 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatching Grass Grow: Long-term Visual Navigation and Mission Planning for Autonomous Biodiversity Monitoring
Apr 16, 2024



We describe a challenging robotics deployment in a complex ecosystem to monitor a rich plant community. The study site is dominated by dynamic grassland vegetation and is thus visually ambiguous and liable to drastic appearance change over the course of a day and especially through the growing season. This dynamism and complexity in appearance seriously impact the stability of the robotics platform, as localisation is a foundational part of that control loop, and so routes must be carefully taught and retaught until autonomy is robust and repeatable. Our system is demonstrated over a 6-week period monitoring the response of grass species to experimental climate change manipulations. We also discuss the applicability of our pipeline to monitor biodiversity in other complex natural settings.
VDNA-PR: Using General Dataset Representations for Robust Sequential Visual Place Recognition
Mar 14, 2024This paper adapts a general dataset representation technique to produce robust Visual Place Recognition (VPR) descriptors, crucial to enable real-world mobile robot localisation. Two parallel lines of work on VPR have shown, on one side, that general-purpose off-the-shelf feature representations can provide robustness to domain shifts, and, on the other, that fused information from sequences of images improves performance. In our recent work on measuring domain gaps between image datasets, we proposed a Visual Distribution of Neuron Activations (VDNA) representation to represent datasets of images. This representation can naturally handle image sequences and provides a general and granular feature representation derived from a general-purpose model. Moreover, our representation is based on tracking neuron activation values over the list of images to represent and is not limited to a particular neural network layer, therefore having access to high- and low-level concepts. This work shows how VDNAs can be used for VPR by learning a very lightweight and simple encoder to generate task-specific descriptors. Our experiments show that our representation can allow for better robustness than current solutions to serious domain shifts away from the training data distribution, such as to indoor environments and aerial imagery.
That's My Point: Compact Object-centric LiDAR Pose Estimation for Large-scale Outdoor Localisation
Mar 07, 2024This paper is about 3D pose estimation on LiDAR scans with extremely minimal storage requirements to enable scalable mapping and localisation. We achieve this by clustering all points of segmented scans into semantic objects and representing them only with their respective centroid and semantic class. In this way, each LiDAR scan is reduced to a compact collection of four-number vectors. This abstracts away important structural information from the scenes, which is crucial for traditional registration approaches. To mitigate this, we introduce an object-matching network based on self- and cross-correlation that captures geometric and semantic relationships between entities. The respective matches allow us to recover the relative transformation between scans through weighted Singular Value Decomposition (SVD) and RANdom SAmple Consensus (RANSAC). We demonstrate that such representation is sufficient for metric localisation by registering point clouds taken under different viewpoints on the KITTI dataset, and at different periods of time localising between KITTI and KITTI-360. We achieve accurate metric estimates comparable with state-of-the-art methods with almost half the representation size, specifically 1.33 kB on average.
OORD: The Oxford Offroad Radar Dataset
Mar 05, 2024There is a growing academic interest as well as commercial exploitation of millimetre-wave scanning radar for autonomous vehicle localisation and scene understanding. Although several datasets to support this research area have been released, they are primarily focused on urban or semi-urban environments. Nevertheless, rugged offroad deployments are important application areas which also present unique challenges and opportunities for this sensor technology. Therefore, the Oxford Offroad Radar Dataset (OORD) presents data collected in the rugged Scottish highlands in extreme weather. The radar data we offer to the community are accompanied by GPS/INS reference - to further stimulate research in radar place recognition. In total we release over 90GiB of radar scans as well as GPS and IMU readings by driving a diverse set of four routes over 11 forays, totalling approximately 154km of rugged driving. This is an area increasingly explored in literature, and we therefore present and release examples of recent open-sourced radar place recognition systems and their performance on our dataset. This includes a learned neural network, the weights of which we also release. The data and tools are made freely available to the community at https://oxford-robotics-institute.github.io/oord-dataset.
