 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ Cache: Visual Attention is Valuable in Less than Half of Decode Layers for Multimodal Large Language Model
Feb 02, 2026Multimodal large language models (MLLMs) are plagued by exorbitant inference costs attributable to the profusion of visual tokens within the vision encoder. The redundant visual tokens engenders a substantial computational load and key-value (KV) cache footprint bottleneck. Existing approaches focus on token-wise optimization, leveraging diverse intricate token pruning techniques to eliminate non-crucial visual tokens. Nevertheless, these methods often unavoidably undermine the integrity of the KV cache, resulting in failures in long-text generation tasks. To this end, we conduct an in-depth investigation towards the attention mechanism of the model from a new perspective, and discern that attention within more than half of all decode layers are semantic similar. Upon this finding, we contend that the attention in certain layers can be streamlined by inheriting the attention from their preceding layers. Consequently, we propose Lazy Attention, an efficient attention mechanism that enables cross-layer sharing of similar attention patterns. It ingeniously reduces layer-wise redundant computation in attention. In Lazy Attention, we develop a novel layer-shared cache, Q Cache, tailored for MLLMs, which facilitates the reuse of queries across adjacent layers. In particular, Q Cache is lightweight and fully compatible with existing inference frameworks, including Flash Attention and KV cache. Additionally, our method is highly flexible as it is orthogonal to existing token-wise techniques and can be deployed independently or combined with token pruning approaches. Empirical evaluations on multiple benchmarks demonstrate that our method can reduce KV cache usage by over 35% and achieve 1.5x throughput improvement, while sacrificing only approximately 1% of performance on various MLLMs. Compared with SOTA token-wise methods, our technique achieves superior accuracy preservation.
PropVG: End-to-End Proposal-Driven Visual Grounding with Multi-Granularity Discrimination
Sep 05, 2025Recent advances in visual grounding have largely shifted away from traditional proposal-based two-stage frameworks due to their inefficiency and high computational complexity, favoring end-to-end direct reference paradigms. However, these methods rely exclusively on the referred target for supervision, overlooking the potential benefits of prominent prospective targets. Moreover, existing approaches often fail to incorporate multi-granularity discrimination, which is crucial for robust object identification in complex scenarios. To address these limitations, we propose PropVG, an end-to-end proposal-based framework that, to the best of our knowledge, is the first to seamlessly integrate foreground object proposal generation with referential object comprehension without requiring additional detectors. Furthermore, we introduce a Contrastive-based Refer Scoring (CRS) module, which employs contrastive learning at both sentence and word levels to enhance the capability in understanding and distinguishing referred objects. Additionally, we design a Multi-granularity Target Discrimination (MTD) module that fuses object- and semantic-level information to improve the recognition of absent targets. Extensive experiments on gRefCOCO (GREC/GRES), Ref-ZOM, R-RefCOCO, and RefCOCO (REC/RES) benchmarks demonstrate the effectiveness of PropVG. The codes and models are available at https://github.com/Dmmm1997/PropVG.
DeRIS: Decoupling Perception and Cognition for Enhanced Referring Image Segmentation through Loopback Synergy
Jul 02, 2025Referring Image Segmentation (RIS) is a challenging task that aims to segment objects in an image based on natural language expressions. While prior studies have predominantly concentrated on improving vision-language interactions and achieving fine-grained localization, a systematic analysis of the fundamental bottlenecks in existing RIS frameworks remains underexplored. To bridge this gap, we propose DeRIS, a novel framework that decomposes RIS into two key components: perception and cognition. This modular decomposition facilitates a systematic analysis of the primary bottlenecks impeding RIS performance. Our findings reveal that the predominant limitation lies not in perceptual deficiencies, but in the insufficient multi-modal cognitive capacity of current models. To mitigate this, we propose a Loopback Synergy mechanism, which enhances the synergy between the perception and cognition modules, thereby enabling precise segmentation while simultaneously improving robust image-text comprehension. Additionally, we analyze and introduce a simple non-referent sample conversion data augmentation to address the long-tail distribution issue related to target existence judgement in general scenarios. Notably, DeRIS demonstrates inherent adaptability to both non- and multi-referents scenarios without requiring specialized architectural modifications, enhancing its general applicability. The codes and models are available at https://github.com/Dmmm1997/DeRIS.
