 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepurposing 2D Diffusion Models for 3D Shape Completion
Dec 16, 2025We present a framework that adapts 2D diffusion models for 3D shape completion from incomplete point clouds. While text-to-image diffusion models have achieved remarkable success with abundant 2D data, 3D diffusion models lag due to the scarcity of high-quality 3D datasets and a persistent modality gap between 3D inputs and 2D latent spaces. To overcome these limitations, we introduce the Shape Atlas, a compact 2D representation of 3D geometry that (1) enables full utilization of the generative power of pretrained 2D diffusion models, and (2) aligns the modalities between the conditional input and output spaces, allowing more effective conditioning. This unified 2D formulation facilitates learning from limited 3D data and produces high-quality, detail-preserving shape completions. We validate the effectiveness of our results on the PCN and ShapeNet-55 datasets. Additionally, we show the downstream application of creating artist-created meshes from our completed point clouds, further demonstrating the practicality of our method.
Artist-Created Mesh Generation from Raw Observation
Sep 15, 2025We present an end-to-end framework for generating artist-style meshes from noisy or incomplete point clouds, such as those captured by real-world sensors like LiDAR or mobile RGB-D cameras. Artist-created meshes are crucial for commercial graphics pipelines due to their compatibility with animation and texturing tools and their efficiency in rendering. However, existing approaches often assume clean, complete inputs or rely on complex multi-stage pipelines, limiting their applicability in real-world scenarios. To address this, we propose an end-to-end method that refines the input point cloud and directly produces high-quality, artist-style meshes. At the core of our approach is a novel reformulation of 3D point cloud refinement as a 2D inpainting task, enabling the use of powerful generative models. Preliminary results on the ShapeNet dataset demonstrate the promise of our framework in producing clean, complete meshes.
DeRIS: Decoupling Perception and Cognition for Enhanced Referring Image Segmentation through Loopback Synergy
Jul 02, 2025Referring Image Segmentation (RIS) is a challenging task that aims to segment objects in an image based on natural language expressions. While prior studies have predominantly concentrated on improving vision-language interactions and achieving fine-grained localization, a systematic analysis of the fundamental bottlenecks in existing RIS frameworks remains underexplored. To bridge this gap, we propose DeRIS, a novel framework that decomposes RIS into two key components: perception and cognition. This modular decomposition facilitates a systematic analysis of the primary bottlenecks impeding RIS performance. Our findings reveal that the predominant limitation lies not in perceptual deficiencies, but in the insufficient multi-modal cognitive capacity of current models. To mitigate this, we propose a Loopback Synergy mechanism, which enhances the synergy between the perception and cognition modules, thereby enabling precise segmentation while simultaneously improving robust image-text comprehension. Additionally, we analyze and introduce a simple non-referent sample conversion data augmentation to address the long-tail distribution issue related to target existence judgement in general scenarios. Notably, DeRIS demonstrates inherent adaptability to both non- and multi-referents scenarios without requiring specialized architectural modifications, enhancing its general applicability. The codes and models are available at https://github.com/Dmmm1997/DeRIS.
OscNet v1.5: Energy Efficient Hopfield Network on CMOS Oscillators for Image Classification
Jun 14, 2025Machine learning has achieved remarkable advancements but at the cost of significant computational resources. This has created an urgent need for a novel and energy-efficient computational fabric. CMOS Oscillator Networks (OscNet) is a brain inspired and specially designed hardware for low energy consumption. In this paper, we propose a Hopfield Network based machine learning algorithm that can be implemented on OscNet. The network is trained using forward propagation alone to learn sparsely connected weights, yet achieves an 8% improvement in accuracy compared to conventional deep learning models on MNIST dataset. OscNet v1.5 achieves competitive accuracy on MNIST and is well-suited for implementation using CMOS-compatible ring oscillator arrays with SHIL. In oscillator-based implementation, we utilize only 24% of the connections used in a fully connected Hopfield network, with merely a 0.1% drop in accuracy. OscNet v1.5 relies solely on forward propagation and employs sparse connections, making it an energy-efficient machine learning pipeline designed for CMOS oscillator computing. The repository for OscNet family is: https://github.com/RussRobin/OscNet.
STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding?