Masked Gamma-SSL: Learning Uncertainty Estimation via Masked Image Modeling
Feb 27, 2024This work proposes a semantic segmentation network that produces high-quality uncertainty estimates in a single forward pass. We exploit general representations from foundation models and unlabelled datasets through a Masked Image Modeling (MIM) approach, which is robust to augmentation hyper-parameters and simpler than previous techniques. For neural networks used in safety-critical applications, bias in the training data can lead to errors; therefore it is crucial to understand a network's limitations at run time and act accordingly. To this end, we test our proposed method on a number of test domains including the SAX Segmentation benchmark, which includes labelled test data from dense urban, rural and off-road driving domains. The proposed method consistently outperforms uncertainty estimation and Out-of-Distribution (OoD) techniques on this difficult benchmark.
Mitigating Distributional Shift in Semantic Segmentation via Uncertainty Estimation from Unlabelled Data
Feb 27, 2024Knowing when a trained segmentation model is encountering data that is different to its training data is important. Understanding and mitigating the effects of this play an important part in their application from a performance and assurance perspective - this being a safety concern in applications such as autonomous vehicles (AVs). This work presents a segmentation network that can detect errors caused by challenging test domains without any additional annotation in a single forward pass. As annotation costs limit the diversity of labelled datasets, we use easy-to-obtain, uncurated and unlabelled data to learn to perform uncertainty estimation by selectively enforcing consistency over data augmentation. To this end, a novel segmentation benchmark based on the SAX Dataset is used, which includes labelled test data spanning three autonomous-driving domains, ranging in appearance from dense urban to off-road. The proposed method, named Gamma-SSL, consistently outperforms uncertainty estimation and Out-of-Distribution (OoD) techniques on this difficult benchmark - by up to 10.7% in area under the receiver operating characteristic (ROC) curve and 19.2% in area under the precision-recall (PR) curve in the most challenging of the three scenarios.
RAG-Driver: Generalisable Driving Explanations with Retrieval-Augmented In-Context Learning in Multi-Modal Large Language Model
Feb 16, 2024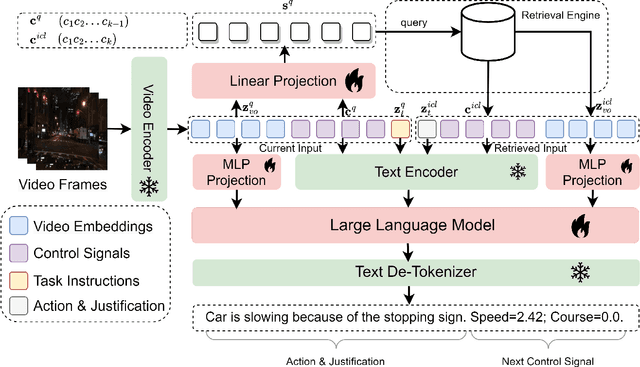
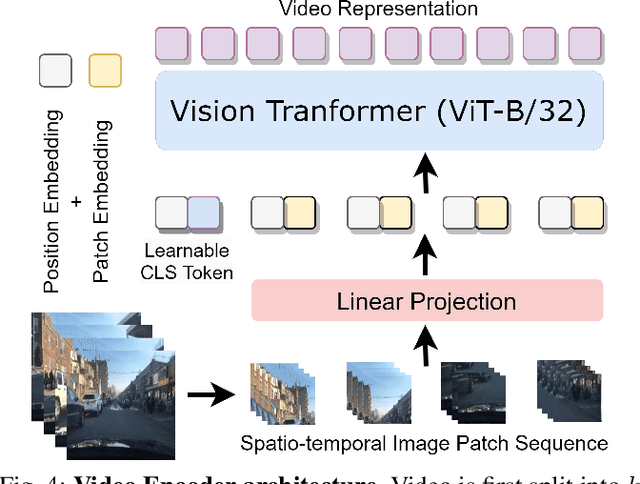


Robots powered by 'blackbox' models need to provide human-understandable explanations which we can trust. Hence, explainability plays a critical role in trustworthy autonomous decision-making to foster transparency and acceptance among end users, especially in complex autonomous driving. Recent advancements in Multi-Modal Large Language models (MLLMs) have shown promising potential in enhancing the explainability as a driving agent by producing control predictions along with natural language explanations. However, severe data scarcity due to expensive annotation costs and significant domain gaps between different datasets makes the development of a robust and generalisable system an extremely challenging task. Moreover, the prohibitively expensive training requirements of MLLM and the unsolved problem of catastrophic forgetting further limit their generalisability post-deployment. To address these challenges, we present RAG-Driver, a novel retrieval-augmented multi-modal large language model that leverages in-context learning for high-performance, explainable, and generalisable autonomous driving. By grounding in retrieved expert demonstration, we empirically validate that RAG-Driver achieves state-of-the-art performance in producing driving action explanations, justifications, and control signal prediction. More importantly, it exhibits exceptional zero-shot generalisation capabilities to unseen environments without further training endeavours.