Precise GPS-Denied UAV Self-Positioning via Context-Enhanced Cross-View Geo-Localization
Feb 17, 2025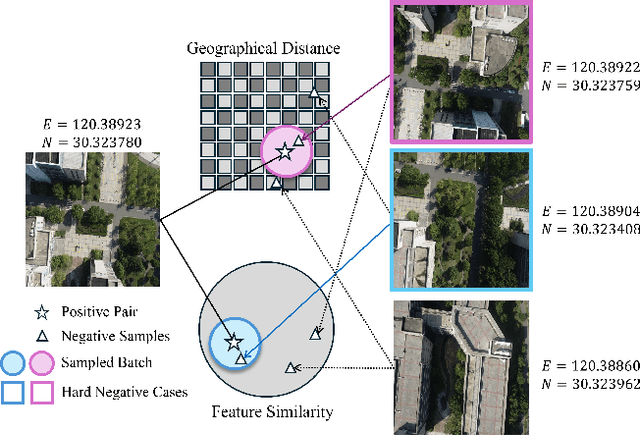
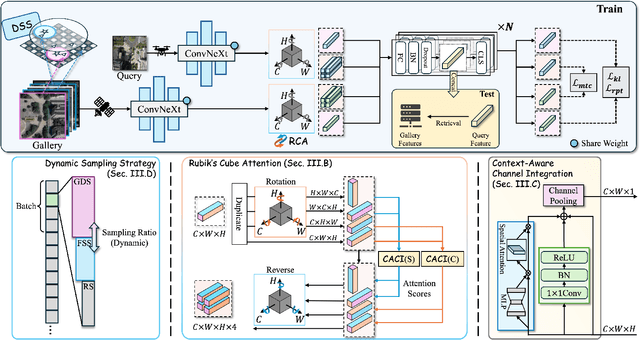

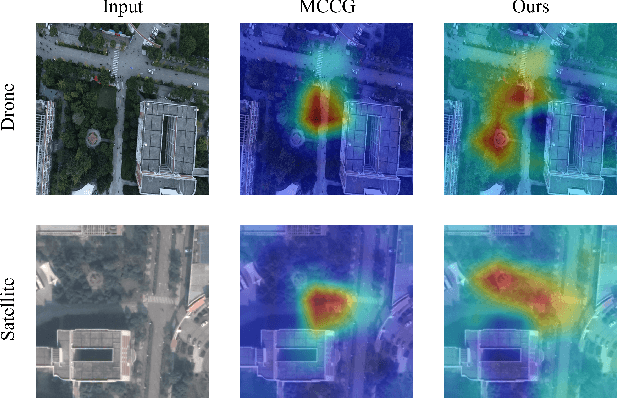
Image retrieval has been employed as a robust complementary technique to address the challenge of Unmanned Aerial Vehicles (UAVs) self-positioning. However, most existing methods primarily focus on localizing objects captured by UAVs through complex part-based representations, often overlooking the unique challenges associated with UAV self-positioning, such as fine-grained spatial discrimination requirements and dynamic scene variations. To address the above issues, we propose the Context-Enhanced method for precise UAV Self-Positioning (CEUSP), specifically designed for UAV self-positioning tasks. CEUSP integrates a Dynamic Sampling Strategy (DSS) to efficiently select optimal negative samples, while the Rubik's Cube Attention (RCA) module, combined with the Context-Aware Channel Integration (CACI) module, enhances feature representation and discrimination by exploiting interdimensional interactions, inspired by the rotational mechanics of a Rubik's Cube. Extensive experimental validate the effectiveness of the proposed method, demonstrating notable improvements in feature representation and UAV self-positioning accuracy within complex urban environments. Our approach achieves state-of-the-art performance on the DenseUAV dataset, which is specifically designed for dense urban contexts, and also delivers competitive results on the widely recognized University-1652 benchmark.
