes of learned behaviour. A semantic class ablation further reveals an implicit weighting in which frequent objects are often down-weighted. Overall, the results indicate that the model learns noise-robust, semantically salient relations about place definition, thereby enabling explainable registration under challenging visual and structural variations.
Ensemble of Pre-Trained Models for Long-Tailed Trajectory Prediction
Sep 17, 2025This work explores the application of ensemble modeling to the multidimensional regression problem of trajectory prediction for vehicles in urban environments. As newer and bigger state-of-the-art prediction models for autonomous driving continue to emerge, an important open challenge is the problem of how to combine the strengths of these big models without the need for costly re-training. We show how, perhaps surprisingly, combining state-of-the-art deep learning models out-of-the-box (without retraining or fine-tuning) with a simple confidence-weighted average method can enhance the overall prediction. Indeed, while combining trajectory prediction models is not straightforward, this simple approach enhances performance by 10% over the best prediction model, especially in the long-tailed metrics. We show that this performance improvement holds on both the NuScenes and Argoverse datasets, and that these improvements are made across the dataset distribution. The code for our work is open source.
MinkOcc: Towards real-time label-efficient semantic occupancy prediction
Apr 03, 2025



Developing 3D semantic occupancy prediction models often relies on dense 3D annotations for supervised learning, a process that is both labor and resource-intensive, underscoring the need for label-efficient or even label-free approaches. To address this, we introduce MinkOcc, a multi-modal 3D semantic occupancy prediction framework for cameras and LiDARs that proposes a two-step semi-supervised training procedure. Here, a small dataset of explicitly 3D annotations warm-starts the training process; then, the supervision is continued by simpler-to-annotate accumulated LiDAR sweeps and images -- semantically labelled through vision foundational models. MinkOcc effectively utilizes these sensor-rich supervisory cues and reduces reliance on manual labeling by 90\% while maintaining competitive accuracy. In addition, the proposed model incorporates information from LiDAR and camera data through early fusion and leverages sparse convolution networks for real-time prediction. With its efficiency in both supervision and computation, we aim to extend MinkOcc beyond curated datasets, enabling broader real-world deployment of 3D semantic occupancy prediction in autonomous driving.
Task-Oriented Co-Design of Communication, Computing, and Control for Edge-Enabled Industrial Cyber-Physical Systems
Mar 11, 2025This paper proposes a task-oriented co-design framework that integrates communication, computing, and control to address the key challenges of bandwidth limitations, noise interference, and latency in mission-critical industrial Cyber-Physical Systems (CPS). To improve communication efficiency and robustness, we design a task-oriented Joint Source-Channel Coding (JSCC) using Information Bottleneck (IB) to enhance data transmission efficiency by prioritizing task-specific information. To mitigate the perceived End-to-End (E2E) delays, we develop a Delay-Aware Trajectory-Guided Control Prediction (DTCP) strategy that integrates trajectory planning with control prediction, predicting commands based on E2E delay. Moreover, the DTCP is co-designed with task-oriented JSCC, focusing on transmitting task-specific information for timely and reliable autonomous driving. Experimental results in the CARLA simulator demonstrate that, under an E2E delay of 1 second (20 time slots), the proposed framework achieves a driving score of 48.12, which is 31.59 points higher than using Better Portable Graphics (BPG) while reducing bandwidth usage by 99.19%.
Tiny Lidars for Manipulator Self-Awareness: Sensor Characterization and Initial Localization Experiments
Mar 05, 2025For several tasks, ranging from manipulation to inspection, it is beneficial for robots to localize a target object in their surroundings. In this paper, we propose an approach that utilizes coarse point clouds obtained from miniaturized VL53L5CX Time-of-Flight (ToF) sensors (tiny lidars) to localize a target object in the robot's workspace. We first conduct an experimental campaign to calibrate the dependency of sensor readings on relative range and orientation to targets. We then propose a probabilistic sensor model that is validated in an object pose estimation task using a Particle Filter (PF). The results show that the proposed sensor model improves the performance of the localization of the target object with respect to two baselines: one that assumes measurements are free from uncertainty and one in which the confidence is provided by the sensor datasheet.
Select2Plan: Training-Free ICL-Based Planning through VQA and Memory Retrieval
Nov 06, 2024This study explores the potential of off-the-shelf Vision-Language Models (VLMs) for high-level robot planning in the context of autonomous navigation. Indeed, while most of existing learning-based approaches for path planning require extensive task-specific training/fine-tuning, we demonstrate how such training can be avoided for most practical cases. To do this, we introduce Select2Plan (S2P), a novel training-free framework for high-level robot planning which completely eliminates the need for fine-tuning or specialised training. By leveraging structured Visual Question-Answering (VQA) and In-Context Learning (ICL), our approach drastically reduces the need for data collection, requiring a fraction of the task-specific data typically used by trained models, or even relying only on online data. Our method facilitates the effective use of a generally trained VLM in a flexible and cost-efficient way, and does not require additional sensing except for a simple monocular camera. We demonstrate its adaptability across various scene types, context sources, and sensing setups. We evaluate our approach in two distinct scenarios: traditional First-Person View (FPV) and infrastructure-driven Third-Person View (TPV) navigation, demonstrating the flexibility and simplicity of our method. Our technique significantly enhances the navigational capabilities of a baseline VLM of approximately 50% in TPV scenario, and is comparable to trained models in the FPV one, with as few as 20 demonstrations.
CERES: Critical-Event Reconstruction via Temporal Scene Graph Completion
Oct 17, 2024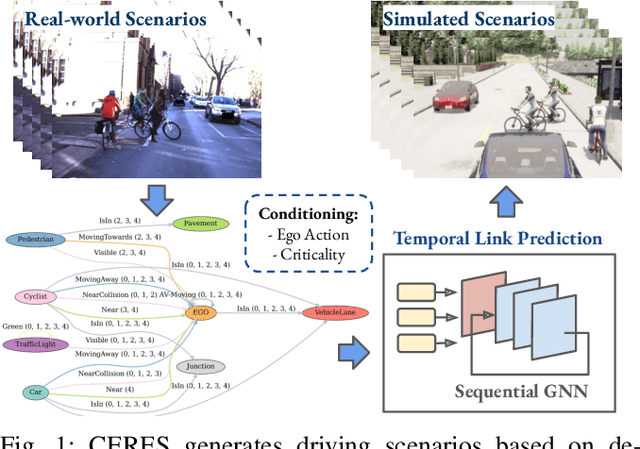

