 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOS-FPI: A Coarse-to-Fine One-Stream Network for UAV Geo-Localization
Mar 10, 2024The geo-localization and navigation technology of unmanned aerial vehicles (UAVs) in denied environments is currently a prominent research area. Prior approaches mainly employed a two-stream network with non-shared weights to extract features from UAV and satellite images separately, followed by related modeling to obtain the response map. However, the two-stream network extracts UAV and satellite features independently. This approach significantly affects the efficiency of feature extraction and increases the computational load. To address these issues, we propose a novel coarse-to-fine one-stream network (OS-FPI). Our approach allows information exchange between UAV and satellite features during early image feature extraction. To improve the model's performance, the framework retains feature maps generated at different stages of the feature extraction process for the feature fusion network, and establishes additional connections between UAV and satellite feature maps in the feature fusion network. Additionally, the framework introduces offset prediction to further refine and optimize the model's prediction results based on the classification tasks. Our proposed model, boasts a similar inference speed to FPI while significantly reducing the number of parameters. It can achieve better performance with fewer parameters under the same conditions. Moreover, it achieves state-of-the-art performance on the UL14 dataset. Compared to previous models, our model achieved a significant 10.92-point improvement on the RDS metric, reaching 76.25. Furthermore, its performance in meter-level localization accuracy is impressive, with 182.62% improvement in 3-meter accuracy, 164.17% improvement in 5-meter accuracy, and 137.43% improvement in 10-meter accuracy.
PV-SSD: A Projection and Voxel-based Double Branch Single-Stage 3D Object Detector
Aug 31, 2023LIDAR-based 3D object detection and classification is crucial for autonomous driving. However, inference in real-time from extremely sparse 3D data poses a formidable challenge. To address this issue, a common approach is to project point clouds onto a bird's-eye or perspective view, effectively converting them into an image-like data format. However, this excessive compression of point cloud data often leads to the loss of information. This paper proposes a 3D object detector based on voxel and projection double branch feature extraction (PV-SSD) to address the problem of information loss. We add voxel features input containing rich local semantic information, which is fully fused with the projected features in the feature extraction stage to reduce the local information loss caused by projection. A good performance is achieved compared to the previous work. In addition, this paper makes the following contributions: 1) a voxel feature extraction method with variable receptive fields is proposed; 2) a feature point sampling method by weight sampling is used to filter out the feature points that are more conducive to the detection task; 3) the MSSFA module is proposed based on the SSFA module. To verify the effectiveness of our method, we designed comparison experiments.
Finding Point with Image: An End-to-End Benchmark for Vision-based UAV Localization
Aug 13, 2022
In the past, image retrieval was the mainstream solution for cross-view geolocation and UAV visual localization tasks. In a nutshell, the way of image retrieval is to obtain the final required information, such as GPS, through a transitional perspective. However, the way of image retrieval is not completely end-to-end. And there are some redundant operations such as the need to prepare the feature library in advance, and the sampling interval problem of the gallery construction, which make it difficult to implement large-scale applications. In this article we propose an end-to-end positioning scheme, Finding Point with Image (FPI), which aims to directly find the corresponding location in the image of source B (satellite-view) through the image of source A (drone-view). To verify the feasibility of our framework, we construct a new dataset (UL14), which is designed to solve the UAV visual self-localization task. At the same time, we also build a transformer-based baseline to achieve end-to-end training. In addition, the previous evaluation methods are no longer applicable under the framework of FPI. Thus, Metre-level Accuracy (MA) and Relative Distance Score (RDS) are proposed to evaluate the accuracy of UAV localization. At the same time, we preliminarily compare FPI and image retrieval method, and the structure of FPI achieves better performance in both speed and efficiency. In particular, the task of FPI remains great challenges due to the large differences between different views and the drastic spatial scale transformation.
