 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-time Physics Alignment of Video Generative Models with Latent World Models
Jan 15, 2026State-of-the-art video generative models produce promising visual content yet often violate basic physics principles, limiting their utility. While some attribute this deficiency to insufficient physics understanding from pre-training, we find that the shortfall in physics plausibility also stems from suboptimal inference strategies. We therefore introduce WMReward and treat improving physics plausibility of video generation as an inference-time alignment problem. In particular, we leverage the strong physics prior of a latent world model (here, VJEPA-2) as a reward to search and steer multiple candidate denoising trajectories, enabling scaling test-time compute for better generation performance. Empirically, our approach substantially improves physics plausibility across image-conditioned, multiframe-conditioned, and text-conditioned generation settings, with validation from human preference study. Notably, in the ICCV 2025 Perception Test PhysicsIQ Challenge, we achieve a final score of 62.64%, winning first place and outperforming the previous state of the art by 7.42%. Our work demonstrates the viability of using latent world models to improve physics plausibility of video generation, beyond this specific instantiation or parameterization.
Hidden in Plain Sight: Evaluating Abstract Shape Recognition in Vision-Language Models
Nov 09, 2024Despite the importance of shape perception in human vision, early neural image classifiers relied less on shape information for object recognition than other (often spurious) features. While recent research suggests that current large Vision-Language Models (VLMs) exhibit more reliance on shape, we find them to still be seriously limited in this regard. To quantify such limitations, we introduce IllusionBench, a dataset that challenges current cutting-edge VLMs to decipher shape information when the shape is represented by an arrangement of visual elements in a scene. Our extensive evaluations reveal that, while these shapes are easily detectable by human annotators, current VLMs struggle to recognize them, indicating important avenues for future work in developing more robust visual perception systems. The full dataset and codebase are available at: \url{https://arshiahemmat.github.io/illusionbench/}
SpatialBot: Precise Spatial Understanding with Vision Language Models
Jun 19, 2024Vision Language Models (VLMs) have achieved impressive performance in 2D image understanding, however they are still struggling with spatial understanding which is the foundation of Embodied AI. In this paper, we propose SpatialBot for better spatial understanding by feeding both RGB and depth images. Additionally, we have constructed the SpatialQA dataset, which involves multi-level depth-related questions to train VLMs for depth understanding. Finally, we present SpatialBench to comprehensively evaluate VLMs' capabilities in spatial understanding at different levels. Extensive experiments on our spatial-understanding benchmark, general VLM benchmarks and Embodied AI tasks, demonstrate the remarkable improvements of SpatialBot trained on SpatialQA. The model, code and data are available at https://github.com/BAAI-DCAI/SpatialBot.
kNN-CLIP: Retrieval Enables Training-Free Segmentation on Continually Expanding Large Vocabularies
Apr 15, 2024



Rapid advancements in continual segmentation have yet to bridge the gap of scaling to large continually expanding vocabularies under compute-constrained scenarios. We discover that traditional continual training leads to catastrophic forgetting under compute constraints, unable to outperform zero-shot segmentation methods. We introduce a novel strategy for semantic and panoptic segmentation with zero forgetting, capable of adapting to continually growing vocabularies without the need for retraining or large memory costs. Our training-free approach, kNN-CLIP, leverages a database of instance embeddings to enable open-vocabulary segmentation approaches to continually expand their vocabulary on any given domain with a single-pass through data, while only storing embeddings minimizing both compute and memory costs. This method achieves state-of-the-art mIoU performance across large-vocabulary semantic and panoptic segmentation datasets. We hope kNN-CLIP represents a step forward in enabling more efficient and adaptable continual segmentation, paving the way for advances in real-world large-vocabulary continual segmentation methods.
SynArtifact: Classifying and Alleviating Artifacts in Synthetic Images via Vision-Language Model
Mar 05, 2024



In the rapidly evolving area of image synthesis, a serious challenge is the presence of complex artifacts that compromise perceptual realism of synthetic images. To alleviate artifacts and improve quality of synthetic images, we fine-tune Vision-Language Model (VLM) as artifact classifier to automatically identify and classify a wide range of artifacts and provide supervision for further optimizing generative models. Specifically, we develop a comprehensive artifact taxonomy and construct a dataset of synthetic images with artifact annotations for fine-tuning VLM, named SynArtifact-1K. The fine-tuned VLM exhibits superior ability of identifying artifacts and outperforms the baseline by 25.66%. To our knowledge, this is the first time such end-to-end artifact classification task and solution have been proposed. Finally, we leverage the output of VLM as feedback to refine the generative model for alleviating artifacts. Visualization results and user study demonstrate that the quality of images synthesized by the refined diffusion model has been obviously improved.
Efficient Multimodal Learning from Data-centric Perspective
Feb 18, 2024