Mar 31, 2025The use of Multimodal Large Language Models (MLLMs) as an end-to-end solution for Embodied AI and Autonomous Driving has become a prevailing trend. While MLLMs have been extensively studied for visual semantic understanding tasks, their ability to perform precise and quantitative spatial-temporal understanding in real-world applications remains largely unexamined, leading to uncertain prospects. To evaluate models' Spatial-Temporal Intelligence, we introduce STI-Bench, a benchmark designed to evaluate MLLMs' spatial-temporal understanding through challenging tasks such as estimating and predicting the appearance, pose, displacement, and motion of objects. Our benchmark encompasses a wide range of robot and vehicle operations across desktop, indoor, and outdoor scenarios. The extensive experiments reveals that the state-of-the-art MLLMs still struggle in real-world spatial-temporal understanding, especially in tasks requiring precise distance estimation and motion analysis.
Precise GPS-Denied UAV Self-Positioning via Context-Enhanced Cross-View Geo-Localization
Feb 17, 2025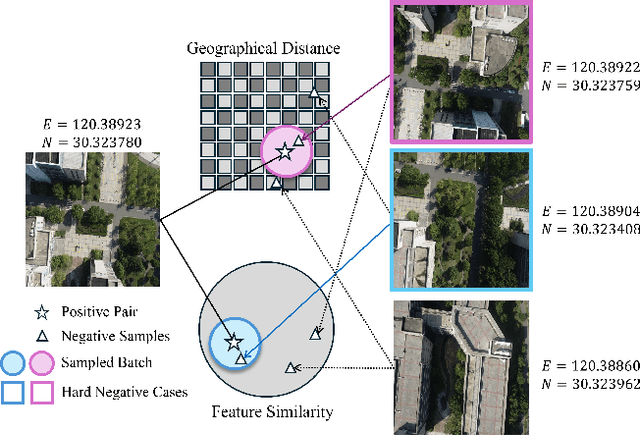
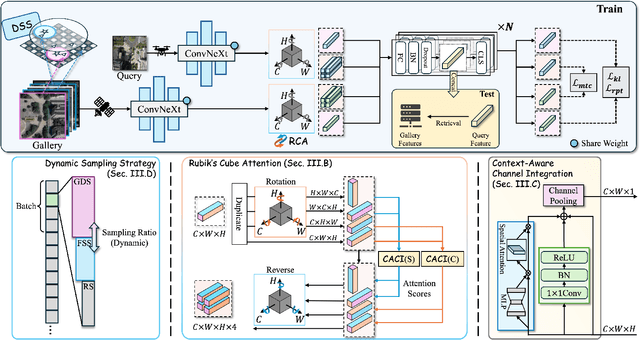

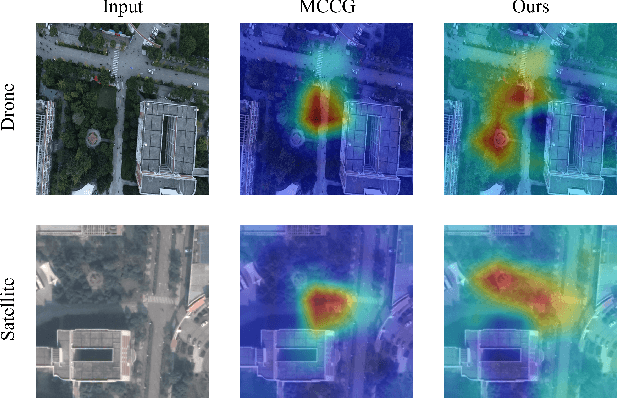
Image retrieval has been employed as a robust complementary technique to address the challenge of Unmanned Aerial Vehicles (UAVs) self-positioning. However, most existing methods primarily focus on localizing objects captured by UAVs through complex part-based representations, often overlooking the unique challenges associated with UAV self-positioning, such as fine-grained spatial discrimination requirements and dynamic scene variations. To address the above issues, we propose the Context-Enhanced method for precise UAV Self-Positioning (CEUSP), specifically designed for UAV self-positioning tasks. CEUSP integrates a Dynamic Sampling Strategy (DSS) to efficiently select optimal negative samples, while the Rubik's Cube Attention (RCA) module, combined with the Context-Aware Channel Integration (CACI) module, enhances feature representation and discrimination by exploiting interdimensional interactions, inspired by the rotational mechanics of a Rubik's Cube. Extensive experimental validate the effectiveness of the proposed method, demonstrating notable improvements in feature representation and UAV self-positioning accuracy within complex urban environments. Our approach achieves state-of-the-art performance on the DenseUAV dataset, which is specifically designed for dense urban contexts, and also delivers competitive results on the widely recognized University-1652 benchmark.