A Transformer-Based Feature Segmentation and Region Alignment Method For UAV-View Geo-Localization
Jan 23, 2022
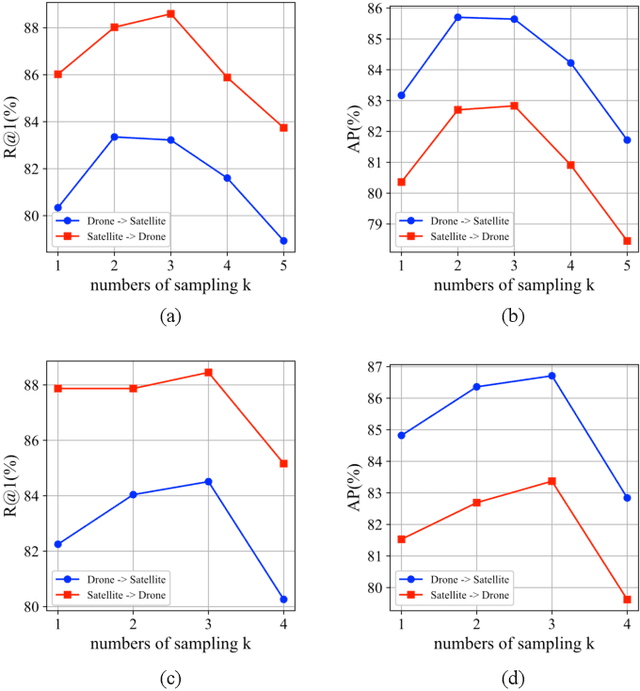
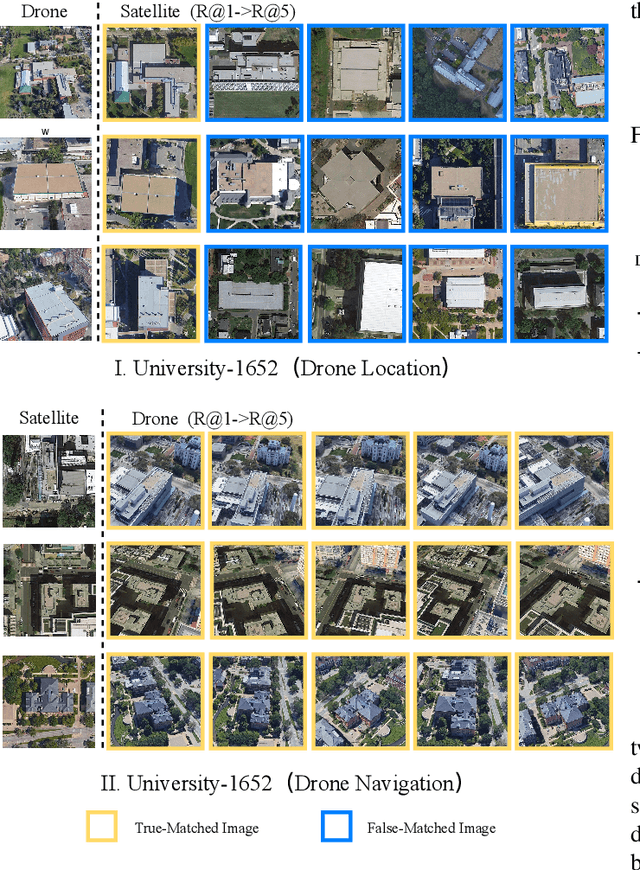
Cross-view geo-localization is a task of matching the same geographic image from different views, e.g., unmanned aerial vehicle (UAV) and satellite. The most difficult challenges are the position shift and the uncertainty of distance and scale. Existing methods are mainly aimed at digging for more comprehensive fine-grained information. However, it underestimates the importance of extracting robust feature representation and the impact of feature alignment. The CNN-based methods have achieved great success in cross-view geo-localization. However it still has some limitations, e.g., it can only extract part of the information in the neighborhood and some scale reduction operations will make some fine-grained information lost. In particular, we introduce a simple and efficient transformer-based structure called Feature Segmentation and Region Alignment (FSRA) to enhance the model's ability to understand contextual information as well as to understand the distribution of instances. Without using additional supervisory information, FSRA divides regions based on the heat distribution of the transformer's feature map, and then aligns multiple specific regions in different views one on one. Finally, FSRA integrates each region into a set of feature representations. The difference is that FSRA does not divide regions manually, but automatically based on the heat distribution of the feature map. So that specific instances can still be divided and aligned when there are significant shifts and scale changes in the image. In addition, a multiple sampling strategy is proposed to overcome the disparity in the number of satellite images and that of images from other sources. Experiments show that the proposed method has superior performance and achieves the state-of-the-art in both tasks of drone view target localization and drone navigation. Code will be released at https://github.com/Dmmm1997/FSRA