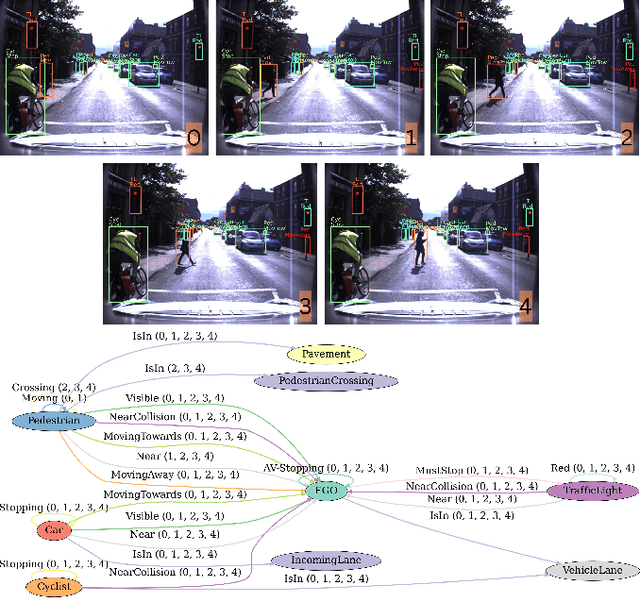

This paper proposes a method for on-demand scenario generation in simulation, grounded on real-world data. Evaluating the behaviour of Autonomous Vehicles (AVs) in both safety-critical and regular scenarios is essential for assessing their robustness before real-world deployment. By integrating scenarios derived from real-world datasets into the simulation, we enhance the plausibility and validity of testing sets. This work introduces a novel approach that employs temporal scene graphs to capture evolving spatiotemporal relationships among scene entities from a real-world dataset, enabling the generation of dynamic scenarios in simulation through Graph Neural Networks (GNNs). User-defined action and criticality conditioning are used to ensure flexible, tailored scenario creation. Our model significantly outperforms the benchmarks in accurately predicting links corresponding to the requested scenarios. We further evaluate the validity and compatibility of our generated scenarios in an off-the-shelf simulator.