OscNet: Machine Learning on CMOS Oscillator Networks
Feb 11, 2025Machine learning and AI have achieved remarkable advancements but at the cost of significant computational resources and energy consumption. This has created an urgent need for a novel, energy-efficient computational fabric to replace the current computing pipeline. Recently, a promising approach has emerged by mimicking spiking neurons in the brain and leveraging oscillators on CMOS for direct computation. In this context, we propose a new and energy efficient machine learning framework implemented on CMOS Oscillator Networks (OscNet). We model the developmental processes of the prenatal brain's visual system using OscNet, updating weights based on the biologically inspired Hebbian rule. This same pipeline is then directly applied to standard machine learning tasks. OscNet is a specially designed hardware and is inherently energy-efficient. Its reliance on forward propagation alone for training further enhances its energy efficiency while maintaining biological plausibility. Simulation validates our designs of OscNet architectures. Experimental results demonstrate that Hebbian learning pipeline on OscNet achieves performance comparable to or even surpassing traditional machine learning algorithms, highlighting its potential as a energy efficient and effective computational paradigm.
Uncertainty Quantification in Stereo Matching
Dec 24, 2024



Stereo matching plays a crucial role in various applications, where understanding uncertainty can enhance both safety and reliability. Despite this, the estimation and analysis of uncertainty in stereo matching have been largely overlooked. Previous works often provide limited interpretations of uncertainty and struggle to separate it effectively into data (aleatoric) and model (epistemic) components. This disentanglement is essential, as it allows for a clearer understanding of the underlying sources of error, enhancing both prediction confidence and decision-making processes. In this paper, we propose a new framework for stereo matching and its uncertainty quantification. We adopt Bayes risk as a measure of uncertainty and estimate data and model uncertainty separately. Experiments are conducted on four stereo benchmarks, and the results demonstrate that our method can estimate uncertainty accurately and efficiently. Furthermore, we apply our uncertainty method to improve prediction accuracy by selecting data points with small uncertainties, which reflects the accuracy of our estimated uncertainty. The codes are publicly available at https://github.com/RussRobin/Uncertainty.
SpatialBot: Precise Spatial Understanding with Vision Language Models
Jun 19, 2024Vision Language Models (VLMs) have achieved impressive performance in 2D image understanding, however they are still struggling with spatial understanding which is the foundation of Embodied AI. In this paper, we propose SpatialBot for better spatial understanding by feeding both RGB and depth images. Additionally, we have constructed the SpatialQA dataset, which involves multi-level depth-related questions to train VLMs for depth understanding. Finally, we present SpatialBench to comprehensively evaluate VLMs' capabilities in spatial understanding at different levels. Extensive experiments on our spatial-understanding benchmark, general VLM benchmarks and Embodied AI tasks, demonstrate the remarkable improvements of SpatialBot trained on SpatialQA. The model, code and data are available at https://github.com/BAAI-DCAI/SpatialBot.
Knowledge NeRF: Few-shot Novel View Synthesis for Dynamic Articulated Objects
Apr 07, 2024



We present Knowledge NeRF to synthesize novel views for dynamic scenes. Reconstructing dynamic 3D scenes from few sparse views and rendering them from arbitrary perspectives is a challenging problem with applications in various domains. Previous dynamic NeRF methods learn the deformation of articulated objects from monocular videos. However, qualities of their reconstructed scenes are limited. To clearly reconstruct dynamic scenes, we propose a new framework by considering two frames at a time.We pretrain a NeRF model for an articulated object.When articulated objects moves, Knowledge NeRF learns to generate novel views at the new state by incorporating past knowledge in the pretrained NeRF model with minimal observations in the present state. We propose a projection module to adapt NeRF for dynamic scenes, learning the correspondence between pretrained knowledge base and current states. Experimental results demonstrate the effectiveness of our method in reconstructing dynamic 3D scenes with 5 input images in one state. Knowledge NeRF is a new pipeline and promising solution for novel view synthesis in dynamic articulated objects. The data and implementation are publicly available at https://github.com/RussRobin/Knowledge_NeRF.