Vision-Based UAV Localization System in Denial Environments
Jan 23, 2022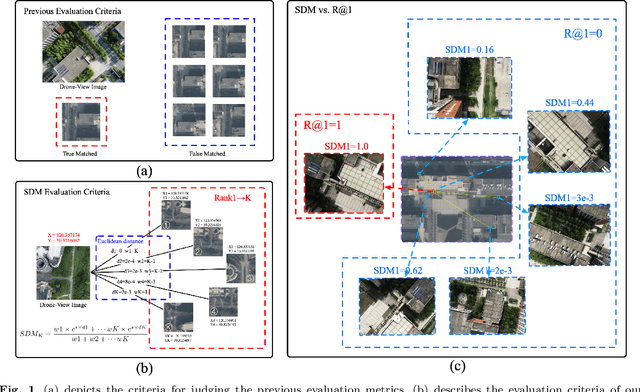

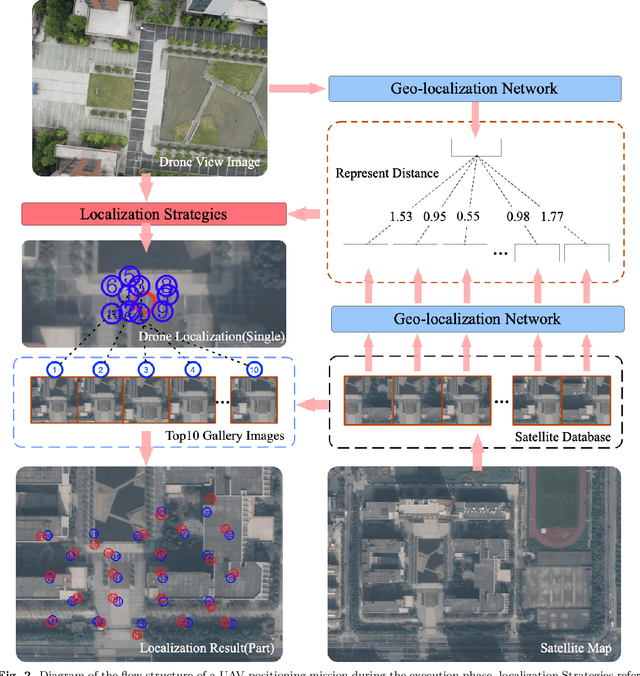
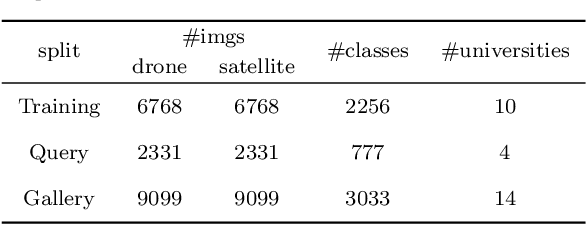
Unmanned Aerial Vehicle (UAV) localization capability is critical in a Global Navigation Satellite System (GNSS) denial environment. The aim of this paper is to investigate the problem of locating the UAV itself through a purely visual approach. This task mainly refers to: matching the corresponding geo-tagged satellite images through the images acquired by the camera when the UAV does not acquire GNSS signals, where the satellite images are the bridge between the UAV images and the location information. However, the sampling points of previous cross-view datasets based on UAVs are discrete in spatial distribution and the inter-class relationships are not established. In the actual process of UAV-localization, the inter-class feature similarity of the proximity position distribution should be small due to the continuity of UAV movement in space. In view of this, this paper has reformulated an intensive dataset for UAV positioning tasks, which is named DenseUAV, aiming to solve the problems caused by spatial distance and scale transformation in practical application scenarios, so as to achieve high-precision UAV-localization in GNSS denial environment. In addition, a new continuum-type evaluation metric named SDM is designed to evaluate the accuracy of model matching by exploiting the continuum of UAVs in space. Specifically, with the ideas of siamese networks and metric learning, a transformer-based baseline was constructed to enhance the capture of spatially subtle features. Ultimately, a neighbor-search post-processing strategy was proposed to solve the problem of large distance localisation bias.