Multi-task Visual Grounding with Coarse-to-Fine Consistency Constraints
Jan 12, 2025
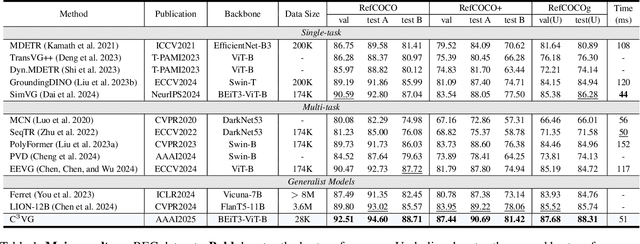

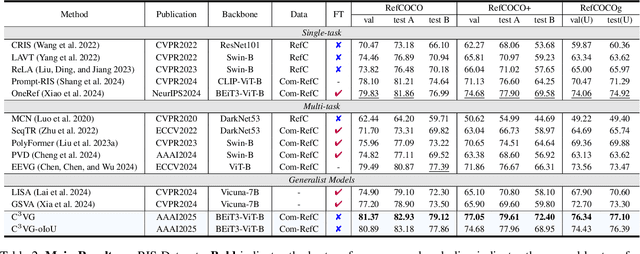
Multi-task visual grounding involves the simultaneous execution of localization and segmentation in images based on textual expressions. The majority of advanced methods predominantly focus on transformer-based multimodal fusion, aiming to extract robust multimodal representations. However, ambiguity between referring expression comprehension (REC) and referring image segmentation (RIS) is error-prone, leading to inconsistencies between multi-task predictions. Besides, insufficient multimodal understanding directly contributes to biased target perception. To overcome these challenges, we propose a Coarse-to-fine Consistency Constraints Visual Grounding architecture ($\text{C}^3\text{VG}$), which integrates implicit and explicit modeling approaches within a two-stage framework. Initially, query and pixel decoders are employed to generate preliminary detection and segmentation outputs, a process referred to as the Rough Semantic Perception (RSP) stage. These coarse predictions are subsequently refined through the proposed Mask-guided Interaction Module (MIM) and a novel explicit bidirectional consistency constraint loss to ensure consistent representations across tasks, which we term the Refined Consistency Interaction (RCI) stage. Furthermore, to address the challenge of insufficient multimodal understanding, we leverage pre-trained models based on visual-linguistic fusion representations. Empirical evaluations on the RefCOCO, RefCOCO+, and RefCOCOg datasets demonstrate the efficacy and soundness of $\text{C}^3\text{VG}$, which significantly outperforms state-of-the-art REC and RIS methods by a substantial margin. Code and model will be available at \url{https://github.com/Dmmm1997/C3VG}.