Open-RadVLAD: Fast and Robust Radar Place Recognition
Jan 27, 2024Radar place recognition often involves encoding a live scan as a vector and matching this vector to a database in order to recognise that the vehicle is in a location that it has visited before. Radar is inherently robust to lighting or weather conditions, but place recognition with this sensor is still affected by: (1) viewpoint variation, i.e. translation and rotation, (2) sensor artefacts or "noises". For 360-degree scanning radar, rotation is readily dealt with by in some way aggregating across azimuths. Also, we argue in this work that it is more critical to deal with the richness of representation and sensor noises than it is to deal with translational invariance - particularly in urban driving where vehicles predominantly follow the same lane when repeating a route. In our method, for computational efficiency, we use only the polar representation. For partial translation invariance and robustness to signal noise, we use only a one-dimensional Fourier Transform along radial returns. We also achieve rotational invariance and a very discriminative descriptor space by building a vector of locally aggregated descriptors. Our method is more comprehensively tested than all prior radar place recognition work - over an exhaustive combination of all 870 pairs of trajectories from 30 Oxford Radar RobotCar Dataset sequences (each approximately 10 km). Code and detailed results are provided at github.com/mttgdd/open-radvlad, as an open implementation and benchmark for future work in this area. We achieve a median of 91.52% in Recall@1, outstripping the 69.55% for the only other open implementation, RaPlace, and at a fraction of its computational cost (relying on fewer integral transforms e.g. Radon, Fourier, and inverse Fourier).
Robot-Relay : Building-Wide, Calibration-Less Visual Servoing with Learned Sensor Handover Network
Oct 24, 2023We present a system which grows and manages a network of remote viewpoints during the natural installation cycle for a newly installed camera network or a newly deployed robot fleet. No explicit notion of camera position or orientation is required, neither global - i.e. relative to a building plan - nor local - i.e. relative to an interesting point in a room. Furthermore, no metric relationship between viewpoints is required. Instead, we leverage our prior work in effective remote control without extrinsic or intrinsic calibration and extend it to the multi-camera setting. In this, we memorise, from simultaneous robot detections in the tracker thread, soft pixel-wise topological connections between viewpoints. We demonstrate our system with repeated autonomous traversals of workspaces connected by a network of six cameras across a productive office environment.
What you see is what you get: Experience ranking with deep neural dataset-to-dataset similarity for topological localisation
Oct 20, 2023Recalling the most relevant visual memories for localisation or understanding a priori the likely outcome of localisation effort against a particular visual memory is useful for efficient and robust visual navigation. Solutions to this problem should be divorced from performance appraisal against ground truth - as this is not available at run-time - and should ideally be based on generalisable environmental observations. For this, we propose applying the recently developed Visual DNA as a highly scalable tool for comparing datasets of images - in this work, sequences of map and live experiences. In the case of localisation, important dataset differences impacting performance are modes of appearance change, including weather, lighting, and season. Specifically, for any deep architecture which is used for place recognition by matching feature volumes at a particular layer, we use distribution measures to compare neuron-wise activation statistics between live images and multiple previously recorded past experiences, with a potentially large seasonal (winter/summer) or time of day (day/night) shift. We find that differences in these statistics correlate to performance when localising using a past experience with the same appearance gap. We validate our approach over the Nordland cross-season dataset as well as data from Oxford's University Parks with lighting and mild seasonal change, showing excellent ability of our system to rank actual localisation performance across candidate experiences.