Multimodal Large Language Models (MLLMs) have demonstrated notable capabilities in general visual understanding and reasoning tasks. However, their deployment is hindered by substantial computational costs in both training and inference, limiting accessibility to the broader research and user communities. A straightforward solution is to leverage smaller pre-trained vision and language models, which inevitably causes significant performance drop. In this paper, we demonstrate the possibility to beat the scaling law and train a smaller but better MLLM by exploring more informative training data. Specifically, we introduce Bunny, a family of lightweight MLLMs with flexible vision and language backbones for efficient multimodal learning from condensed training data. Remarkably, our Bunny-3B outperforms the state-of-the-art large MLLMs, especially LLaVA-v1.5-13B, on multiple benchmarks. The code, models and data can be found in https://github.com/BAAI-DCAI/Bunny.
RAG-Driver: Generalisable Driving Explanations with Retrieval-Augmented In-Context Learning in Multi-Modal Large Language Model
Feb 16, 2024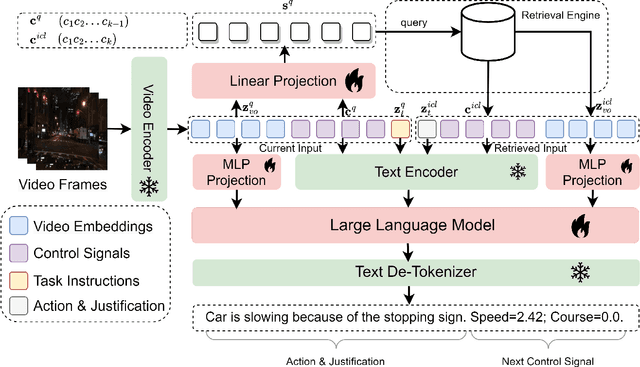
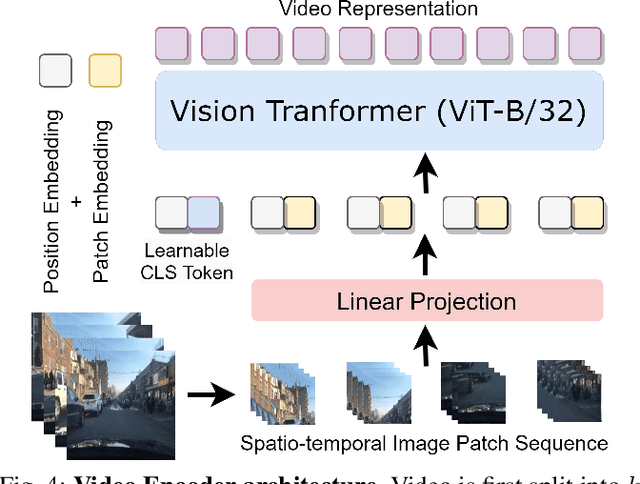