ST$^3$: Accelerating Multimodal Large Language Model by Spatial-Temporal Visual Token Trimming
Dec 28, 2024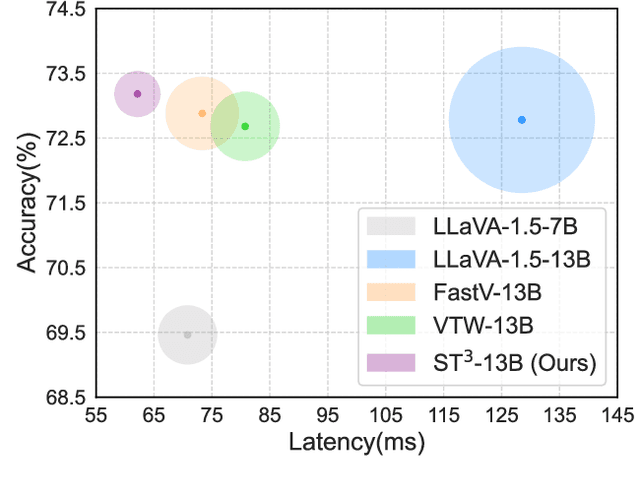



Multimodal large language models (MLLMs) enhance their perceptual capabilities by integrating visual and textual information. However, processing the massive number of visual tokens incurs a significant computational cost. Existing analysis of the MLLM attention mechanisms remains shallow, leading to coarse-grain token pruning strategies that fail to effectively balance speed and accuracy. In this paper, we conduct a comprehensive investigation of MLLM attention mechanisms with LLaVA. We find that numerous visual tokens and partial attention computations are redundant during the decoding process. Based on this insight, we propose Spatial-Temporal Visual Token Trimming ($\textbf{ST}^{3}$), a framework designed to accelerate MLLM inference without retraining. $\textbf{ST}^{3}$ consists of two primary components: 1) Progressive Visual Token Pruning (\textbf{PVTP}), which eliminates inattentive visual tokens across layers, and 2) Visual Token Annealing (\textbf{VTA}), which dynamically reduces the number of visual tokens in each layer as the generated tokens grow. Together, these techniques deliver around $\mathbf{2\times}$ faster inference with only about $\mathbf{30\%}$ KV cache memory compared to the original LLaVA, while maintaining consistent performance across various datasets. Crucially, $\textbf{ST}^{3}$ can be seamlessly integrated into existing pre-trained MLLMs, providing a plug-and-play solution for efficient inference.
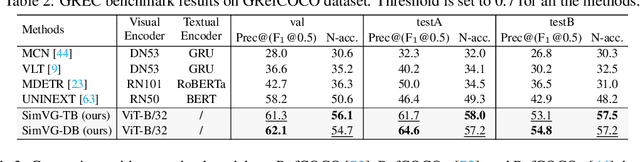
SimVG: A Simple Framework for Visual Grounding with Decoupled Multi-modal Fusion
Sep 26, 2024
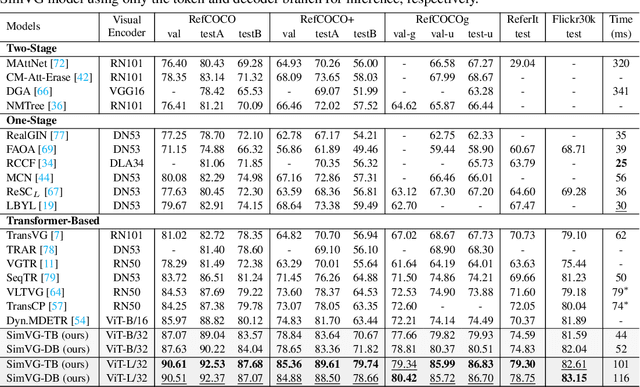
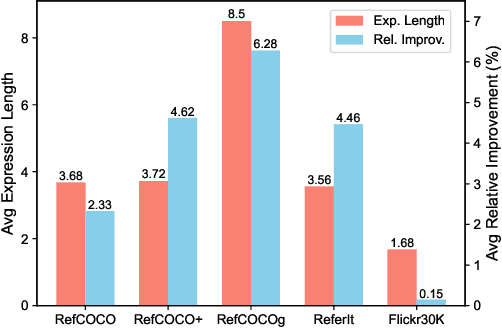
Visual grounding is a common vision task that involves grounding descriptive sentences to the corresponding regions of an image. Most existing methods use independent image-text encoding and apply complex hand-crafted modules or encoder-decoder architectures for modal interaction and query reasoning. However, their performance significantly drops when dealing with complex textual expressions. This is because the former paradigm only utilizes limited downstream data to fit the multi-modal feature fusion. Therefore, it is only effective when the textual expressions are relatively simple. In contrast, given the wide diversity of textual expressions and the uniqueness of downstream training data, the existing fusion module, which extracts multimodal content from a visual-linguistic context, has not been fully investigated. In this paper, we present a simple yet robust transformer-based framework, SimVG, for visual grounding. Specifically, we decouple visual-linguistic feature fusion from downstream tasks by leveraging existing multimodal pre-trained models and incorporating additional object tokens to facilitate deep integration of downstream and pre-training tasks. Furthermore, we design a dynamic weight-balance distillation method in the multi-branch synchronous learning process to enhance the representation capability of the simpler branch. This branch only consists of a lightweight MLP, which simplifies the structure and improves reasoning speed. Experiments on six widely used VG datasets, i.e., RefCOCO/+/g, ReferIt, Flickr30K, and GRefCOCO, demonstrate the superiority of SimVG. Finally, the proposed method not only achieves improvements in efficiency and convergence speed but also attains new state-of-the-art performance on these benchmarks. Codes and models will be available at \url{https://github.com/Dmmm1997/SimVG}.
OS-FPI: A Coarse-to-Fine One-Stream Network for UAV Geo-Localization
Mar 10, 2024The geo-localization and navigation technology of unmanned aerial vehicles (UAVs) in denied environments is currently a prominent research area. Prior approaches mainly employed a two-stream network with non-shared weights to extract features from UAV and satellite images separately, followed by related modeling to obtain the response map. However, the two-stream network extracts UAV and satellite features independently. This approach significantly affects the efficiency of feature extraction and increases the computational load. To address these issues, we propose a novel coarse-to-fine one-stream network (OS-FPI). Our approach allows information exchange between UAV and satellite features during early image feature extraction. To improve the model's performance, the framework retains feature maps generated at different stages of the feature extraction process for the feature fusion network, and establishes additional connections between UAV and satellite feature maps in the feature fusion network. Additionally, the framework introduces offset prediction to further refine and optimize the model's prediction results based on the classification tasks. Our proposed model, boasts a similar inference speed to FPI while significantly reducing the number of parameters. It can achieve better performance with fewer parameters under the same conditions. Moreover, it achieves state-of-the-art performance on the UL14 dataset. Compared to previous models, our model achieved a significant 10.92-point improvement on the RDS metric, reaching 76.25. Furthermore, its performance in meter-level localization accuracy is impressive, with 182.62% improvement in 3-meter accuracy, 164.17% improvement in 5-meter accuracy, and 137.43% improvement in 10-meter accuracy.
Finding Point with Image: An End-to-End Benchmark for Vision-based UAV Localization