Robots powered by 'blackbox' models need to provide human-understandable explanations which we can trust. Hence, explainability plays a critical role in trustworthy autonomous decision-making to foster transparency and acceptance among end users, especially in complex autonomous driving. Recent advancements in Multi-Modal Large Language models (MLLMs) have shown promising potential in enhancing the explainability as a driving agent by producing control predictions along with natural language explanations. However, severe data scarcity due to expensive annotation costs and significant domain gaps between different datasets makes the development of a robust and generalisable system an extremely challenging task. Moreover, the prohibitively expensive training requirements of MLLM and the unsolved problem of catastrophic forgetting further limit their generalisability post-deployment. To address these challenges, we present RAG-Driver, a novel retrieval-augmented multi-modal large language model that leverages in-context learning for high-performance, explainable, and generalisable autonomous driving. By grounding in retrieved expert demonstration, we empirically validate that RAG-Driver achieves state-of-the-art performance in producing driving action explanations, justifications, and control signal prediction. More importantly, it exhibits exceptional zero-shot generalisation capabilities to unseen environments without further training endeavours.
Real-Fake: Effective Training Data Synthesis Through Distribution Matching
Oct 16, 2023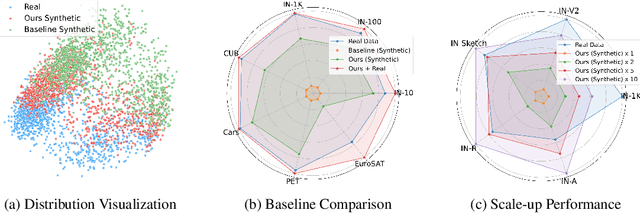
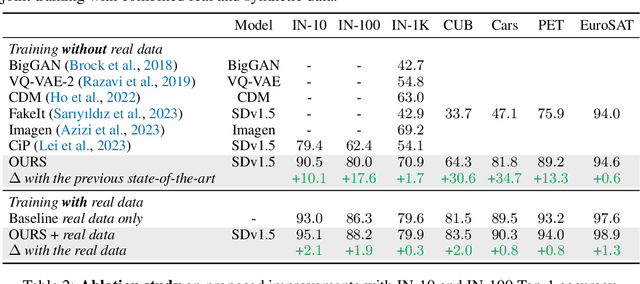
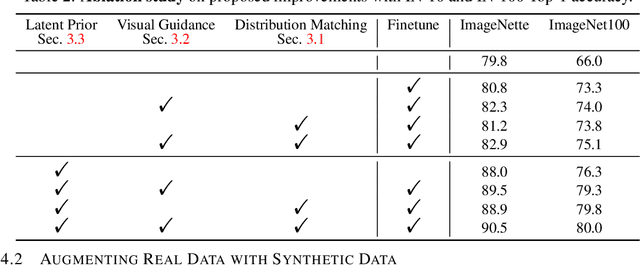
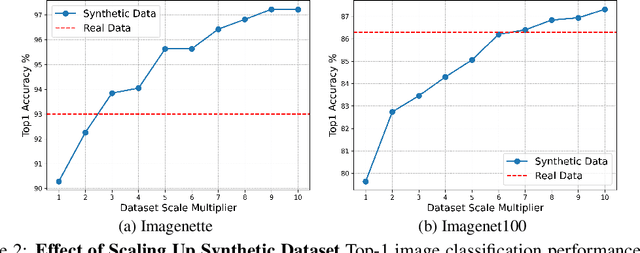
Synthetic training data has gained prominence in numerous learning tasks and scenarios, offering advantages such as dataset augmentation, generalization evaluation, and privacy preservation. Despite these benefits, the efficiency of synthetic data generated by current methodologies remains inferior when training advanced deep models exclusively, limiting its practical utility. To address this challenge, we analyze the principles underlying training data synthesis for supervised learning and elucidate a principled theoretical framework from the distribution-matching perspective that explicates the mechanisms governing synthesis efficacy. Through extensive experiments, we demonstrate the effectiveness of our synthetic data across diverse image classification tasks, both as a replacement for and augmentation to real datasets, while also benefits challenging tasks such as out-of-distribution generalization and privacy preservation.
Off the Radar: Uncertainty-Aware Radar Place Recognition with Introspective Querying and Map Maintenance
Jun 21, 2023Localisation with Frequency-Modulated Continuous-Wave (FMCW) radar has gained increasing interest due to its inherent resistance to challenging environments. However, complex artefacts of the radar measurement process require appropriate uncertainty estimation to ensure the safe and reliable application of this promising sensor modality. In this work, we propose a multi-session map management system which constructs the best maps for further localisation based on learned variance properties in an embedding space. Using the same variance properties, we also propose a new way to introspectively reject localisation queries that are likely to be incorrect. For this, we apply robust noise-aware metric learning, which both leverages the short-timescale variability of radar data along a driven path (for data augmentation) and predicts the downstream uncertainty in metric-space-based place recognition. We prove the effectiveness of our method over extensive cross-validated tests of the Oxford Radar RobotCar and MulRan dataset. In this, we outperform the current state-of-the-art in radar place recognition and other uncertainty-aware methods when using only single nearest-neighbour queries. We also show consistent performance increases when rejecting queries based on uncertainty over a difficult test environment, which we did not observe for a competing uncertainty-aware place recognition system.
* 8 pages, 6 figures
Not Just Pretty Pictures: Text-to-Image Generators Enable Interpretable Interventions for Robust Representations
Dec 21, 2022



Neural image classifiers are known to undergo severe performance degradation when exposed to input that exhibits covariate-shift with respect to the training distribution. Successful hand-crafted augmentation pipelines aim at either approximating the expected test domain conditions or to perturb the features that are specific to the training environment. The development of effective pipelines is typically cumbersome, and produce transformations whose impact on the classifier performance are hard to understand and control. In this paper, we show that recent Text-to-Image (T2I) generators' ability to simulate image interventions via natural-language prompts can be leveraged to train more robust models, offering a more interpretable and controllable alternative to traditional augmentation methods. We find that a variety of prompting mechanisms are effective for producing synthetic training data sufficient to achieve state-of-the-art performance in widely-adopted domain-generalization benchmarks and reduce classifiers' dependency on spurious features. Our work suggests that further progress in T2I generation and a tighter integration with other research fields may represent a significant step towards the development of more robust machine learning systems.