Aug 13, 2022
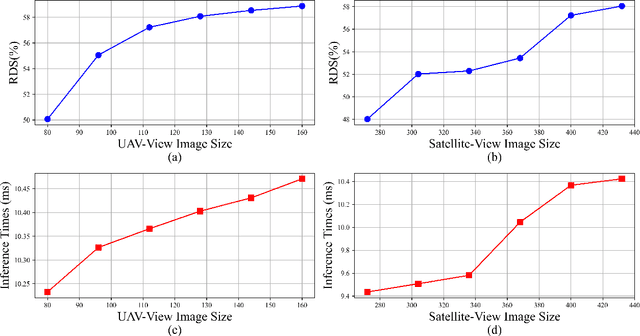
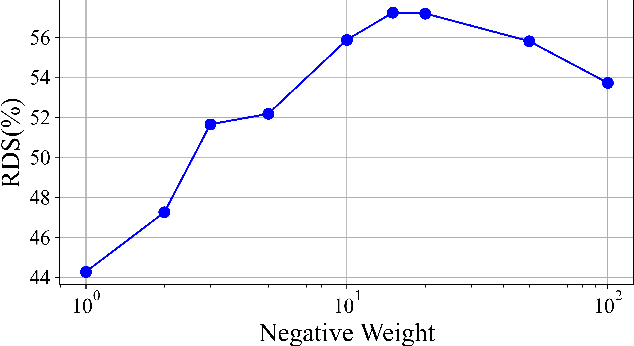
In the past, image retrieval was the mainstream solution for cross-view geolocation and UAV visual localization tasks. In a nutshell, the way of image retrieval is to obtain the final required information, such as GPS, through a transitional perspective. However, the way of image retrieval is not completely end-to-end. And there are some redundant operations such as the need to prepare the feature library in advance, and the sampling interval problem of the gallery construction, which make it difficult to implement large-scale applications. In this article we propose an end-to-end positioning scheme, Finding Point with Image (FPI), which aims to directly find the corresponding location in the image of source B (satellite-view) through the image of source A (drone-view). To verify the feasibility of our framework, we construct a new dataset (UL14), which is designed to solve the UAV visual self-localization task. At the same time, we also build a transformer-based baseline to achieve end-to-end training. In addition, the previous evaluation methods are no longer applicable under the framework of FPI. Thus, Metre-level Accuracy (MA) and Relative Distance Score (RDS) are proposed to evaluate the accuracy of UAV localization. At the same time, we preliminarily compare FPI and image retrieval method, and the structure of FPI achieves better performance in both speed and efficiency. In particular, the task of FPI remains great challenges due to the large differences between different views and the drastic spatial scale transformation.
A Transformer-Based Feature Segmentation and Region Alignment Method For UAV-View Geo-Localization
Jan 23, 2022
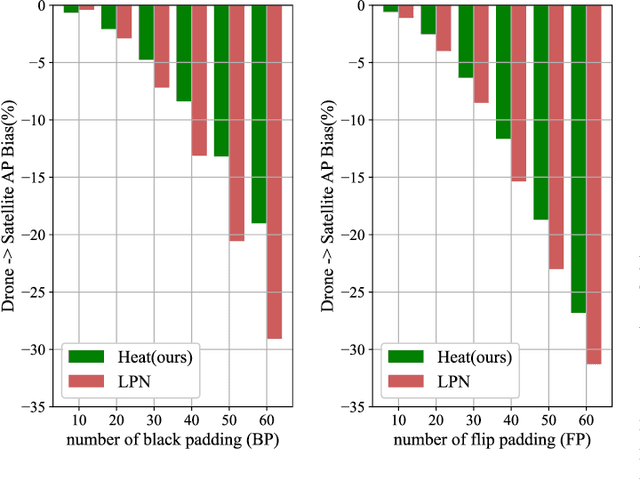
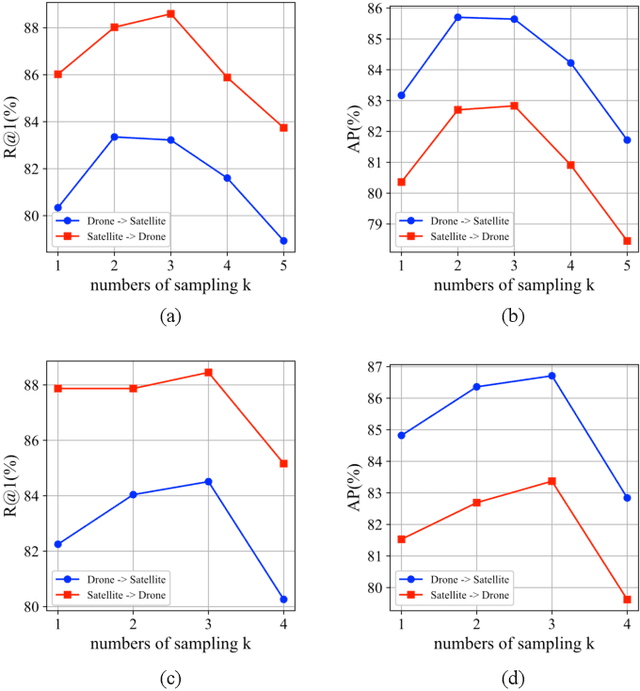
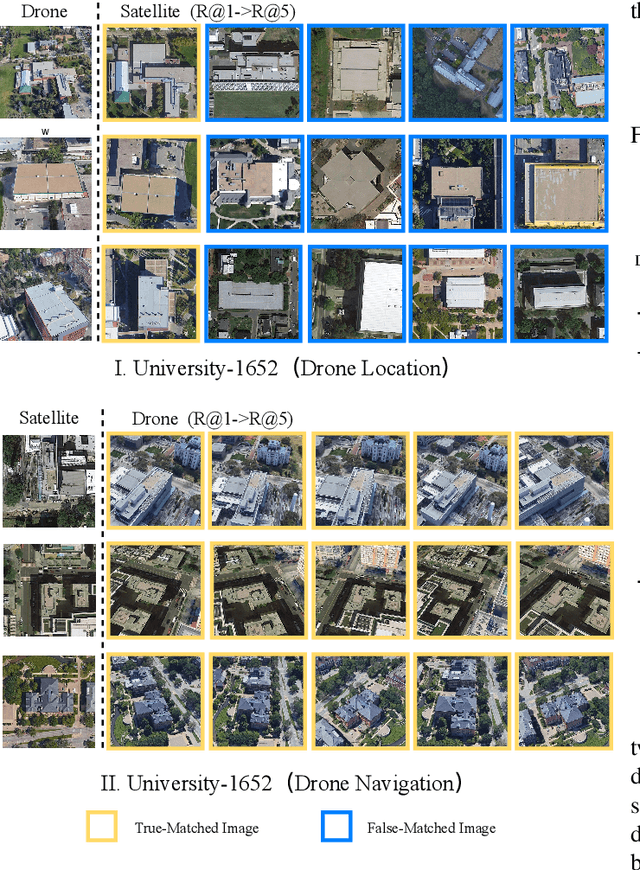
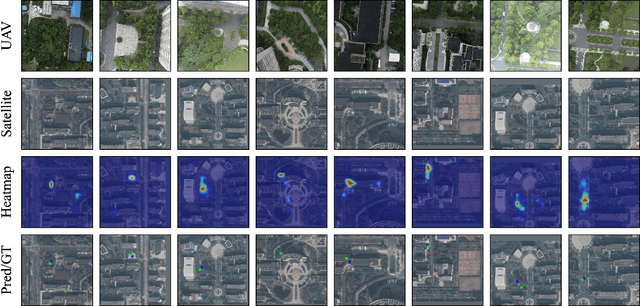
Cross-view geo-localization is a task of matching the same geographic image from different views, e.g., unmanned aerial vehicle (UAV) and satellite. The most difficult challenges are the position shift and the uncertainty of distance and scale. Existing methods are mainly aimed at digging for more comprehensive fine-grained information. However, it underestimates the importance of extracting robust feature representation and the impact of feature alignment. The CNN-based methods have achieved great success in cross-view geo-localization. However it still has some limitations, e.g., it can only extract part of the information in the neighborhood and some scale reduction operations will make some fine-grained information lost. In particular, we introduce a simple and efficient transformer-based structure called Feature Segmentation and Region Alignment (FSRA) to enhance the model's ability to understand contextual information as well as to understand the distribution of instances. Without using additional supervisory information, FSRA divides regions based on the heat distribution of the transformer's feature map, and then aligns multiple specific regions in different views one on one. Finally, FSRA integrates each region into a set of feature representations. The difference is that FSRA does not divide regions manually, but automatically based on the heat distribution of the feature map. So that specific instances can still be divided and aligned when there are significant shifts and scale changes in the image. In addition, a multiple sampling strategy is proposed to overcome the disparity in the number of satellite images and that of images from other sources. Experiments show that the proposed method has superior performance and achieves the state-of-the-art in both tasks of drone view target localization and drone navigation. Code will be released at https://github.com/Dmmm1997/FSRA